 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvatarForcing: One-Step Streaming Talking Avatars via Local-Future Sliding-Window Denoising
Mar 15, 2026Real-time talking avatar generation requires low latency and minute-level temporal stability. Autoregressive (AR) forcing enables streaming inference but suffers from exposure bias, which causes errors to accumulate and become irreversible over long rollouts. In contrast, full-sequence diffusion transformers mitigate drift but remain computationally prohibitive for real-time long-form synthesis. We present AvatarForcing, a one-step streaming diffusion framework that denoises a fixed local-future window with heterogeneous noise levels and emits one clean block per step under constant per-step cost. To stabilize unbounded streams, the method introduces dual-anchor temporal forcing: a style anchor that re-indexes RoPE to maintain a fixed relative position with respect to the active window and applies anchor-audio zero-padding, and a temporal anchor that reuses recently emitted clean blocks to ensure smooth transitions. Real-time one-step inference is enabled by two-stage streaming distillation with offline ODE backfill and distribution matching. Experiments on standard benchmarks and a new 400-video long-form benchmark show strong visual quality and lip synchronization at 34 ms/frame using a 1.3B-parameter student model for realtime streaming. Our page is available at: https://cuiliyuan121.github.io/AvatarForcing/
DiffWind: Physics-Informed Differentiable Modeling of Wind-Driven Object Dynamics
Mar 10, 2026Modeling wind-driven object dynamics from video observations is highly challenging due to the invisibility and spatio-temporal variability of wind, as well as the complex deformations of objects. We present DiffWind, a physics-informed differentiable framework that unifies wind-object interaction modeling, video-based reconstruction, and forward simulation. Specifically, we represent wind as a grid-based physical field and objects as particle systems derived from 3D Gaussian Splatting, with their interaction modeled by the Material Point Method (MPM). To recover wind-driven object dynamics, we introduce a reconstruction framework that jointly optimizes the spatio-temporal wind force field and object motion through differentiable rendering and simulation. To ensure physical validity, we incorporate the Lattice Boltzmann Method (LBM) as a physics-informed constraint, enforcing compliance with fluid dynamics laws. Beyond reconstruction, our method naturally supports forward simulation under novel wind conditions and enables new applications such as wind retargeting. We further introduce WD-Objects, a dataset of synthetic and real-world wind-driven scenes. Extensive experiments demonstrate that our method significantly outperforms prior dynamic scene modeling approaches in both reconstruction accuracy and simulation fidelity, opening a new avenue for video-based wind-object interaction modeling.
HiScene: Creating Hierarchical 3D Scenes with Isometric View Generation
Apr 17, 2025Scene-level 3D generation represents a critical frontier in multimedia and computer graphics, yet existing approaches either suffer from limited object categories or lack editing flexibility for interactive applications. In this paper, we present HiScene, a novel hierarchical framework that bridges the gap between 2D image generation and 3D object generation and delivers high-fidelity scenes with compositional identities and aesthetic scene content. Our key insight is treating scenes as hierarchical "objects" under isometric views, where a room functions as a complex object that can be further decomposed into manipulatable items. This hierarchical approach enables us to generate 3D content that aligns with 2D representations while maintaining compositional structure. To ensure completeness and spatial alignment of each decomposed instance, we develop a video-diffusion-based amodal completion technique that effectively handles occlusions and shadows between objects, and introduce shape prior injection to ensure spatial coherence within the scene. Experimental results demonstrate that our method produces more natural object arrangements and complete object instances suitable for interactive applications, while maintaining physical plausibility and alignment with user inputs.
GURecon: Learning Detailed 3D Geometric Uncertainties for Neural Surface Reconstruction
Dec 19, 2024Neural surface representation has demonstrated remarkable success in the areas of novel view synthesis and 3D reconstruction. However, assessing the geometric quality of 3D reconstructions in the absence of ground truth mesh remains a significant challenge, due to its rendering-based optimization process and entangled learning of appearance and geometry with photometric losses. In this paper, we present a novel framework, i.e, GURecon, which establishes a geometric uncertainty field for the neural surface based on geometric consistency. Different from existing methods that rely on rendering-based measurement, GURecon models a continuous 3D uncertainty field for the reconstructed surface, and is learned by an online distillation approach without introducing real geometric information for supervision. Moreover, in order to mitigate the interference of illumination on geometric consistency, a decoupled field is learned and exploited to finetune the uncertainty field. Experiments on various datasets demonstrate the superiority of GURecon in modeling 3D geometric uncertainty, as well as its plug-and-play extension to various neural surface representations and improvement on downstream tasks such as incremental reconstruction. The code and supplementary material are available on the project website: https://zju3dv.github.io/GURecon/.
CFSynthesis: Controllable and Free-view 3D Human Video Synthesis
Dec 17, 2024



Human video synthesis aims to create lifelike characters in various environments, with wide applications in VR, storytelling, and content creation. While 2D diffusion-based methods have made significant progress, they struggle to generalize to complex 3D poses and varying scene backgrounds. To address these limitations, we introduce CFSynthesis, a novel framework for generating high-quality human videos with customizable attributes, including identity, motion, and scene configurations. Our method leverages a texture-SMPL-based representation to ensure consistent and stable character appearances across free viewpoints. Additionally, we introduce a novel foreground-background separation strategy that effectively decomposes the scene as foreground and background, enabling seamless integration of user-defined backgrounds. Experimental results on multiple datasets show that CFSynthesis not only achieves state-of-the-art performance in complex human animations but also adapts effectively to 3D motions in free-view and user-specified scenarios.
TexPro: Text-guided PBR Texturing with Procedural Material Modeling
Oct 21, 2024
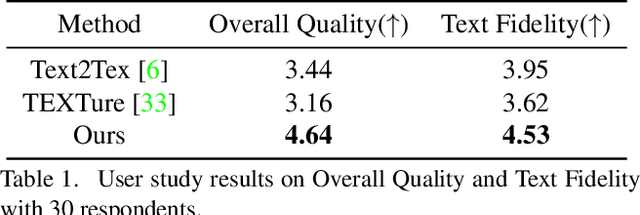
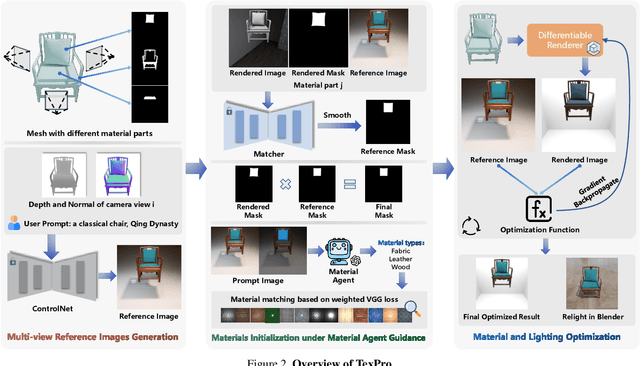
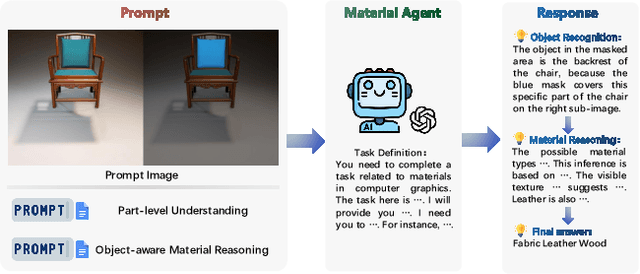
In this paper, we present TexPro, a novel method for high-fidelity material generation for input 3D meshes given text prompts. Unlike existing text-conditioned texture generation methods that typically generate RGB textures with baked lighting, TexPro is able to produce diverse texture maps via procedural material modeling, which enables physical-based rendering, relighting, and additional benefits inherent to procedural materials. Specifically, we first generate multi-view reference images given the input textual prompt by employing the latest text-to-image model. We then derive texture maps through a rendering-based optimization with recent differentiable procedural materials. To this end, we design several techniques to handle the misalignment between the generated multi-view images and 3D meshes, and introduce a novel material agent that enhances material classification and matching by exploring both part-level understanding and object-aware material reasoning. Experiments demonstrate the superiority of the proposed method over existing SOTAs and its capability of relighting.
SINE: Semantic-driven Image-based NeRF Editing with Prior-guided Editing Field
Mar 25, 2023



Despite the great success in 2D editing using user-friendly tools, such as Photoshop, semantic strokes, or even text prompts, similar capabilities in 3D areas are still limited, either relying on 3D modeling skills or allowing editing within only a few categories. In this paper, we present a novel semantic-driven NeRF editing approach, which enables users to edit a neural radiance field with a single image, and faithfully delivers edited novel views with high fidelity and multi-view consistency. To achieve this goal, we propose a prior-guided editing field to encode fine-grained geometric and texture editing in 3D space, and develop a series of techniques to aid the editing process, including cyclic constraints with a proxy mesh to facilitate geometric supervision, a color compositing mechanism to stabilize semantic-driven texture editing, and a feature-cluster-based regularization to preserve the irrelevant content unchanged. Extensive experiments and editing examples on both real-world and synthetic data demonstrate that our method achieves photo-realistic 3D editing using only a single edited image, pushing the bound of semantic-driven editing in 3D real-world scenes. Our project webpage: https://zju3dv.github.io/sine/.