 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianUpdate: Continual 3D Gaussian Splatting Update for Changing Environments
Aug 12, 2025Novel view synthesis with neural models has advanced rapidly in recent years, yet adapting these models to scene changes remains an open problem. Existing methods are either labor-intensive, requiring extensive model retraining, or fail to capture detailed types of changes over time. In this paper, we present GaussianUpdate, a novel approach that combines 3D Gaussian representation with continual learning to address these challenges. Our method effectively updates the Gaussian radiance fields with current data while preserving information from past scenes. Unlike existing methods, GaussianUpdate explicitly models different types of changes through a novel multi-stage update strategy. Additionally, we introduce a visibility-aware continual learning approach with generative replay, enabling self-aware updating without the need to store images. The experiments on the benchmark dataset demonstrate our method achieves superior and real-time rendering with the capability of visualizing changes over different times
NeuraLoc: Visual Localization in Neural Implicit Map with Dual Complementary Features
Mar 08, 2025Recently, neural radiance fields (NeRF) have gained significant attention in the field of visual localization. However, existing NeRF-based approaches either lack geometric constraints or require extensive storage for feature matching, limiting their practical applications. To address these challenges, we propose an efficient and novel visual localization approach based on the neural implicit map with complementary features. Specifically, to enforce geometric constraints and reduce storage requirements, we implicitly learn a 3D keypoint descriptor field, avoiding the need to explicitly store point-wise features. To further address the semantic ambiguity of descriptors, we introduce additional semantic contextual feature fields, which enhance the quality and reliability of 2D-3D correspondences. Besides, we propose descriptor similarity distribution alignment to minimize the domain gap between 2D and 3D feature spaces during matching. Finally, we construct the matching graph using both complementary descriptors and contextual features to establish accurate 2D-3D correspondences for 6-DoF pose estimation. Compared with the recent NeRF-based approaches, our method achieves a 3$\times$ faster training speed and a 45$\times$ reduction in model storage. Extensive experiments on two widely used datasets demonstrate that our approach outperforms or is highly competitive with other state-of-the-art NeRF-based visual localization methods. Project page: \href{https://zju3dv.github.io/neuraloc}{https://zju3dv.github.io/neuraloc}
GURecon: Learning Detailed 3D Geometric Uncertainties for Neural Surface Reconstruction
Dec 19, 2024Neural surface representation has demonstrated remarkable success in the areas of novel view synthesis and 3D reconstruction. However, assessing the geometric quality of 3D reconstructions in the absence of ground truth mesh remains a significant challenge, due to its rendering-based optimization process and entangled learning of appearance and geometry with photometric losses. In this paper, we present a novel framework, i.e, GURecon, which establishes a geometric uncertainty field for the neural surface based on geometric consistency. Different from existing methods that rely on rendering-based measurement, GURecon models a continuous 3D uncertainty field for the reconstructed surface, and is learned by an online distillation approach without introducing real geometric information for supervision. Moreover, in order to mitigate the interference of illumination on geometric consistency, a decoupled field is learned and exploited to finetune the uncertainty field. Experiments on various datasets demonstrate the superiority of GURecon in modeling 3D geometric uncertainty, as well as its plug-and-play extension to various neural surface representations and improvement on downstream tasks such as incremental reconstruction. The code and supplementary material are available on the project website: https://zju3dv.github.io/GURecon/.
SplatLoc: 3D Gaussian Splatting-based Visual Localization for Augmented Reality
Sep 21, 2024



Visual localization plays an important role in the applications of Augmented Reality (AR), which enable AR devices to obtain their 6-DoF pose in the pre-build map in order to render virtual content in real scenes. However, most existing approaches can not perform novel view rendering and require large storage capacities for maps. To overcome these limitations, we propose an efficient visual localization method capable of high-quality rendering with fewer parameters. Specifically, our approach leverages 3D Gaussian primitives as the scene representation. To ensure precise 2D-3D correspondences for pose estimation, we develop an unbiased 3D scene-specific descriptor decoder for Gaussian primitives, distilled from a constructed feature volume. Additionally, we introduce a salient 3D landmark selection algorithm that selects a suitable primitive subset based on the saliency score for localization. We further regularize key Gaussian primitives to prevent anisotropic effects, which also improves localization performance. Extensive experiments on two widely used datasets demonstrate that our method achieves superior or comparable rendering and localization performance to state-of-the-art implicit-based visual localization approaches. Project page: \href{https://zju3dv.github.io/splatloc}{https://zju3dv.github.io/splatloc}.
MoManifold: Learning to Measure 3D Human Motion via Decoupled Joint Acceleration Manifolds
Sep 01, 2024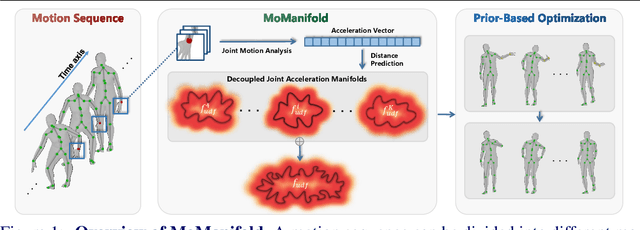
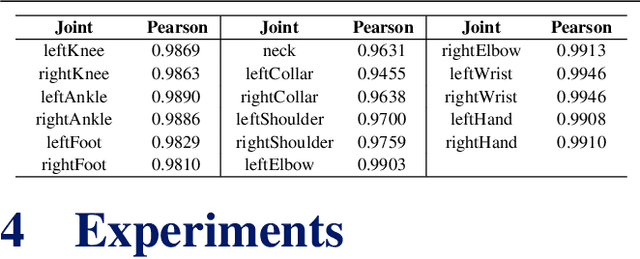


Incorporating temporal information effectively is important for accurate 3D human motion estimation and generation which have wide applications from human-computer interaction to AR/VR. In this paper, we present MoManifold, a novel human motion prior, which models plausible human motion in continuous high-dimensional motion space. Different from existing mathematical or VAE-based methods, our representation is designed based on the neural distance field, which makes human dynamics explicitly quantified to a score and thus can measure human motion plausibility. Specifically, we propose novel decoupled joint acceleration manifolds to model human dynamics from existing limited motion data. Moreover, we introduce a novel optimization method using the manifold distance as guidance, which facilitates a variety of motion-related tasks. Extensive experiments demonstrate that MoManifold outperforms existing SOTAs as a prior in several downstream tasks such as denoising real-world human mocap data, recovering human motion from partial 3D observations, mitigating jitters for SMPL-based pose estimators, and refining the results of motion in-betweening.
GaussianPrediction: Dynamic 3D Gaussian Prediction for Motion Extrapolation and Free View Synthesis
May 30, 2024



Forecasting future scenarios in dynamic environments is essential for intelligent decision-making and navigation, a challenge yet to be fully realized in computer vision and robotics. Traditional approaches like video prediction and novel-view synthesis either lack the ability to forecast from arbitrary viewpoints or to predict temporal dynamics. In this paper, we introduce GaussianPrediction, a novel framework that empowers 3D Gaussian representations with dynamic scene modeling and future scenario synthesis in dynamic environments. GaussianPrediction can forecast future states from any viewpoint, using video observations of dynamic scenes. To this end, we first propose a 3D Gaussian canonical space with deformation modeling to capture the appearance and geometry of dynamic scenes, and integrate the lifecycle property into Gaussians for irreversible deformations. To make the prediction feasible and efficient, a concentric motion distillation approach is developed by distilling the scene motion with key points. Finally, a Graph Convolutional Network is employed to predict the motions of key points, enabling the rendering of photorealistic images of future scenarios. Our framework shows outstanding performance on both synthetic and real-world datasets, demonstrating its efficacy in predicting and rendering future environments.
PNeRFLoc: Visual Localization with Point-based Neural Radiance Fields
Dec 17, 2023
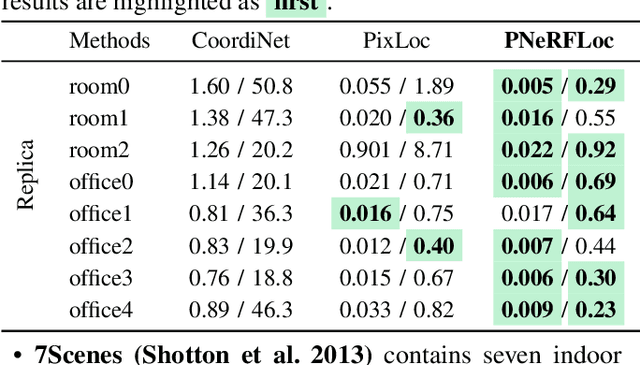

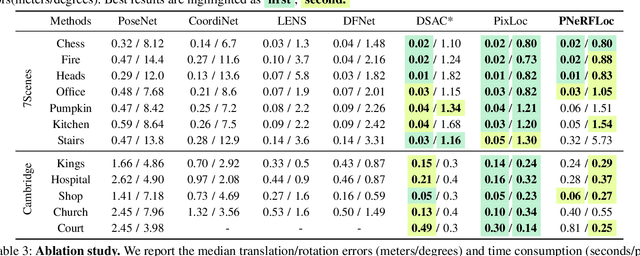
Due to the ability to synthesize high-quality novel views, Neural Radiance Fields (NeRF) have been recently exploited to improve visual localization in a known environment. However, the existing methods mostly utilize NeRFs for data augmentation to improve the regression model training, and the performance on novel viewpoints and appearances is still limited due to the lack of geometric constraints. In this paper, we propose a novel visual localization framework, \ie, PNeRFLoc, based on a unified point-based representation. On the one hand, PNeRFLoc supports the initial pose estimation by matching 2D and 3D feature points as traditional structure-based methods; on the other hand, it also enables pose refinement with novel view synthesis using rendering-based optimization. Specifically, we propose a novel feature adaption module to close the gaps between the features for visual localization and neural rendering. To improve the efficacy and efficiency of neural rendering-based optimization, we also develop an efficient rendering-based framework with a warping loss function. Furthermore, several robustness techniques are developed to handle illumination changes and dynamic objects for outdoor scenarios. Experiments demonstrate that PNeRFLoc performs the best on synthetic data when the NeRF model can be well learned and performs on par with the SOTA method on the visual localization benchmark datasets.
Factorized and Controllable Neural Re-Rendering of Outdoor Scene for Photo Extrapolation
Jul 14, 2022



Expanding an existing tourist photo from a partially captured scene to a full scene is one of the desired experiences for photography applications. Although photo extrapolation has been well studied, it is much more challenging to extrapolate a photo (i.e., selfie) from a narrow field of view to a wider one while maintaining a similar visual style. In this paper, we propose a factorized neural re-rendering model to produce photorealistic novel views from cluttered outdoor Internet photo collections, which enables the applications including controllable scene re-rendering, photo extrapolation and even extrapolated 3D photo generation. Specifically, we first develop a novel factorized re-rendering pipeline to handle the ambiguity in the decomposition of geometry, appearance and illumination. We also propose a composited training strategy to tackle the unexpected occlusion in Internet images. Moreover, to enhance photo-realism when extrapolating tourist photographs, we propose a novel realism augmentation process to complement appearance details, which automatically propagates the texture details from a narrow captured photo to the extrapolated neural rendered image. The experiments and photo editing examples on outdoor scenes demonstrate the superior performance of our proposed method in both photo-realism and downstream applications.