 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRE: Encouraging Exploration in the Trust Region
Feb 03, 2026Entropy regularization is a standard technique in reinforcement learning (RL) to enhance exploration, yet it yields negligible effects or even degrades performance in Large Language Models (LLMs). We attribute this failure to the cumulative tail risk inherent to LLMs with massive vocabularies and long generation horizons. In such environments, standard global entropy maximization indiscriminately dilutes probability mass into the vast tail of invalid tokens rather than focusing on plausible candidates, thereby disrupting coherent reasoning. To address this, we propose Trust Region Entropy (TRE), a method that encourages exploration strictly within the model's trust region. Extensive experiments across mathematical reasoning (MATH), combinatorial search (Countdown), and preference alignment (HH) tasks demonstrate that TRE consistently outperforms vanilla PPO, standard entropy regularization, and other exploration baselines. Our code is available at https://github.com/WhyChaos/TRE-Encouraging-Exploration-in-the-Trust-Region.
Beyond Monolithic Architectures: A Multi-Agent Search and Knowledge Optimization Framework for Agentic Search
Jan 08, 2026Agentic search has emerged as a promising paradigm for complex information seeking by enabling Large Language Models (LLMs) to interleave reasoning with tool use. However, prevailing systems rely on monolithic agents that suffer from structural bottlenecks, including unconstrained reasoning outputs that inflate trajectories, sparse outcome-level rewards that complicate credit assignment, and stochastic search noise that destabilizes learning. To address these challenges, we propose \textbf{M-ASK} (Multi-Agent Search and Knowledge), a framework that explicitly decouples agentic search into two complementary roles: Search Behavior Agents, which plan and execute search actions, and Knowledge Management Agents, which aggregate, filter, and maintain a compact internal context. This decomposition allows each agent to focus on a well-defined subtask and reduces interference between search and context construction. Furthermore, to enable stable coordination, M-ASK employs turn-level rewards to provide granular supervision for both search decisions and knowledge updates. Experiments on multi-hop QA benchmarks demonstrate that M-ASK outperforms strong baselines, achieving not only superior answer accuracy but also significantly more stable training dynamics.\footnote{The source code for M-ASK is available at https://github.com/chenyiqun/M-ASK.}
TURA: Tool-Augmented Unified Retrieval Agent for AI Search
Aug 06, 2025The advent of Large Language Models (LLMs) is transforming search engines into conversational AI search products, primarily using Retrieval-Augmented Generation (RAG) on web corpora. However, this paradigm has significant industrial limitations. Traditional RAG approaches struggle with real-time needs and structured queries that require accessing dynamically generated content like ticket availability or inventory. Limited to indexing static pages, search engines cannot perform the interactive queries needed for such time-sensitive data. Academic research has focused on optimizing RAG for static content, overlooking complex intents and the need for dynamic sources like databases and real-time APIs. To bridge this gap, we introduce TURA (Tool-Augmented Unified Retrieval Agent for AI Search), a novel three-stage framework that combines RAG with agentic tool-use to access both static content and dynamic, real-time information. TURA has three key components: an Intent-Aware Retrieval module to decompose queries and retrieve information sources encapsulated as Model Context Protocol (MCP) Servers, a DAG-based Task Planner that models task dependencies as a Directed Acyclic Graph (DAG) for optimal parallel execution, and a lightweight Distilled Agent Executor for efficient tool calling. TURA is the first architecture to systematically bridge the gap between static RAG and dynamic information sources for a world-class AI search product. Serving tens of millions of users, it leverages an agentic framework to deliver robust, real-time answers while meeting the low-latency demands of a large-scale industrial system.
Graph Foundation Models for Recommendation: A Comprehensive Survey
Feb 12, 2025



Recommender systems (RS) serve as a fundamental tool for navigating the vast expanse of online information, with deep learning advancements playing an increasingly important role in improving ranking accuracy. Among these, graph neural networks (GNNs) excel at extracting higher-order structural information, while large language models (LLMs) are designed to process and comprehend natural language, making both approaches highly effective and widely adopted. Recent research has focused on graph foundation models (GFMs), which integrate the strengths of GNNs and LLMs to model complex RS problems more efficiently by leveraging the graph-based structure of user-item relationships alongside textual understanding. In this survey, we provide a comprehensive overview of GFM-based RS technologies by introducing a clear taxonomy of current approaches, diving into methodological details, and highlighting key challenges and future directions. By synthesizing recent advancements, we aim to offer valuable insights into the evolving landscape of GFM-based recommender systems.
GenCRF: Generative Clustering and Reformulation Framework for Enhanced Intent-Driven Information Retrieval
Sep 17, 2024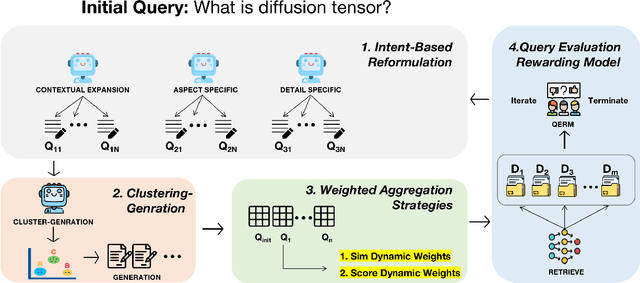
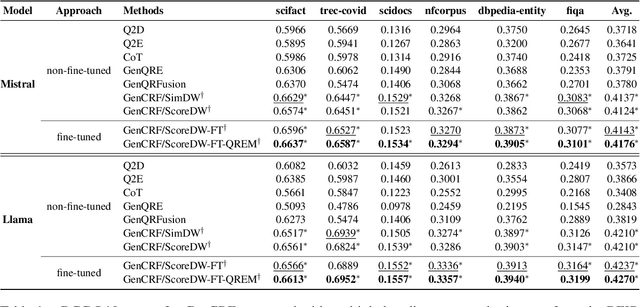
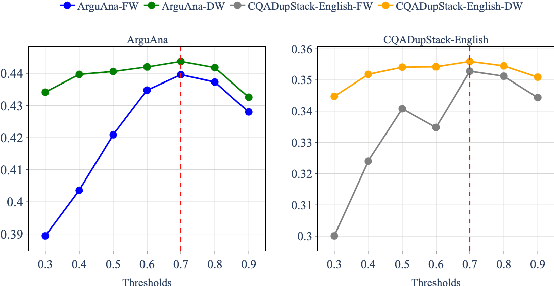
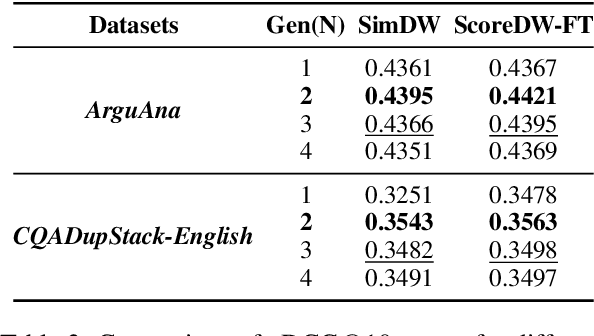
Query reformulation is a well-known problem in Information Retrieval (IR) aimed at enhancing single search successful completion rate by automatically modifying user's input query. Recent methods leverage Large Language Models (LLMs) to improve query reformulation, but often generate limited and redundant expansions, potentially constraining their effectiveness in capturing diverse intents. In this paper, we propose GenCRF: a Generative Clustering and Reformulation Framework to capture diverse intentions adaptively based on multiple differentiated, well-generated queries in the retrieval phase for the first time. GenCRF leverages LLMs to generate variable queries from the initial query using customized prompts, then clusters them into groups to distinctly represent diverse intents. Furthermore, the framework explores to combine diverse intents query with innovative weighted aggregation strategies to optimize retrieval performance and crucially integrates a novel Query Evaluation Rewarding Model (QERM) to refine the process through feedback loops. Empirical experiments on the BEIR benchmark demonstrate that GenCRF achieves state-of-the-art performance, surpassing previous query reformulation SOTAs by up to 12% on nDCG@10. These techniques can be adapted to various LLMs, significantly boosting retriever performance and advancing the field of Information Retrieval.
Text-Video Retrieval via Variational Multi-Modal Hypergraph Networks
Jan 06, 2024Text-video retrieval is a challenging task that aims to identify relevant videos given textual queries. Compared to conventional textual retrieval, the main obstacle for text-video retrieval is the semantic gap between the textual nature of queries and the visual richness of video content. Previous works primarily focus on aligning the query and the video by finely aggregating word-frame matching signals. Inspired by the human cognitive process of modularly judging the relevance between text and video, the judgment needs high-order matching signal due to the consecutive and complex nature of video contents. In this paper, we propose chunk-level text-video matching, where the query chunks are extracted to describe a specific retrieval unit, and the video chunks are segmented into distinct clips from videos. We formulate the chunk-level matching as n-ary correlations modeling between words of the query and frames of the video and introduce a multi-modal hypergraph for n-ary correlation modeling. By representing textual units and video frames as nodes and using hyperedges to depict their relationships, a multi-modal hypergraph is constructed. In this way, the query and the video can be aligned in a high-order semantic space. In addition, to enhance the model's generalization ability, the extracted features are fed into a variational inference component for computation, obtaining the variational representation under the Gaussian distribution. The incorporation of hypergraphs and variational inference allows our model to capture complex, n-ary interactions among textual and visual contents. Experimental results demonstrate that our proposed method achieves state-of-the-art performance on the text-video retrieval task.
Disentangled Contrastive Collaborative Filtering
May 07, 2023


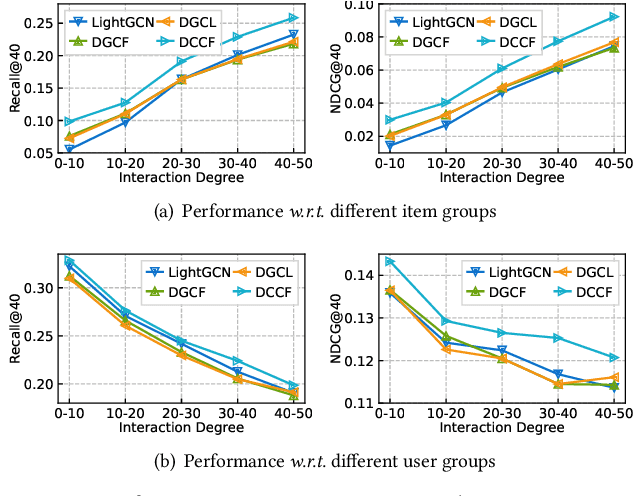
Recent studies show that graph neural networks (GNNs) are prevalent to model high-order relationships for collaborative filtering (CF). Towards this research line, graph contrastive learning (GCL) has exhibited powerful performance in addressing the supervision label shortage issue by learning augmented user and item representations. While many of them show their effectiveness, two key questions still remain unexplored: i) Most existing GCL-based CF models are still limited by ignoring the fact that user-item interaction behaviors are often driven by diverse latent intent factors (e.g., shopping for family party, preferred color or brand of products); ii) Their introduced non-adaptive augmentation techniques are vulnerable to noisy information, which raises concerns about the model's robustness and the risk of incorporating misleading self-supervised signals. In light of these limitations, we propose a Disentangled Contrastive Collaborative Filtering framework (DCCF) to realize intent disentanglement with self-supervised augmentation in an adaptive fashion. With the learned disentangled representations with global context, our DCCF is able to not only distill finer-grained latent factors from the entangled self-supervision signals but also alleviate the augmentation-induced noise. Finally, the cross-view contrastive learning task is introduced to enable adaptive augmentation with our parameterized interaction mask generator. Experiments on various public datasets demonstrate the superiority of our method compared to existing solutions. Our model implementation is released at the link https://github.com/HKUDS/DCCF.
Whole Page Unbiased Learning to Rank
Oct 19, 2022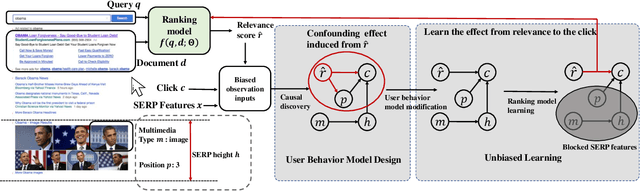
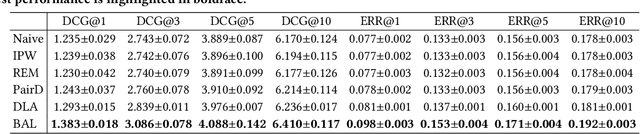
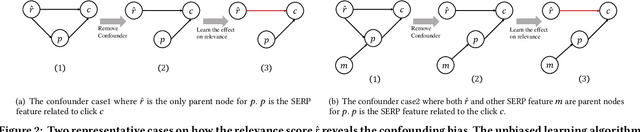
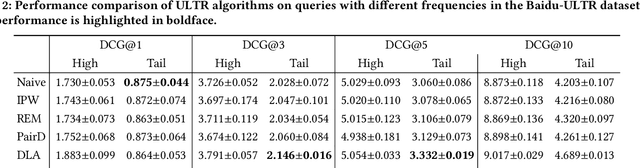
The page presentation biases in the information retrieval system, especially on the click behavior, is a well-known challenge that hinders improving ranking models' performance with implicit user feedback. Unbiased Learning to Rank~(ULTR) algorithms are then proposed to learn an unbiased ranking model with biased click data. However, most existing algorithms are specifically designed to mitigate position-related bias, e.g., trust bias, without considering biases induced by other features in search result page presentation(SERP). For example, the multimedia type may generate attractive bias. Unfortunately, those biases widely exist in industrial systems and may lead to an unsatisfactory search experience. Therefore, we introduce a new problem, i.e., whole-page Unbiased Learning to Rank(WP-ULTR), aiming to handle biases induced by whole-page SERP features simultaneously. It presents tremendous challenges. For example, a suitable user behavior model (user behavior hypothesis) can be hard to find; and complex biases cannot be handled by existing algorithms. To address the above challenges, we propose a Bias Agnostic whole-page unbiased Learning to rank algorithm, BAL, to automatically discover and mitigate the biases from multiple SERP features with no specific design. Experimental results on a real-world dataset verify the effectiveness of the BAL.
Factorized and Controllable Neural Re-Rendering of Outdoor Scene for Photo Extrapolation
Jul 14, 2022



Expanding an existing tourist photo from a partially captured scene to a full scene is one of the desired experiences for photography applications. Although photo extrapolation has been well studied, it is much more challenging to extrapolate a photo (i.e., selfie) from a narrow field of view to a wider one while maintaining a similar visual style. In this paper, we propose a factorized neural re-rendering model to produce photorealistic novel views from cluttered outdoor Internet photo collections, which enables the applications including controllable scene re-rendering, photo extrapolation and even extrapolated 3D photo generation. Specifically, we first develop a novel factorized re-rendering pipeline to handle the ambiguity in the decomposition of geometry, appearance and illumination. We also propose a composited training strategy to tackle the unexpected occlusion in Internet images. Moreover, to enhance photo-realism when extrapolating tourist photographs, we propose a novel realism augmentation process to complement appearance details, which automatically propagates the texture details from a narrow captured photo to the extrapolated neural rendered image. The experiments and photo editing examples on outdoor scenes demonstrate the superior performance of our proposed method in both photo-realism and downstream applications.
Hypergraph Contrastive Collaborative Filtering
Apr 27, 2022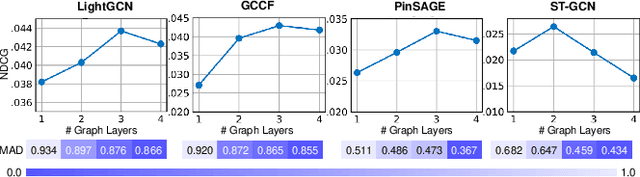

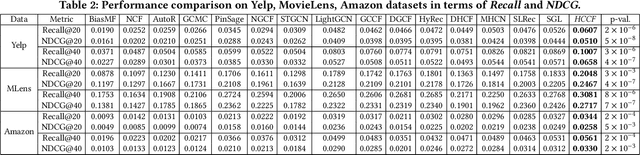
Collaborative Filtering (CF) has emerged as fundamental paradigms for parameterizing users and items into latent representation space, with their correlative patterns from interaction data. Among various CF techniques, the development of GNN-based recommender systems, e.g., PinSage and LightGCN, has offered the state-of-the-art performance. However, two key challenges have not been well explored in existing solutions: i) The over-smoothing effect with deeper graph-based CF architecture, may cause the indistinguishable user representations and degradation of recommendation results. ii) The supervision signals (i.e., user-item interactions) are usually scarce and skewed distributed in reality, which limits the representation power of CF paradigms. To tackle these challenges, we propose a new self-supervised recommendation framework Hypergraph Contrastive Collaborative Filtering (HCCF) to jointly capture local and global collaborative relations with a hypergraph-enhanced cross-view contrastive learning architecture. In particular, the designed hypergraph structure learning enhances the discrimination ability of GNN-based CF paradigm, so as to comprehensively capture the complex high-order dependencies among users. Additionally, our HCCF model effectively integrates the hypergraph structure encoding with self-supervised learning to reinforce the representation quality of recommender systems, based on the hypergraph-enhanced self-discrimination. Extensive experiments on three benchmark datasets demonstrate the superiority of our model over various state-of-the-art recommendation methods, and the robustness against sparse user interaction data. Our model implementation codes are available at https://github.com/akaxlh/HCCF.