 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAesRec: A Dataset for Aesthetics-Aligned Clothing Outfit Recommendation
Feb 03, 2026Clothing recommendation extends beyond merely generating personalized outfits; it serves as a crucial medium for aesthetic guidance. However, existing methods predominantly rely on user-item-outfit interaction behaviors while overlooking explicit representations of clothing aesthetics. To bridge this gap, we present the AesRec benchmark dataset featuring systematic quantitative aesthetic annotations, thereby enabling the development of aesthetics-aligned recommendation systems. Grounded in professional apparel quality standards and fashion aesthetic principles, we define a multidimensional set of indicators. At the item level, six dimensions are independently assessed: silhouette, chromaticity, materiality, craftsmanship, wearability, and item-level impression. Transitioning to the outfit level, the evaluation retains the first five core attributes while introducing stylistic synergy, visual harmony, and outfit-level impression as distinct metrics to capture the collective aesthetic impact. Given the increasing human-like proficiency of Vision-Language Models in multimodal understanding and interaction, we leverage them for large-scale aesthetic scoring. We conduct rigorous human-machine consistency validation on a fashion dataset, confirming the reliability of the generated ratings. Experimental results based on AesRec further demonstrate that integrating quantified aesthetic information into clothing recommendation models can provide aesthetic guidance for users while fulfilling their personalized requirements.
Evolution of ReID: From Early Methods to LLM Integration
Jun 16, 2025



Person re-identification (ReID) has evolved from handcrafted feature-based methods to deep learning approaches and, more recently, to models incorporating large language models (LLMs). Early methods struggled with variations in lighting, pose, and viewpoint, but deep learning addressed these issues by learning robust visual features. Building on this, LLMs now enable ReID systems to integrate semantic and contextual information through natural language. This survey traces that full evolution and offers one of the first comprehensive reviews of ReID approaches that leverage LLMs, where textual descriptions are used as privileged information to improve visual matching. A key contribution is the use of dynamic, identity-specific prompts generated by GPT-4o, which enhance the alignment between images and text in vision-language ReID systems. Experimental results show that these descriptions improve accuracy, especially in complex or ambiguous cases. To support further research, we release a large set of GPT-4o-generated descriptions for standard ReID datasets. By bridging computer vision and natural language processing, this survey offers a unified perspective on the field's development and outlines key future directions such as better prompt design, cross-modal transfer learning, and real-world adaptability.
Divide-and-Conquer: Cold-Start Bundle Recommendation via Mixture of Diffusion Experts
May 08, 2025Cold-start bundle recommendation focuses on modeling new bundles with insufficient information to provide recommendations. Advanced bundle recommendation models usually learn bundle representations from multiple views (e.g., interaction view) at both the bundle and item levels. Consequently, the cold-start problem for bundles is more challenging than that for traditional items due to the dual-level multi-view complexity. In this paper, we propose a novel Mixture of Diffusion Experts (MoDiffE) framework, which employs a divide-and-conquer strategy for cold-start bundle recommendation and follows three steps:(1) Divide: The bundle cold-start problem is divided into independent but similar sub-problems sequentially by level and view, which can be summarized as the poor representation of feature-missing bundles in prior-embedding models. (2) Conquer: Beyond prior-embedding models that fundamentally provide the embedded representations, we introduce a diffusion-based method to solve all sub-problems in a unified way, which directly generates diffusion representations using diffusion models without depending on specific features. (3) Combine: A cold-aware hierarchical Mixture of Experts (MoE) is employed to combine results of the sub-problems for final recommendations, where the two models for each view serve as experts and are adaptively fused for different bundles in a multi-layer manner. Additionally, MoDiffE adopts a multi-stage decoupled training pipeline and introduces a cold-start gating augmentation method to enable the training of gating for cold bundles. Through extensive experiments on three real-world datasets, we demonstrate that MoDiffE significantly outperforms existing solutions in handling cold-start bundle recommendation. It achieves up to a 0.1027 absolute gain in Recall@20 in cold-start scenarios and up to a 47.43\% relative improvement in all-bundle scenarios.
How to Enable Effective Cooperation Between Humans and NLP Models: A Survey of Principles, Formalizations, and Beyond
Jan 10, 2025



With the advancement of large language models (LLMs), intelligent models have evolved from mere tools to autonomous agents with their own goals and strategies for cooperating with humans. This evolution has birthed a novel paradigm in NLP, i.e., human-model cooperation, that has yielded remarkable progress in numerous NLP tasks in recent years. In this paper, we take the first step to present a thorough review of human-model cooperation, exploring its principles, formalizations, and open challenges. In particular, we introduce a new taxonomy that provides a unified perspective to summarize existing approaches. Also, we discuss potential frontier areas and their corresponding challenges. We regard our work as an entry point, paving the way for more breakthrough research in this regard.
A Diversity-Enhanced Knowledge Distillation Model for Practical Math Word Problem Solving
Jan 07, 2025Math Word Problem (MWP) solving is a critical task in natural language processing, has garnered significant research interest in recent years. Various recent studies heavily rely on Seq2Seq models and their extensions (e.g., Seq2Tree and Graph2Tree) to generate mathematical equations. While effective, these models struggle to generate diverse but counterpart solution equations, limiting their generalization across various math problem scenarios. In this paper, we introduce a novel Diversity-enhanced Knowledge Distillation (DivKD) model for practical MWP solving. Our approach proposes an adaptive diversity distillation method, in which a student model learns diverse equations by selectively transferring high-quality knowledge from a teacher model. Additionally, we design a diversity prior-enhanced student model to better capture the diversity distribution of equations by incorporating a conditional variational auto-encoder. Extensive experiments on {four} MWP benchmark datasets demonstrate that our approach achieves higher answer accuracy than strong baselines while maintaining high efficiency for practical applications.
Learning to Ask: Conversational Product Search via Representation Learning
Nov 18, 2024Online shopping platforms, such as Amazon and AliExpress, are increasingly prevalent in society, helping customers purchase products conveniently. With recent progress in natural language processing, researchers and practitioners shift their focus from traditional product search to conversational product search. Conversational product search enables user-machine conversations and through them collects explicit user feedback that allows to actively clarify the users' product preferences. Therefore, prospective research on an intelligent shopping assistant via conversations is indispensable. Existing publications on conversational product search either model conversations independently from users, queries, and products or lead to a vocabulary mismatch. In this work, we propose a new conversational product search model, ConvPS, to assist users in locating desirable items. The model is first trained to jointly learn the semantic representations of user, query, item, and conversation via a unified generative framework. After learning these representations, they are integrated to retrieve the target items in the latent semantic space. Meanwhile, we propose a set of greedy and explore-exploit strategies to learn to ask the user a sequence of high-performance questions for conversations. Our proposed ConvPS model can naturally integrate the representation learning of the user, query, item, and conversation into a unified generative framework, which provides a promising avenue for constructing accurate and robust conversational product search systems that are flexible and adaptive. Experimental results demonstrate that our ConvPS model significantly outperforms state-of-the-art baselines.
A Survey on Bundle Recommendation: Methods, Applications, and Challenges
Nov 01, 2024

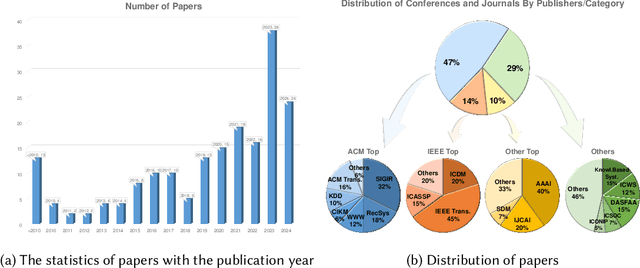
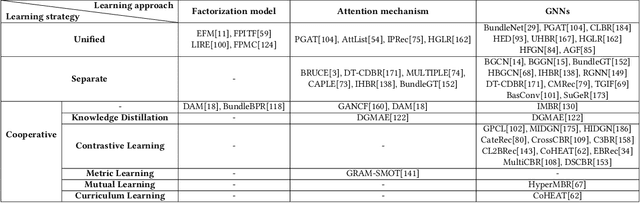
In recent years, bundle recommendation systems have gained significant attention in both academia and industry due to their ability to enhance user experience and increase sales by recommending a set of items as a bundle rather than individual items. This survey provides a comprehensive review on bundle recommendation, beginning by a taxonomy for exploring product bundling. We classify it into two categories based on bundling strategy from various application domains, i.e., discriminative and generative bundle recommendation. Then we formulate the corresponding tasks of the two categories and systematically review their methods: 1) representation learning from bundle and item levels and interaction modeling for discriminative bundle recommendation; 2) representation learning from item level and bundle generation for generative bundle recommendation. Subsequently, we survey the resources of bundle recommendation including datasets and evaluation metrics, and conduct reproducibility experiments on mainstream models. Lastly, we discuss the main challenges and highlight the promising future directions in the field of bundle recommendation, aiming to serve as a useful resource for researchers and practitioners. Our code and datasets are publicly available at https://github.com/WUT-IDEA/bundle-recommendation-survey.
Review-based Recommender Systems: A Survey of Approaches, Challenges and Future Perspectives
May 09, 2024



Recommender systems play a pivotal role in helping users navigate an overwhelming selection of products and services. On online platforms, users have the opportunity to share feedback in various modes, including numerical ratings, textual reviews, and likes/dislikes. Traditional recommendation systems rely on users explicit ratings or implicit interactions (e.g. likes, clicks, shares, saves) to learn user preferences and item characteristics. Beyond these numerical ratings, textual reviews provide insights into users fine-grained preferences and item features. Analyzing these reviews is crucial for enhancing the performance and interpretability of personalized recommendation results. In recent years, review-based recommender systems have emerged as a significant sub-field in this domain. In this paper, we provide a comprehensive overview of the developments in review-based recommender systems over recent years, highlighting the importance of reviews in recommender systems, as well as the challenges associated with extracting features from reviews and integrating them into ratings. Specifically, we present a categorization of these systems and summarize the state-of-the-art methods, analyzing their unique features, effectiveness, and limitations. Finally, we propose potential directions for future research, including the integration of multi-modal data, multi-criteria rating information, and ethical considerations.
One Subgraph for All: Efficient Reasoning on Opening Subgraphs for Inductive Knowledge Graph Completion
Apr 24, 2024Knowledge Graph Completion (KGC) has garnered massive research interest recently, and most existing methods are designed following a transductive setting where all entities are observed during training. Despite the great progress on the transductive KGC, these methods struggle to conduct reasoning on emerging KGs involving unseen entities. Thus, inductive KGC, which aims to deduce missing links among unseen entities, has become a new trend. Many existing studies transform inductive KGC as a graph classification problem by extracting enclosing subgraphs surrounding each candidate triple. Unfortunately, they still face certain challenges, such as the expensive time consumption caused by the repeat extraction of enclosing subgraphs, and the deficiency of entity-independent feature learning. To address these issues, we propose a global-local anchor representation (GLAR) learning method for inductive KGC. Unlike previous methods that utilize enclosing subgraphs, we extract a shared opening subgraph for all candidates and perform reasoning on it, enabling the model to perform reasoning more efficiently. Moreover, we design some transferable global and local anchors to learn rich entity-independent features for emerging entities. Finally, a global-local graph reasoning model is applied on the opening subgraph to rank all candidates. Extensive experiments show that our GLAR outperforms most existing state-of-the-art methods.
MealRec$^+$: A Meal Recommendation Dataset with Meal-Course Affiliation for Personalization and Healthiness
Apr 08, 2024Meal recommendation, as a typical health-related recommendation task, contains complex relationships between users, courses, and meals. Among them, meal-course affiliation associates user-meal and user-course interactions. However, an extensive literature review demonstrates that there is a lack of publicly available meal recommendation datasets including meal-course affiliation. Meal recommendation research has been constrained in exploring the impact of cooperation between two levels of interaction on personalization and healthiness. To pave the way for meal recommendation research, we introduce a new benchmark dataset called MealRec$^+$. Due to constraints related to user health privacy and meal scenario characteristics, the collection of data that includes both meal-course affiliation and two levels of interactions is impeded. Therefore, a simulation method is adopted to derive meal-course affiliation and user-meal interaction from the user's dining sessions simulated based on user-course interaction data. Then, two well-known nutritional standards are used to calculate the healthiness scores of meals. Moreover, we experiment with several baseline models, including separate and cooperative interaction learning methods. Our experiment demonstrates that cooperating the two levels of interaction in appropriate ways is beneficial for meal recommendations. Furthermore, in response to the less healthy recommendation phenomenon found in the experiment, we explore methods to enhance the healthiness of meal recommendations. The dataset is available on GitHub (https://github.com/WUT-IDEA/MealRecPlus).