 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Diversity-Enhanced Knowledge Distillation Model for Practical Math Word Problem Solving
Jan 07, 2025Math Word Problem (MWP) solving is a critical task in natural language processing, has garnered significant research interest in recent years. Various recent studies heavily rely on Seq2Seq models and their extensions (e.g., Seq2Tree and Graph2Tree) to generate mathematical equations. While effective, these models struggle to generate diverse but counterpart solution equations, limiting their generalization across various math problem scenarios. In this paper, we introduce a novel Diversity-enhanced Knowledge Distillation (DivKD) model for practical MWP solving. Our approach proposes an adaptive diversity distillation method, in which a student model learns diverse equations by selectively transferring high-quality knowledge from a teacher model. Additionally, we design a diversity prior-enhanced student model to better capture the diversity distribution of equations by incorporating a conditional variational auto-encoder. Extensive experiments on {four} MWP benchmark datasets demonstrate that our approach achieves higher answer accuracy than strong baselines while maintaining high efficiency for practical applications.
One Subgraph for All: Efficient Reasoning on Opening Subgraphs for Inductive Knowledge Graph Completion
Apr 24, 2024Knowledge Graph Completion (KGC) has garnered massive research interest recently, and most existing methods are designed following a transductive setting where all entities are observed during training. Despite the great progress on the transductive KGC, these methods struggle to conduct reasoning on emerging KGs involving unseen entities. Thus, inductive KGC, which aims to deduce missing links among unseen entities, has become a new trend. Many existing studies transform inductive KGC as a graph classification problem by extracting enclosing subgraphs surrounding each candidate triple. Unfortunately, they still face certain challenges, such as the expensive time consumption caused by the repeat extraction of enclosing subgraphs, and the deficiency of entity-independent feature learning. To address these issues, we propose a global-local anchor representation (GLAR) learning method for inductive KGC. Unlike previous methods that utilize enclosing subgraphs, we extract a shared opening subgraph for all candidates and perform reasoning on it, enabling the model to perform reasoning more efficiently. Moreover, we design some transferable global and local anchors to learn rich entity-independent features for emerging entities. Finally, a global-local graph reasoning model is applied on the opening subgraph to rank all candidates. Extensive experiments show that our GLAR outperforms most existing state-of-the-art methods.
MDistMult: A Multiple Scoring Functions Model for Link Prediction on Antiviral Drugs Knowledge Graph
Nov 29, 2021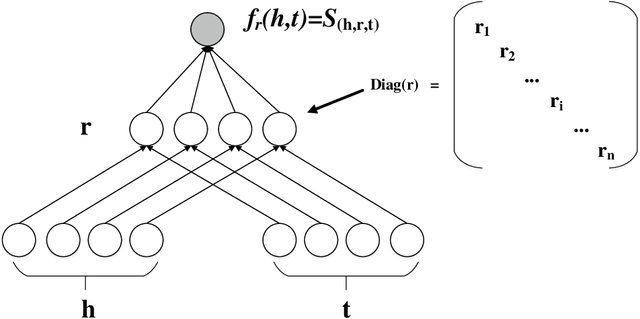
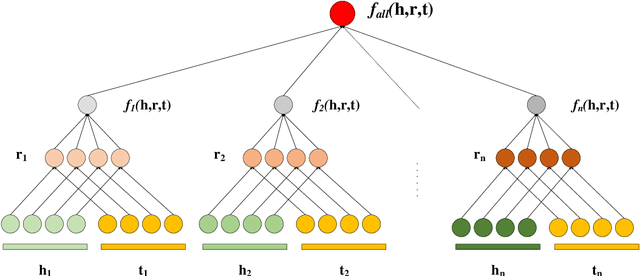
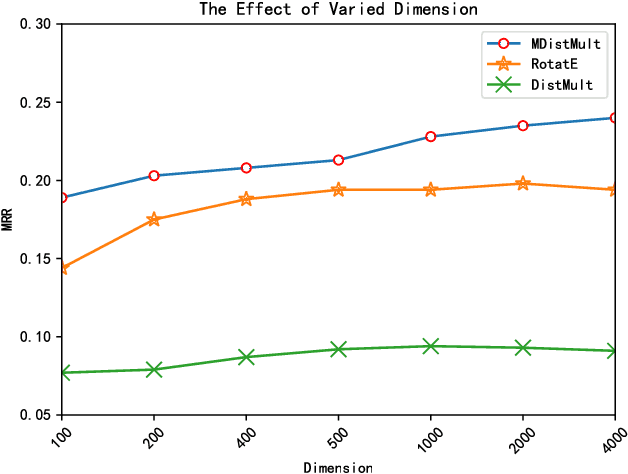
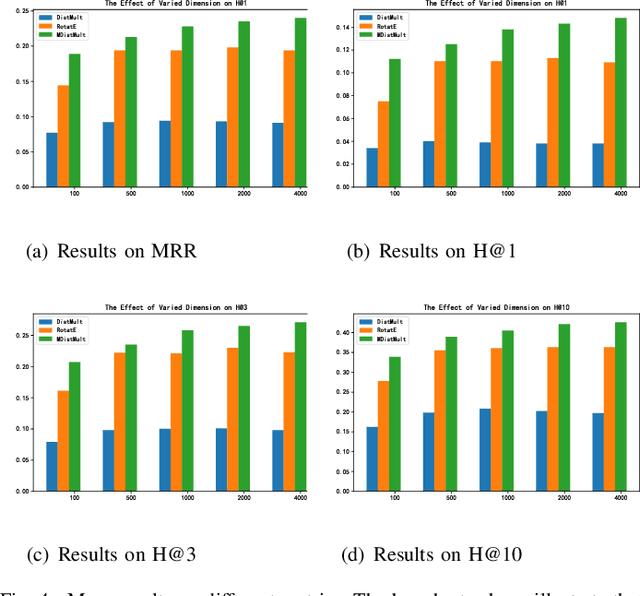
Knowledge graphs (KGs) on COVID-19 have been constructed to accelerate the research process of COVID-19. However, KGs are always incomplete, especially the new constructed COVID-19 KGs. Link prediction task aims to predict missing entities for (e, r, t) or (h, r, e), where h and t are certain entities, e is an entity that needs to be predicted and r is a relation. This task also has the potential to solve COVID-19 related KGs' incomplete problem. Although various knowledge graph embedding (KGE) approaches have been proposed to the link prediction task, these existing methods suffer from the limitation of using a single scoring function, which fails to capture rich features of COVID-19 KGs. In this work, we propose the MDistMult model that leverages multiple scoring functions to extract more features from existing triples. We employ experiments on the CCKS2020 COVID-19 Antiviral Drugs Knowledge Graph (CADKG). The experimental results demonstrate that our MDistMult achieves state-of-the-art performance in link prediction task on the CADKG dataset
Improving Stack Overflow question title generation with copying enhanced CodeBERT model and bi-modal information
Sep 27, 2021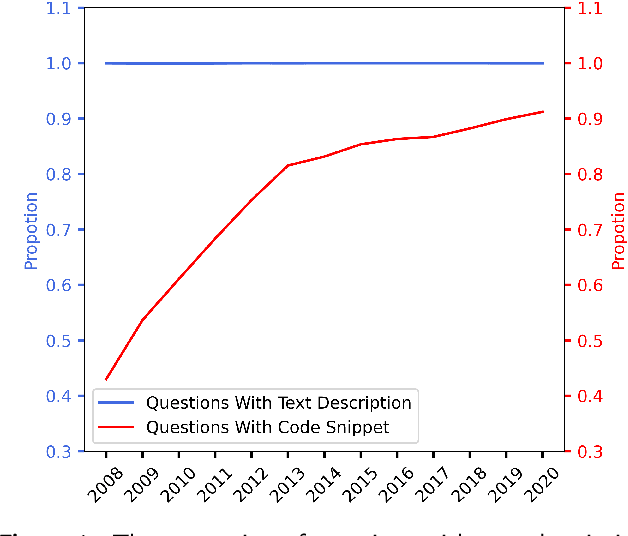
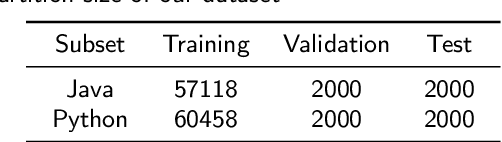
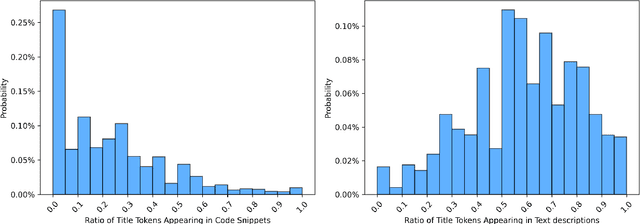
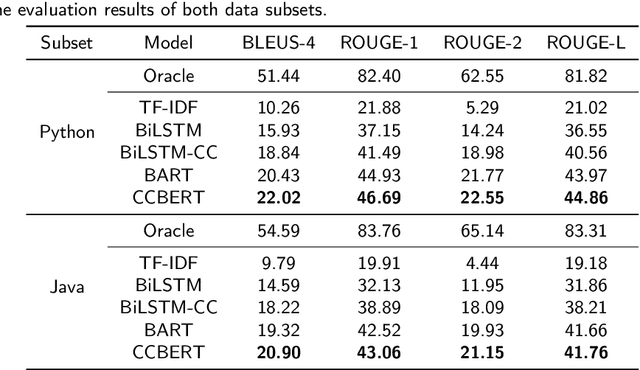
Context: Stack Overflow is very helpful for software developers who are seeking answers to programming problems. Previous studies have shown that a growing number of questions are of low-quality and thus obtain less attention from potential answerers. Gao et al. proposed a LSTM-based model (i.e., BiLSTM-CC) to automatically generate question titles from the code snippets to improve the question quality. However, only using the code snippets in question body cannot provide sufficient information for title generation, and LSTMs cannot capture the long-range dependencies between tokens. Objective: We propose CCBERT, a deep learning based novel model to enhance the performance of question title generation by making full use of the bi-modal information of the entire question body. Methods: CCBERT follows the encoder-decoder paradigm, and uses CodeBERT to encode the question body into hidden representations, a stacked Transformer decoder to generate predicted tokens, and an additional copy attention layer to refine the output distribution. Both the encoder and decoder perform the multi-head self-attention operation to better capture the long-range dependencies. We build a dataset containing more than 120,000 high-quality questions filtered from the data officially published by Stack Overflow to verify the effectiveness of the CCBERT model. Results: CCBERT achieves a better performance on the dataset, and especially outperforms BiLSTM-CC and a multi-purpose pre-trained model (BART) by 14% and 4% on average, respectively. Experiments on both code-only and low-resource datasets also show the superiority of CCBERT with less performance degradation, which are 40% and 13.5% for BiLSTM-CC, while 24% and 5% for CCBERT, respectively.