 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Temperature-Constrained Non-Deterministic Machine Translation: Potential and Evaluation
Jan 20, 2026In recent years, the non-deterministic properties of language models have garnered considerable attention and have shown a significant influence on real-world applications. However, such properties remain under-explored in machine translation (MT), a complex, non-deterministic NLP task. In this study, we systematically evaluate modern MT systems and identify temperature-constrained Non-Deterministic MT (ND-MT) as a distinct phenomenon. Additionally, we demonstrate that ND-MT exhibits significant potential in addressing the multi-modality issue that has long challenged MT research and provides higher-quality candidates than Deterministic MT (D-MT) under temperature constraints. However, ND-MT introduces new challenges in evaluating system performance. Specifically, the evaluation framework designed for D-MT fails to yield consistent evaluation results when applied to ND-MT. We further investigate this emerging challenge by evaluating five state-of-the-art ND-MT systems across three open datasets using both lexical-based and semantic-based metrics at varying sampling sizes. The results reveal a Buckets effect across these systems: the lowest-quality candidate generated by ND-MT consistently determines the overall system ranking across different sampling sizes for all reasonable metrics. Furthermore, we propose the ExpectoSample strategy to automatically assess the reliability of evaluation metrics for selecting robust ND-MT.
Memo-SQL: Structured Decomposition and Experience-Driven Self-Correction for Training-Free NL2SQL
Jan 15, 2026Existing NL2SQL systems face two critical limitations: (1) they rely on in-context learning with only correct examples, overlooking the rich signal in historical error-fix pairs that could guide more robust self-correction; and (2) test-time scaling approaches often decompose questions arbitrarily, producing near-identical SQL candidates across runs and diminishing ensemble gains. Moreover, these methods suffer from a stark accuracy-efficiency trade-off: high performance demands excessive computation, while fast variants compromise quality. We present Memo-SQL, a training-free framework that addresses these issues through two simple ideas: structured decomposition and experience-aware self-correction. Instead of leaving decomposition to chance, we apply three clear strategies, entity-wise, hierarchical, and atomic sequential, to encourage diverse reasoning. For correction, we build a dynamic memory of both successful queries and historical error-fix pairs, and use retrieval-augmented prompting to bring relevant examples into context at inference time, no fine-tuning or external APIs required. On BIRD, Memo-SQL achieves 68.5% execution accuracy, setting a new state of the art among open, zero-fine-tuning methods, while using over 10 times fewer resources than prior TTS approaches.
Mitigating the Language Mismatch and Repetition Issues in LLM-based Machine Translation via Model Editing
Oct 09, 2024

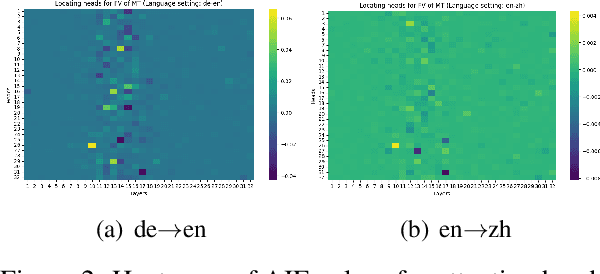

Large Language Models (LLMs) have recently revolutionized the NLP field, while they still fall short in some specific down-stream tasks. In the work, we focus on utilizing LLMs to perform machine translation, where we observe that two patterns of errors frequently occur and drastically affect the translation quality: language mismatch and repetition. The work sets out to explore the potential for mitigating these two issues by leveraging model editing methods, e.g., by locating Feed-Forward Network (FFN) neurons or something that are responsible for the errors and deactivating them in the inference time. We find that directly applying such methods either limited effect on the targeted errors or has significant negative side-effect on the general translation quality, indicating that the located components may also be crucial for ensuring machine translation with LLMs on the rails. To this end, we propose to refine the located components by fetching the intersection of the locating results under different language settings, filtering out the aforementioned information that is irrelevant to targeted errors. The experiment results empirically demonstrate that our methods can effectively reduce the language mismatch and repetition ratios and meanwhile enhance or keep the general translation quality in most cases.
MDistMult: A Multiple Scoring Functions Model for Link Prediction on Antiviral Drugs Knowledge Graph
Nov 29, 2021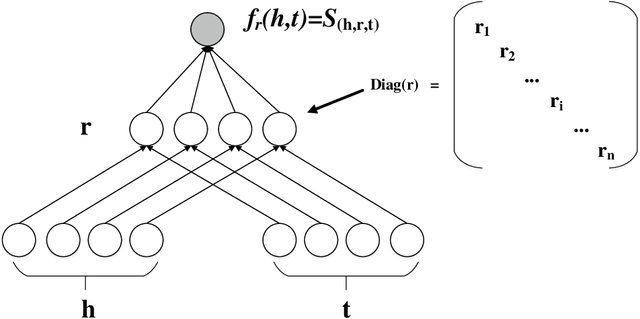
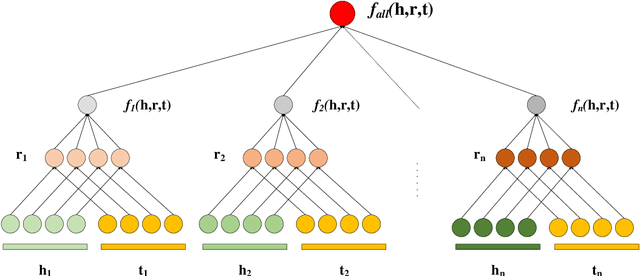
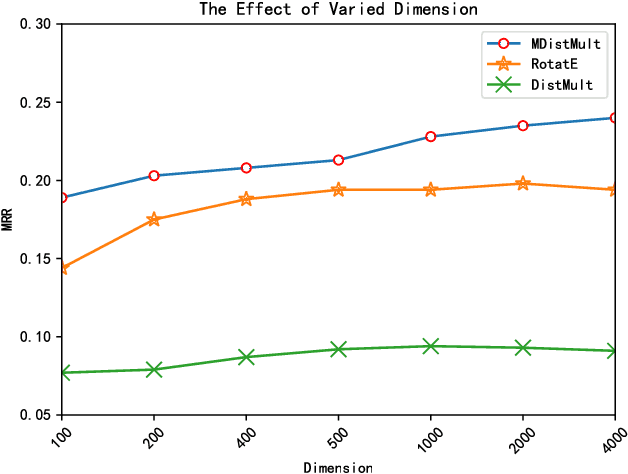
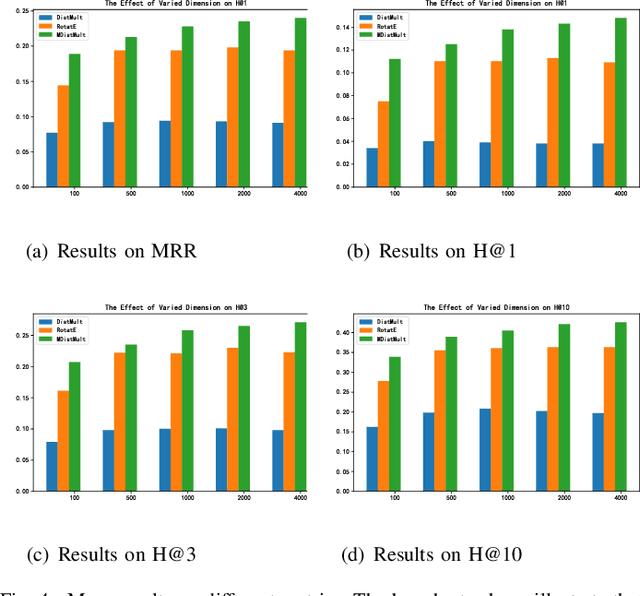
Knowledge graphs (KGs) on COVID-19 have been constructed to accelerate the research process of COVID-19. However, KGs are always incomplete, especially the new constructed COVID-19 KGs. Link prediction task aims to predict missing entities for (e, r, t) or (h, r, e), where h and t are certain entities, e is an entity that needs to be predicted and r is a relation. This task also has the potential to solve COVID-19 related KGs' incomplete problem. Although various knowledge graph embedding (KGE) approaches have been proposed to the link prediction task, these existing methods suffer from the limitation of using a single scoring function, which fails to capture rich features of COVID-19 KGs. In this work, we propose the MDistMult model that leverages multiple scoring functions to extract more features from existing triples. We employ experiments on the CCKS2020 COVID-19 Antiviral Drugs Knowledge Graph (CADKG). The experimental results demonstrate that our MDistMult achieves state-of-the-art performance in link prediction task on the CADKG dataset