 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDEA: An Interpretable and Editable Decision-Making Framework for LLMs via Verbal-to-Numeric Calibration
Apr 14, 2026Large Language Models are increasingly deployed for decision-making, yet their adoption in high-stakes domains remains limited by miscalibrated probabilities, unfaithful explanations, and inability to incorporate expert knowledge precisely. We propose IDEA, a framework that extracts LLM decision knowledge into an interpretable parametric model over semantically meaningful factors. Through joint learning of verbal-to-numerical mappings and decision parameters via EM, correlated sampling that preserves factor dependencies, and direct parameter editing with mathematical guarantees, IDEA produces calibrated probabilities while enabling quantitative human-AI collaboration. Experiments across five datasets show IDEA with Qwen-3-32B (78.6%) outperforms DeepSeek R1 (68.1%) and GPT-5.2 (77.9%), achieving perfect factor exclusion and exact calibration -- precision unattainable through prompting alone. The implementation is publicly available at https://github.com/leonbig/IDEA.
Agentization of Digital Assets for the Agentic Web: Concepts, Techniques, and Benchmark
Apr 05, 2026Agentic Web, as a new paradigm that redefines the internet through autonomous, goal-driven interactions, plays an important role in group intelligence. As the foundational semantic primitives of the Agentic Web, digital assets encapsulate interactive web elements into agents, which expand the capacities and coverage of agents in agentic web. The lack of automated methodologies for agent generation limits the wider usage of digital assets and the advancement of the Agentic Web. In this paper, we first formalize these challenges by strictly defining the A2A-Agentization process, decomposing it into critical stages and identifying key technical hurdles on top of the A2A protocol. Based on this framework, we develop an Agentization Agent to agentize digital assets for the Agentic Web. To rigorously evaluate this capability, we propose A2A-Agentization Bench, the first benchmark explicitly designed to evaluate agentization quality in terms of fidelity and interoperability. Our experiments demonstrate that our approach effectively activates the functional capabilities of digital assets and enables interoperable A2A multi-agent collaboration. We believe this work will further facilitate scalable and standardized integration of digital assets into the Agentic Web ecosystem.
StealthMark: Harmless and Stealthy Ownership Verification for Medical Segmentation via Uncertainty-Guided Backdoors
Jan 23, 2026Annotating medical data for training AI models is often costly and limited due to the shortage of specialists with relevant clinical expertise. This challenge is further compounded by privacy and ethical concerns associated with sensitive patient information. As a result, well-trained medical segmentation models on private datasets constitute valuable intellectual property requiring robust protection mechanisms. Existing model protection techniques primarily focus on classification and generative tasks, while segmentation models-crucial to medical image analysis-remain largely underexplored. In this paper, we propose a novel, stealthy, and harmless method, StealthMark, for verifying the ownership of medical segmentation models under black-box conditions. Our approach subtly modulates model uncertainty without altering the final segmentation outputs, thereby preserving the model's performance. To enable ownership verification, we incorporate model-agnostic explanation methods, e.g. LIME, to extract feature attributions from the model outputs. Under specific triggering conditions, these explanations reveal a distinct and verifiable watermark. We further design the watermark as a QR code to facilitate robust and recognizable ownership claims. We conducted extensive experiments across four medical imaging datasets and five mainstream segmentation models. The results demonstrate the effectiveness, stealthiness, and harmlessness of our method on the original model's segmentation performance. For example, when applied to the SAM model, StealthMark consistently achieved ASR above 95% across various datasets while maintaining less than a 1% drop in Dice and AUC scores, significantly outperforming backdoor-based watermarking methods and highlighting its strong potential for practical deployment. Our implementation code is made available at: https://github.com/Qinkaiyu/StealthMark.
TrimTokenator-LC: Towards Adaptive Visual Token Pruning for Large Multimodal Models with Long Contexts
Dec 31, 2025Large Multimodal Models (LMMs) have proven effective on various tasks. They typically encode visual inputs into Original Model sequences of tokens, which are then concatenated with textual tokens and jointly processed by the language model. However, the growing number of visual tokens greatly increases inference cost. Visual token pruning has emerged as a promising solution. However, existing methods often overlook scenarios involving long context inputs with multiple images. In this paper, we analyze the challenges of visual token pruning in long context, multi-image settings and introduce an adaptive pruning method tailored for such scenarios. We decompose redundancy into intra-image and inter-image components and quantify them through intra-image diversity and inter-image variation, which jointly guide dynamic budget allocation. Our approach consists of two stages. The intra-image stage allocates each image a content-aware token budget and greedily selects its most representative tokens. The inter-image stage performs global diversity filtering to form a candidate pool and then applies a Pareto selection procedure that balances diversity with text alignment. Extensive experiments show that our approach can reduce up to 80% of visual tokens while maintaining performance in long context settings.
StarCraft+: Benchmarking Multi-agent Algorithms in Adversary Paradigm
Dec 18, 2025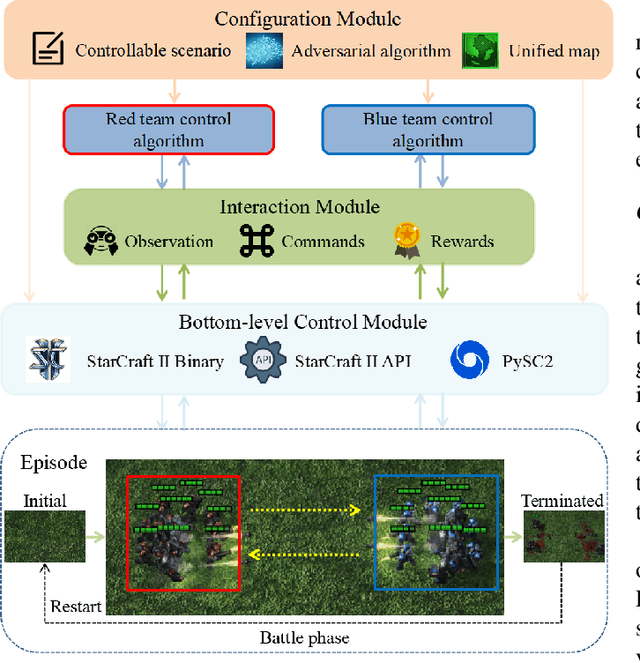
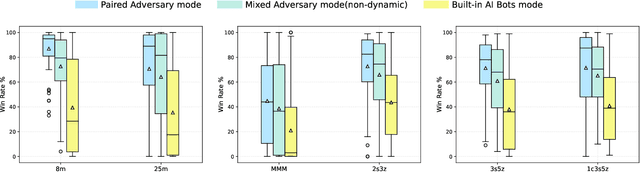
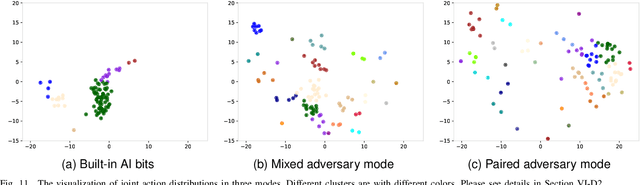
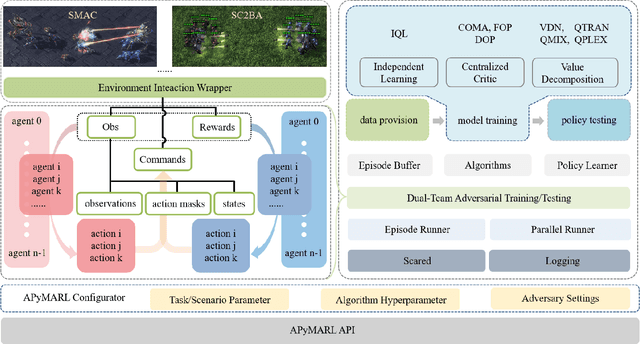
Deep multi-agent reinforcement learning (MARL) algorithms are booming in the field of collaborative intelligence, and StarCraft multi-agent challenge (SMAC) is widely-used as the benchmark therein. However, imaginary opponents of MARL algorithms are practically configured and controlled in a fixed built-in AI mode, which causes less diversity and versatility in algorithm evaluation. To address this issue, in this work, we establish a multi-agent algorithm-vs-algorithm environment, named StarCraft II battle arena (SC2BA), to refresh the benchmarking of MARL algorithms in an adversary paradigm. Taking StarCraft as infrastructure, the SC2BA environment is specifically created for inter-algorithm adversary with the consideration of fairness, usability and customizability, and meantime an adversarial PyMARL (APyMARL) library is developed with easy-to-use interfaces/modules. Grounding in SC2BA, we benchmark those classic MARL algorithms in two types of adversarial modes: dual-algorithm paired adversary and multi-algorithm mixed adversary, where the former conducts the adversary of pairwise algorithms while the latter focuses on the adversary to multiple behaviors from a group of algorithms. The extensive benchmark experiments exhibit some thought-provoking observations/problems in the effectivity, sensibility and scalability of these completed algorithms. The SC2BA environment as well as reproduced experiments are released in \href{https://github.com/dooliu/SC2BA}{Github}, and we believe that this work could mark a new step for the MARL field in the coming years.
FullPart: Generating each 3D Part at Full Resolution
Oct 30, 2025Part-based 3D generation holds great potential for various applications. Previous part generators that represent parts using implicit vector-set tokens often suffer from insufficient geometric details. Another line of work adopts an explicit voxel representation but shares a global voxel grid among all parts; this often causes small parts to occupy too few voxels, leading to degraded quality. In this paper, we propose FullPart, a novel framework that combines both implicit and explicit paradigms. It first derives the bounding box layout through an implicit box vector-set diffusion process, a task that implicit diffusion handles effectively since box tokens contain little geometric detail. Then, it generates detailed parts, each within its own fixed full-resolution voxel grid. Instead of sharing a global low-resolution space, each part in our method - even small ones - is generated at full resolution, enabling the synthesis of intricate details. We further introduce a center-point encoding strategy to address the misalignment issue when exchanging information between parts of different actual sizes, thereby maintaining global coherence. Moreover, to tackle the scarcity of reliable part data, we present PartVerse-XL, the largest human-annotated 3D part dataset to date with 40K objects and 320K parts. Extensive experiments demonstrate that FullPart achieves state-of-the-art results in 3D part generation. We will release all code, data, and model to benefit future research in 3D part generation.
Sensitivity-LoRA: Low-Load Sensitivity-Based Fine-Tuning for Large Language Models
Sep 11, 2025Large Language Models (LLMs) have transformed both everyday life and scientific research. However, adapting LLMs from general-purpose models to specialized tasks remains challenging, particularly in resource-constrained environments. Low-Rank Adaptation (LoRA), a prominent method within Parameter-Efficient Fine-Tuning (PEFT), has emerged as a promising approach to LLMs by approximating model weight updates using low-rank decomposition. However, LoRA is limited by its uniform rank ( r ) allocation to each incremental matrix, and existing rank allocation techniques aimed at addressing this issue remain computationally inefficient, complex, and unstable, hindering practical applications. To address these limitations, we propose Sensitivity-LoRA, an efficient fine-tuning method that dynamically allocates ranks to weight matrices based on both their global and local sensitivities. It leverages the second-order derivatives (Hessian Matrix) of the loss function to effectively capture weight sensitivity, enabling optimal rank allocation with minimal computational overhead. Our experimental results have demonstrated robust effectiveness, efficiency and stability of Sensitivity-LoRA across diverse tasks and benchmarks.
AttenST: A Training-Free Attention-Driven Style Transfer Framework with Pre-Trained Diffusion Models
Mar 10, 2025While diffusion models have achieved remarkable progress in style transfer tasks, existing methods typically rely on fine-tuning or optimizing pre-trained models during inference, leading to high computational costs and challenges in balancing content preservation with style integration. To address these limitations, we introduce AttenST, a training-free attention-driven style transfer framework. Specifically, we propose a style-guided self-attention mechanism that conditions self-attention on the reference style by retaining the query of the content image while substituting its key and value with those from the style image, enabling effective style feature integration. To mitigate style information loss during inversion, we introduce a style-preserving inversion strategy that refines inversion accuracy through multiple resampling steps. Additionally, we propose a content-aware adaptive instance normalization, which integrates content statistics into the normalization process to optimize style fusion while mitigating the content degradation. Furthermore, we introduce a dual-feature cross-attention mechanism to fuse content and style features, ensuring a harmonious synthesis of structural fidelity and stylistic expression. Extensive experiments demonstrate that AttenST outperforms existing methods, achieving state-of-the-art performance in style transfer dataset.
MANet: Fine-Tuning Segment Anything Model for Multimodal Remote Sensing Semantic Segmentation
Oct 15, 2024



Multimodal remote sensing data, collected from a variety of sensors, provide a comprehensive and integrated perspective of the Earth's surface. By employing multimodal fusion techniques, semantic segmentation offers more detailed insights into geographic scenes compared to single-modality approaches. Building upon recent advancements in vision foundation models, particularly the Segment Anything Model (SAM), this study introduces a novel Multimodal Adapter-based Network (MANet) for multimodal remote sensing semantic segmentation. At the core of this approach is the development of a Multimodal Adapter (MMAdapter), which fine-tunes SAM's image encoder to effectively leverage the model's general knowledge for multimodal data. In addition, a pyramid-based Deep Fusion Module (DFM) is incorporated to further integrate high-level geographic features across multiple scales before decoding. This work not only introduces a novel network for multimodal fusion, but also demonstrates, for the first time, SAM's powerful generalization capabilities with Digital Surface Model (DSM) data. Experimental results on two well-established fine-resolution multimodal remote sensing datasets, ISPRS Vaihingen and ISPRS Potsdam, confirm that the proposed MANet significantly surpasses current models in the task of multimodal semantic segmentation. The source code for this work will be accessible at https://github.com/sstary/SSRS.
Bridging and Modeling Correlations in Pairwise Data for Direct Preference Optimization
Aug 14, 2024



Direct preference optimization (DPO), a widely adopted offline preference optimization algorithm, aims to align large language models (LLMs) with human-desired behaviors using pairwise preference data. However, the winning response and the losing response within pairwise data are generated isolatedly, leading to weak correlations between them as well as suboptimal alignment performance. To address this issue, we propose an effective framework named BMC, for bridging and modeling correlations in pairwise data. Firstly, we increase the consistency and informativeness of the pairwise preference signals by targeted modifications, synthesizing a pseudo winning response through improving the losing response based on the winning response. Secondly, we identify that DPO alone is insufficient to model these correlations and capture nuanced variations. Therefore, we propose learning token-level correlations by dynamically leveraging the policy model's confidence during training. Comprehensive experiments on QA, math, and instruction-following tasks demonstrate the effectiveness of our approach, significantly surpassing competitive baselines, including DPO. Additionally, our in-depth quantitative analysis reveals the reasons behind our method's superior performance over DPO and showcases its versatility to other DPO variants.