 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOLYRAG: Integrating Polyviews into Retrieval-Augmented Generation for Medical Applications
Apr 21, 2025



Large language models (LLMs) have become a disruptive force in the industry, introducing unprecedented capabilities in natural language processing, logical reasoning and so on. However, the challenges of knowledge updates and hallucination issues have limited the application of LLMs in medical scenarios, where retrieval-augmented generation (RAG) can offer significant assistance. Nevertheless, existing retrieve-then-read approaches generally digest the retrieved documents, without considering the timeliness, authoritativeness and commonality of retrieval. We argue that these approaches can be suboptimal, especially in real-world applications where information from different sources might conflict with each other and even information from the same source in different time scale might be different, and totally relying on this would deteriorate the performance of RAG approaches. We propose PolyRAG that carefully incorporate judges from different perspectives and finally integrate the polyviews for retrieval augmented generation in medical applications. Due to the scarcity of real-world benchmarks for evaluation, to bridge the gap we propose PolyEVAL, a benchmark consists of queries and documents collected from real-world medical scenarios (including medical policy, hospital & doctor inquiry and healthcare) with multiple tagging (e.g., timeliness, authoritativeness) on them. Extensive experiments and analysis on PolyEVAL have demonstrated the superiority of PolyRAG.
Advancing Academic Knowledge Retrieval via LLM-enhanced Representation Similarity Fusion
Oct 14, 2024


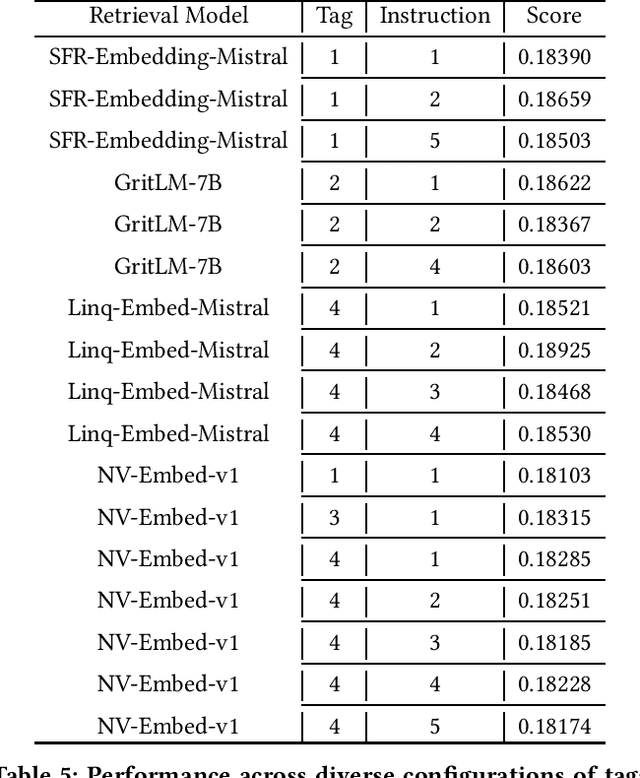
In an era marked by robust technological growth and swift information renewal, furnishing researchers and the populace with top-tier, avant-garde academic insights spanning various domains has become an urgent necessity. The KDD Cup 2024 AQA Challenge is geared towards advancing retrieval models to identify pertinent academic terminologies from suitable papers for scientific inquiries. This paper introduces the LLM-KnowSimFuser proposed by Robo Space, which wins the 2nd place in the competition. With inspirations drawed from the superior performance of LLMs on multiple tasks, after careful analysis of the provided datasets, we firstly perform fine-tuning and inference using LLM-enhanced pre-trained retrieval models to introduce the tremendous language understanding and open-domain knowledge of LLMs into this task, followed by a weighted fusion based on the similarity matrix derived from the inference results. Finally, experiments conducted on the competition datasets show the superiority of our proposal, which achieved a score of 0.20726 on the final leaderboard.
Similarity is Not All You Need: Endowing Retrieval Augmented Generation with Multi Layered Thoughts
May 30, 2024



In recent years, large language models (LLMs) have made remarkable achievements in various domains. However, the untimeliness and cost of knowledge updates coupled with hallucination issues of LLMs have curtailed their applications in knowledge intensive tasks, where retrieval augmented generation (RAG) can be of help. Nevertheless, existing retrieval augmented models typically use similarity as a bridge between queries and documents and follow a retrieve then read procedure. In this work, we argue that similarity is not always the panacea and totally relying on similarity would sometimes degrade the performance of retrieval augmented generation. To this end, we propose MetRag, a Multi layEred Thoughts enhanced Retrieval Augmented Generation framework. To begin with, beyond existing similarity oriented thought, we embrace a small scale utility model that draws supervision from an LLM for utility oriented thought and further come up with a smarter model by comprehensively combining the similarity and utility oriented thoughts. Furthermore, given the fact that the retrieved document set tends to be huge and using them in isolation makes it difficult to capture the commonalities and characteristics among them, we propose to make an LLM as a task adaptive summarizer to endow retrieval augmented generation with compactness-oriented thought. Finally, with multi layered thoughts from the precedent stages, an LLM is called for knowledge augmented generation. Extensive experiments on knowledge-intensive tasks have demonstrated the superiority of MetRag.
Your decision path does matter in pre-training industrial recommenders with multi-source behaviors
May 27, 2024

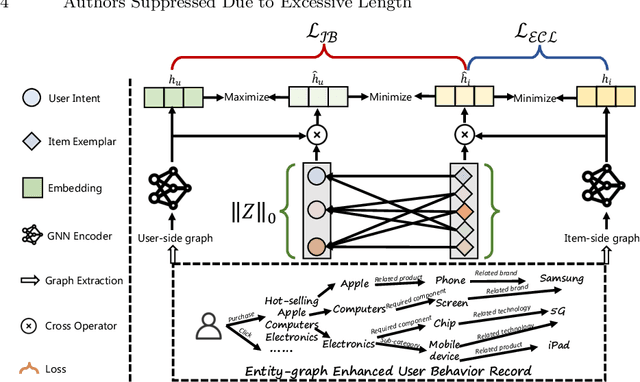

Online service platforms offering a wide range of services through miniapps have become crucial for users who visit these platforms with clear intentions to find services they are interested in. Aiming at effective content delivery, cross-domain recommendation are introduced to learn high-quality representations by transferring behaviors from data-rich scenarios. However, these methods overlook the impact of the decision path that users take when conduct behaviors, that is, users ultimately exhibit different behaviors based on various intents. To this end, we propose HIER, a novel Hierarchical decIsion path Enhanced Representation learning for cross-domain recommendation. With the help of graph neural networks for high-order topological information of the knowledge graph between multi-source behaviors, we further adaptively learn decision paths through well-designed exemplar-level and information bottleneck based contrastive learning. Extensive experiments in online and offline environments show the superiority of HIER.
Making Large Language Models Better Knowledge Miners for Online Marketing with Progressive Prompting Augmentation
Dec 08, 2023Nowadays, the rapid development of mobile economy has promoted the flourishing of online marketing campaigns, whose success greatly hinges on the efficient matching between user preferences and desired marketing campaigns where a well-established Marketing-oriented Knowledge Graph (dubbed as MoKG) could serve as the critical "bridge" for preference propagation. In this paper, we seek to carefully prompt a Large Language Model (LLM) with domain-level knowledge as a better marketing-oriented knowledge miner for marketing-oriented knowledge graph construction, which is however non-trivial, suffering from several inevitable issues in real-world marketing scenarios, i.e., uncontrollable relation generation of LLMs,insufficient prompting ability of a single prompt, the unaffordable deployment cost of LLMs. To this end, we propose PAIR, a novel Progressive prompting Augmented mIning fRamework for harvesting marketing-oriented knowledge graph with LLMs. In particular, we reduce the pure relation generation to an LLM based adaptive relation filtering process through the knowledge-empowered prompting technique. Next, we steer LLMs for entity expansion with progressive prompting augmentation,followed by a reliable aggregation with comprehensive consideration of both self-consistency and semantic relatedness. In terms of online serving, we specialize in a small and white-box PAIR (i.e.,LightPAIR),which is fine-tuned with a high-quality corpus provided by a strong teacher-LLM. Extensive experiments and practical applications in audience targeting verify the effectiveness of the proposed (Light)PAIR.
PEACE: Prototype lEarning Augmented transferable framework for Cross-domain rEcommendation
Dec 04, 2023



To help merchants/customers to provide/access a variety of services through miniapps, online service platforms have occupied a critical position in the effective content delivery, in which how to recommend items in the new domain launched by the service provider for customers has become more urgent. However, the non-negligible gap between the source and diversified target domains poses a considerable challenge to cross-domain recommendation systems, which often leads to performance bottlenecks in industrial settings. While entity graphs have the potential to serve as a bridge between domains, rudimentary utilization still fail to distill useful knowledge and even induce the negative transfer issue. To this end, we propose PEACE, a Prototype lEarning Augmented transferable framework for Cross-domain rEcommendation. For domain gap bridging, PEACE is built upon a multi-interest and entity-oriented pre-training architecture which could not only benefit the learning of generalized knowledge in a multi-granularity manner, but also help leverage more structural information in the entity graph. Then, we bring the prototype learning into the pre-training over source domains, so that representations of users and items are greatly improved by the contrastive prototype learning module and the prototype enhanced attention mechanism for adaptive knowledge utilization. To ease the pressure of online serving, PEACE is carefully deployed in a lightweight manner, and significant performance improvements are observed in both online and offline environments.
Which Matters Most in Making Fund Investment Decisions? A Multi-granularity Graph Disentangled Learning Framework
Nov 23, 2023In this paper, we highlight that both conformity and risk preference matter in making fund investment decisions beyond personal interest and seek to jointly characterize these aspects in a disentangled manner. Consequently, we develop a novel M ulti-granularity Graph Disentangled Learning framework named MGDL to effectively perform intelligent matching of fund investment products. Benefiting from the well-established fund graph and the attention module, multi-granularity user representations are derived from historical behaviors to separately express personal interest, conformity and risk preference in a fine-grained way. To attain stronger disentangled representations with specific semantics, MGDL explicitly involve two self-supervised signals, i.e., fund type based contrasts and fund popularity. Extensive experiments in offline and online environments verify the effectiveness of MGDL.