 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Score Filter Enhanced Data Assimilation Framework for Data-Driven Dynamical Systems
Mar 16, 2026We introduce a score-filter-enhanced data assimilation framework designed to reduce predictive uncertainty in machine learning (ML) models for data-driven dynamical system forecasting. Machine learning serves as an efficient numerical model for predicting dynamical systems. However, even with sufficient data, model uncertainty remains and accumulates over time, causing the long-term performance of ML models to deteriorate. To overcome this difficulty, we integrate data assimilation techniques into the training process to iteratively refine the model predictions by incorporating observational information. Specifically, we apply the Ensemble Score Filter (EnSF), a generative AI-based training-free diffusion model approach, for solving the data assimilation problem in high-dimensional nonlinear complex systems. This leads to a hybrid data assimilation-training framework that combines ML with EnSF to improve long-term predictive performance. We shall demonstrate that EnSF-enhanced ML can effectively reduce predictive uncertainty in ML-based Lorenz-96 system prediction and the Korteweg-De Vries (KdV) equation prediction.
MM-CondChain: A Programmatically Verified Benchmark for Visually Grounded Deep Compositional Reasoning
Mar 12, 2026Multimodal Large Language Models (MLLMs) are increasingly used to carry out visual workflows such as navigating GUIs, where the next step depends on verified visual compositional conditions (e.g., "if a permission dialog appears and the color of the interface is green, click Allow") and the process may branch or terminate early. Yet this capability remains under-evaluated: existing benchmarks focus on shallow-compositions or independent-constraints rather than deeply chained compositional conditionals. In this paper, we introduce MM-CondChain, a benchmark for visually grounded deep compositional reasoning. Each benchmark instance is organized as a multi-layer reasoning chain, where every layer contains a non-trivial compositional condition grounded in visual evidence and built from multiple objects, attributes, or relations. To answer correctly, an MLLM must perceive the image in detail, reason over multiple visual elements at each step, and follow the resulting execution path to the final outcome. To scalably construct such workflow-style data, we propose an agentic synthesis pipeline: a Planner orchestrates layer-by-layer generation of compositional conditions, while a Verifiable Programmatic Intermediate Representation (VPIR) ensures each layer's condition is mechanically verifiable. A Composer then assembles these verified layers into complete instructions. Using this pipeline, we construct benchmarks across three visual domains: natural images, data charts, and GUI trajectories. Experiments on a range of MLLMs show that even the strongest model attains only 53.33 Path F1, with sharp drops on hard negatives and as depth or predicate complexity grows, confirming that deep compositional reasoning remains a fundamental challenge.
NeuDiff Agent: A Governed AI Workflow for Single-Crystal Neutron Crystallography
Feb 18, 2026Large-scale facilities increasingly face analysis and reporting latency as the limiting step in scientific throughput, particularly for structurally and magnetically complex samples that require iterative reduction, integration, refinement, and validation. To improve time-to-result and analysis efficiency, NeuDiff Agent is introduced as a governed, tool-using AI workflow for TOPAZ at the Spallation Neutron Source that takes instrument data products through reduction, integration, refinement, and validation to a validated crystal structure and a publication-ready CIF. NeuDiff Agent executes this established pipeline under explicit governance by restricting actions to allowlisted tools, enforcing fail-closed verification gates at key workflow boundaries, and capturing complete provenance for inspection, auditing, and controlled replay. Performance is assessed using a fixed prompt protocol and repeated end-to-end runs with two large language model backends, with user and machine time partitioned and intervention burden and recovery behaviors quantified under gating. In a reference-case benchmark, NeuDiff Agent reduces wall time from 435 minutes (manual) to 86.5(4.7) to 94.4(3.5) minutes (4.6-5.0x faster) while producing a validated CIF with no checkCIF level A or B alerts. These results establish a practical route to deploy agentic AI in facility crystallography while preserving traceability and publication-facing validation requirements.
JADE: Expert-Grounded Dynamic Evaluation for Open-Ended Professional Tasks
Feb 06, 2026Evaluating agentic AI on open-ended professional tasks faces a fundamental dilemma between rigor and flexibility. Static rubrics provide rigorous, reproducible assessment but fail to accommodate diverse valid response strategies, while LLM-as-a-judge approaches adapt to individual responses yet suffer from instability and bias. Human experts address this dilemma by combining domain-grounded principles with dynamic, claim-level assessment. Inspired by this process, we propose JADE, a two-layer evaluation framework. Layer 1 encodes expert knowledge as a predefined set of evaluation skills, providing stable evaluation criteria. Layer 2 performs report-specific, claim-level evaluation to flexibly assess diverse reasoning strategies, with evidence-dependency gating to invalidate conclusions built on refuted claims. Experiments on BizBench show that JADE improves evaluation stability and reveals critical agent failure modes missed by holistic LLM-based evaluators. We further demonstrate strong alignment with expert-authored rubrics and effective transfer to a medical-domain benchmark, validating JADE across professional domains. Our code is publicly available at https://github.com/smiling-world/JADE.
SwimBird: Eliciting Switchable Reasoning Mode in Hybrid Autoregressive MLLMs
Feb 05, 2026Multimodal Large Language Models (MLLMs) have made remarkable progress in multimodal perception and reasoning by bridging vision and language. However, most existing MLLMs perform reasoning primarily with textual CoT, which limits their effectiveness on vision-intensive tasks. Recent approaches inject a fixed number of continuous hidden states as "visual thoughts" into the reasoning process and improve visual performance, but often at the cost of degraded text-based logical reasoning. We argue that the core limitation lies in a rigid, pre-defined reasoning pattern that cannot adaptively choose the most suitable thinking modality for different user queries. We introduce SwimBird, a reasoning-switchable MLLM that dynamically switches among three reasoning modes conditioned on the input: (1) text-only reasoning, (2) vision-only reasoning (continuous hidden states as visual thoughts), and (3) interleaved vision-text reasoning. To enable this capability, we adopt a hybrid autoregressive formulation that unifies next-token prediction for textual thoughts with next-embedding prediction for visual thoughts, and design a systematic reasoning-mode curation strategy to construct SwimBird-SFT-92K, a diverse supervised fine-tuning dataset covering all three reasoning patterns. By enabling flexible, query-adaptive mode selection, SwimBird preserves strong textual logic while substantially improving performance on vision-dense tasks. Experiments across diverse benchmarks covering textual reasoning and challenging visual understanding demonstrate that SwimBird achieves state-of-the-art results and robust gains over prior fixed-pattern multimodal reasoning methods.
A Score-based Diffusion Model Approach for Adaptive Learning of Stochastic Partial Differential Equation Solutions
Aug 09, 2025We propose a novel framework for adaptively learning the time-evolving solutions of stochastic partial differential equations (SPDEs) using score-based diffusion models within a recursive Bayesian inference setting. SPDEs play a central role in modeling complex physical systems under uncertainty, but their numerical solutions often suffer from model errors and reduced accuracy due to incomplete physical knowledge and environmental variability. To address these challenges, we encode the governing physics into the score function of a diffusion model using simulation data and incorporate observational information via a likelihood-based correction in a reverse-time stochastic differential equation. This enables adaptive learning through iterative refinement of the solution as new data becomes available. To improve computational efficiency in high-dimensional settings, we introduce the ensemble score filter, a training-free approximation of the score function designed for real-time inference. Numerical experiments on benchmark SPDEs demonstrate the accuracy and robustness of the proposed method under sparse and noisy observations.
Unify Graph Learning with Text: Unleashing LLM Potentials for Session Search
May 20, 2025Session search involves a series of interactive queries and actions to fulfill user's complex information need. Current strategies typically prioritize sequential modeling for deep semantic understanding, overlooking the graph structure in interactions. While some approaches focus on capturing structural information, they use a generalized representation for documents, neglecting the word-level semantic modeling. In this paper, we propose Symbolic Graph Ranker (SGR), which aims to take advantage of both text-based and graph-based approaches by leveraging the power of recent Large Language Models (LLMs). Concretely, we first introduce a set of symbolic grammar rules to convert session graph into text. This allows integrating session history, interaction process, and task instruction seamlessly as inputs for the LLM. Moreover, given the natural discrepancy between LLMs pre-trained on textual corpora, and the symbolic language we produce using our graph-to-text grammar, our objective is to enhance LLMs' ability to capture graph structures within a textual format. To achieve this, we introduce a set of self-supervised symbolic learning tasks including link prediction, node content generation, and generative contrastive learning, to enable LLMs to capture the topological information from coarse-grained to fine-grained. Experiment results and comprehensive analysis on two benchmark datasets, AOL and Tiangong-ST, confirm the superiority of our approach. Our paradigm also offers a novel and effective methodology that bridges the gap between traditional search strategies and modern LLMs.
Multi-fidelity Parameter Estimation Using Conditional Diffusion Models
Apr 02, 2025



We present a multi-fidelity method for uncertainty quantification of parameter estimates in complex systems, leveraging generative models trained to sample the target conditional distribution. In the Bayesian inference setting, traditional parameter estimation methods rely on repeated simulations of potentially expensive forward models to determine the posterior distribution of the parameter values, which may result in computationally intractable workflows. Furthermore, methods such as Markov Chain Monte Carlo (MCMC) necessitate rerunning the entire algorithm for each new data observation, further increasing the computational burden. Hence, we propose a novel method for efficiently obtaining posterior distributions of parameter estimates for high-fidelity models given data observations of interest. The method first constructs a low-fidelity, conditional generative model capable of amortized Bayesian inference and hence rapid posterior density approximation over a wide-range of data observations. When higher accuracy is needed for a specific data observation, the method employs adaptive refinement of the density approximation. It uses outputs from the low-fidelity generative model to refine the parameter sampling space, ensuring efficient use of the computationally expensive high-fidelity solver. Subsequently, a high-fidelity, unconditional generative model is trained to achieve greater accuracy in the target posterior distribution. Both low- and high- fidelity generative models enable efficient sampling from the target posterior and do not require repeated simulation of the high-fidelity forward model. We demonstrate the effectiveness of the proposed method on several numerical examples, including cases with multi-modal densities, as well as an application in plasma physics for a runaway electron simulation model.
MoDULA: Mixture of Domain-Specific and Universal LoRA for Multi-Task Learning
Dec 10, 2024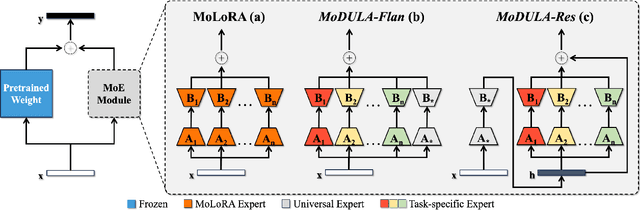
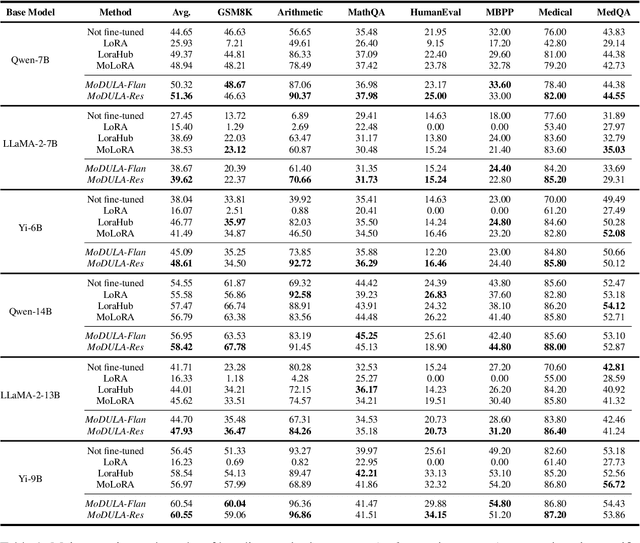
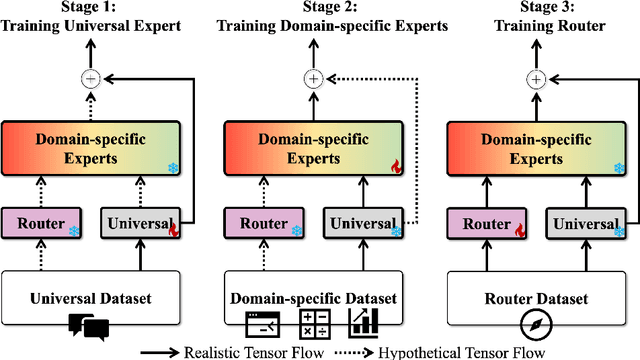
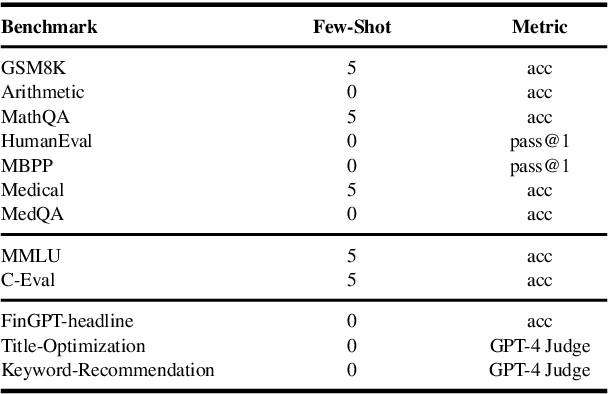
The growing demand for larger-scale models in the development of \textbf{L}arge \textbf{L}anguage \textbf{M}odels (LLMs) poses challenges for efficient training within limited computational resources. Traditional fine-tuning methods often exhibit instability in multi-task learning and rely heavily on extensive training resources. Here, we propose MoDULA (\textbf{M}ixture \textbf{o}f \textbf{D}omain-Specific and \textbf{U}niversal \textbf{L}oR\textbf{A}), a novel \textbf{P}arameter \textbf{E}fficient \textbf{F}ine-\textbf{T}uning (PEFT) \textbf{M}ixture-\textbf{o}f-\textbf{E}xpert (MoE) paradigm for improved fine-tuning and parameter efficiency in multi-task learning. The paradigm effectively improves the multi-task capability of the model by training universal experts, domain-specific experts, and routers separately. MoDULA-Res is a new method within the MoDULA paradigm, which maintains the model's general capability by connecting universal and task-specific experts through residual connections. The experimental results demonstrate that the overall performance of the MoDULA-Flan and MoDULA-Res methods surpasses that of existing fine-tuning methods on various LLMs. Notably, MoDULA-Res achieves more significant performance improvements in multiple tasks while reducing training costs by over 80\% without losing general capability. Moreover, MoDULA displays flexible pluggability, allowing for the efficient addition of new tasks without retraining existing experts from scratch. This progressive training paradigm circumvents data balancing issues, enhancing training efficiency and model stability. Overall, MoDULA provides a scalable, cost-effective solution for fine-tuning LLMs with enhanced parameter efficiency and generalization capability.
GenAI4UQ: A Software for Inverse Uncertainty Quantification Using Conditional Generative Models
Dec 09, 2024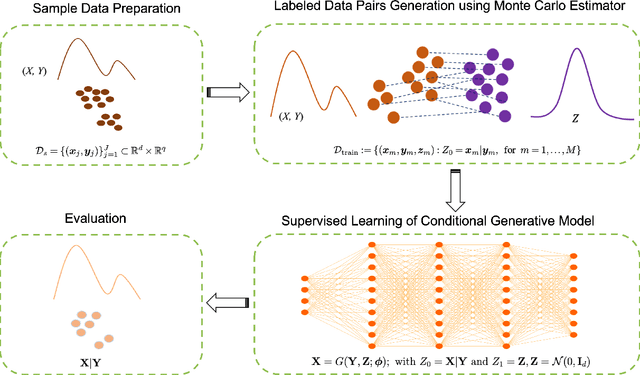
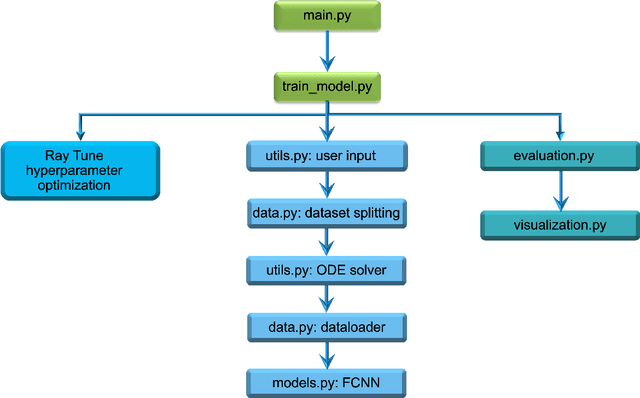
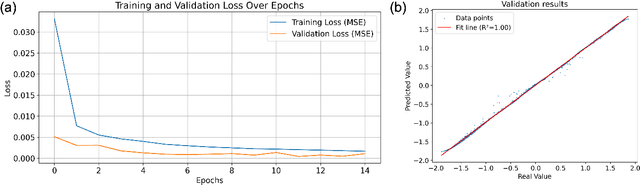

We introduce GenAI4UQ, a software package for inverse uncertainty quantification in model calibration, parameter estimation, and ensemble forecasting in scientific applications. GenAI4UQ leverages a generative artificial intelligence (AI) based conditional modeling framework to address the limitations of traditional inverse modeling techniques, such as Markov Chain Monte Carlo methods. By replacing computationally intensive iterative processes with a direct, learned mapping, GenAI4UQ enables efficient calibration of model input parameters and generation of output predictions directly from observations. The software's design allows for rapid ensemble forecasting with robust uncertainty quantification, while maintaining high computational and storage efficiency. GenAI4UQ simplifies the model training process through built-in auto-tuning of hyperparameters, making it accessible to users with varying levels of expertise. Its conditional generative framework ensures versatility, enabling applicability across a wide range of scientific domains. At its core, GenAI4UQ transforms the paradigm of inverse modeling by providing a fast, reliable, and user-friendly solution. It empowers researchers and practitioners to quickly estimate parameter distributions and generate model predictions for new observations, facilitating efficient decision-making and advancing the state of uncertainty quantification in computational modeling. (The code and data are available at https://github.com/patrickfan/GenAI4UQ).