 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnify Graph Learning with Text: Unleashing LLM Potentials for Session Search
May 20, 2025Session search involves a series of interactive queries and actions to fulfill user's complex information need. Current strategies typically prioritize sequential modeling for deep semantic understanding, overlooking the graph structure in interactions. While some approaches focus on capturing structural information, they use a generalized representation for documents, neglecting the word-level semantic modeling. In this paper, we propose Symbolic Graph Ranker (SGR), which aims to take advantage of both text-based and graph-based approaches by leveraging the power of recent Large Language Models (LLMs). Concretely, we first introduce a set of symbolic grammar rules to convert session graph into text. This allows integrating session history, interaction process, and task instruction seamlessly as inputs for the LLM. Moreover, given the natural discrepancy between LLMs pre-trained on textual corpora, and the symbolic language we produce using our graph-to-text grammar, our objective is to enhance LLMs' ability to capture graph structures within a textual format. To achieve this, we introduce a set of self-supervised symbolic learning tasks including link prediction, node content generation, and generative contrastive learning, to enable LLMs to capture the topological information from coarse-grained to fine-grained. Experiment results and comprehensive analysis on two benchmark datasets, AOL and Tiangong-ST, confirm the superiority of our approach. Our paradigm also offers a novel and effective methodology that bridges the gap between traditional search strategies and modern LLMs.
Bridge the Gap between Past and Future: Siamese Model Optimization for Context-Aware Document Ranking
May 20, 2025In the realm of information retrieval, users often engage in multi-turn interactions with search engines to acquire information, leading to the formation of sequences of user feedback behaviors. Leveraging the session context has proven to be beneficial for inferring user search intent and document ranking. A multitude of approaches have been proposed to exploit in-session context for improved document ranking. Despite these advances, the limitation of historical session data for capturing evolving user intent remains a challenge. In this work, we explore the integration of future contextual information into the session context to enhance document ranking. We present the siamese model optimization framework, comprising a history-conditioned model and a future-aware model. The former processes only the historical behavior sequence, while the latter integrates both historical and anticipated future behaviors. Both models are trained collaboratively using the supervised labels and pseudo labels predicted by the other. The history-conditioned model, referred to as ForeRanker, progressively learns future-relevant information to enhance ranking, while it singly uses historical session at inference time. To mitigate inconsistencies during training, we introduce the peer knowledge distillation method with a dynamic gating mechanism, allowing models to selectively incorporate contextual information. Experimental results on benchmark datasets demonstrate the effectiveness of our ForeRanker, showcasing its superior performance compared to existing methods.
From 1,000,000 Users to Every User: Scaling Up Personalized Preference for User-level Alignment
Mar 21, 2025



Large language models (LLMs) have traditionally been aligned through one-size-fits-all approaches that assume uniform human preferences, fundamentally overlooking the diversity in user values and needs. This paper introduces a comprehensive framework for scalable personalized alignment of LLMs. We establish a systematic preference space characterizing psychological and behavioral dimensions, alongside diverse persona representations for robust preference inference in real-world scenarios. Building upon this foundation, we introduce \textsc{AlignX}, a large-scale dataset of over 1.3 million personalized preference examples, and develop two complementary alignment approaches: \textit{in-context alignment} directly conditioning on persona representations and \textit{preference-bridged alignment} modeling intermediate preference distributions. Extensive experiments demonstrate substantial improvements over existing methods, with an average 17.06\% accuracy gain across four benchmarks while exhibiting a strong adaptation capability to novel preferences, robustness to limited user data, and precise preference controllability. These results validate our framework's effectiveness, advancing toward truly user-adaptive AI systems.
PEAR: Position-Embedding-Agnostic Attention Re-weighting Enhances Retrieval-Augmented Generation with Zero Inference Overhead
Sep 29, 2024
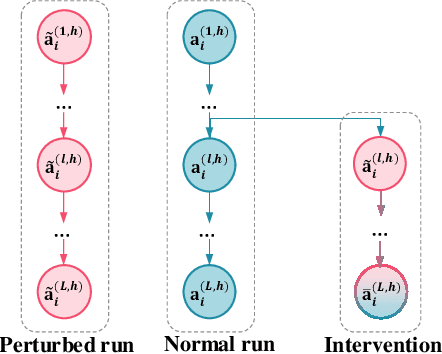
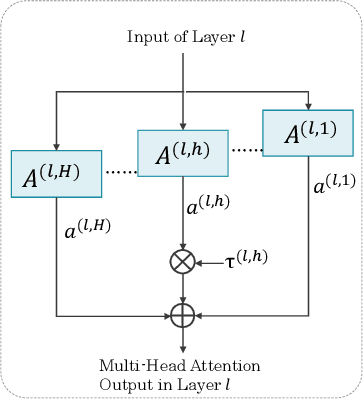

Large language models (LLMs) enhanced with retrieval-augmented generation (RAG) have introduced a new paradigm for web search. However, the limited context awareness of LLMs degrades their performance on RAG tasks. Existing methods to enhance context awareness are often inefficient, incurring time or memory overhead during inference, and many are tailored to specific position embeddings. In this paper, we propose Position-Embedding-Agnostic attention Re-weighting (PEAR), which enhances the context awareness of LLMs with zero inference overhead. Specifically, on a proxy task focused on context copying, we first detect heads which suppress the models' context awareness thereby diminishing RAG performance. To weaken the impact of these heads, we re-weight their outputs with learnable coefficients. The LLM (with frozen parameters) is optimized by adjusting these coefficients to minimize loss on the proxy task. As a result, the coefficients are optimized to values less than one, thereby reducing their tendency to suppress RAG performance. During inference, the optimized coefficients are fixed to re-weight these heads, regardless of the specific task at hand. Our proposed PEAR offers two major advantages over previous approaches: (1) It introduces zero additional inference overhead in terms of memory usage or inference time, while outperforming competitive baselines in accuracy and efficiency across various RAG tasks. (2) It is independent of position embedding algorithms, ensuring broader applicability.