 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of Parametric Injection-A Systematic Study of Parametric Retrieval-Augmented Generation
Oct 14, 2025



Retrieval-augmented generation (RAG) enhances large language models (LLMs) by retrieving external documents. As an emerging form of RAG, parametric retrieval-augmented generation (PRAG) encodes documents as model parameters (i.e., LoRA modules) and injects these representations into the model during inference, enabling interaction between the LLM and documents at parametric level. Compared with directly placing documents in the input context, PRAG is more efficient and has the potential to offer deeper model-document interaction. Despite its growing attention, the mechanism underlying parametric injection remains poorly understood. In this work, we present a systematic study of PRAG to clarify the role of parametric injection, showing that parameterized documents capture only partial semantic information of documents, and relying on them alone yields inferior performance compared to interaction at text level. However, these parametric representations encode high-level document information that can enhance the model's understanding of documents within the input context. When combined parameterized documents with textual documents, the model can leverage relevant information more effectively and become more robust to noisy inputs, achieving better performance than either source alone. We recommend jointly using parameterized and textual documents and advocate for increasing the information content of parametric representations to advance PRAG.
PEAR: Position-Embedding-Agnostic Attention Re-weighting Enhances Retrieval-Augmented Generation with Zero Inference Overhead
Sep 29, 2024
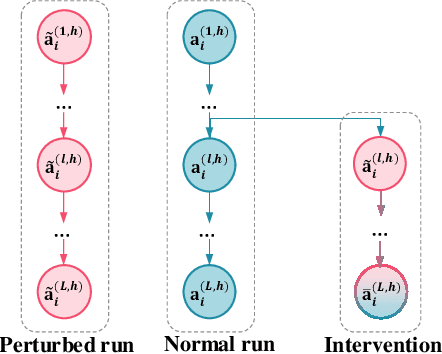
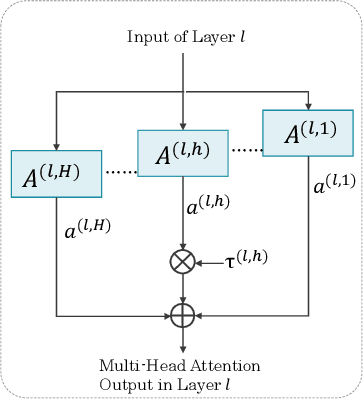

Large language models (LLMs) enhanced with retrieval-augmented generation (RAG) have introduced a new paradigm for web search. However, the limited context awareness of LLMs degrades their performance on RAG tasks. Existing methods to enhance context awareness are often inefficient, incurring time or memory overhead during inference, and many are tailored to specific position embeddings. In this paper, we propose Position-Embedding-Agnostic attention Re-weighting (PEAR), which enhances the context awareness of LLMs with zero inference overhead. Specifically, on a proxy task focused on context copying, we first detect heads which suppress the models' context awareness thereby diminishing RAG performance. To weaken the impact of these heads, we re-weight their outputs with learnable coefficients. The LLM (with frozen parameters) is optimized by adjusting these coefficients to minimize loss on the proxy task. As a result, the coefficients are optimized to values less than one, thereby reducing their tendency to suppress RAG performance. During inference, the optimized coefficients are fixed to re-weight these heads, regardless of the specific task at hand. Our proposed PEAR offers two major advantages over previous approaches: (1) It introduces zero additional inference overhead in terms of memory usage or inference time, while outperforming competitive baselines in accuracy and efficiency across various RAG tasks. (2) It is independent of position embedding algorithms, ensuring broader applicability.