 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoupling Experts and Routers in Mixture-of-Experts via an Auxiliary Loss
Dec 29, 2025Mixture-of-Experts (MoE) models lack explicit constraints to ensure the router's decisions align well with the experts' capabilities, which ultimately limits model performance. To address this, we propose expert-router coupling (ERC) loss, a lightweight auxiliary loss that tightly couples the router's decisions with expert capabilities. Our approach treats each expert's router embedding as a proxy token for the tokens assigned to that expert, and feeds perturbed router embeddings through the experts to obtain internal activations. The ERC loss enforces two constraints on these activations: (1) Each expert must exhibit higher activation for its own proxy token than for the proxy tokens of any other expert. (2) Each proxy token must elicit stronger activation from its corresponding expert than from any other expert. These constraints jointly ensure that each router embedding faithfully represents its corresponding expert's capability, while each expert specializes in processing the tokens actually routed to it. The ERC loss is computationally efficient, operating only on n^2 activations, where n is the number of experts. This represents a fixed cost independent of batch size, unlike prior coupling methods that scale with the number of tokens (often millions per batch). Through pre-training MoE-LLMs ranging from 3B to 15B parameters and extensive analysis on trillions of tokens, we demonstrate the effectiveness of the ERC loss. Moreover, the ERC loss offers flexible control and quantitative tracking of expert specialization levels during training, providing valuable insights into MoEs.
StepHint: Multi-level Stepwise Hints Enhance Reinforcement Learning to Reason
Jul 03, 2025Reinforcement learning with verifiable rewards (RLVR) is a promising approach for improving the complex reasoning abilities of large language models (LLMs). However, current RLVR methods face two significant challenges: the near-miss reward problem, where a small mistake can invalidate an otherwise correct reasoning process, greatly hindering training efficiency; and exploration stagnation, where models tend to focus on solutions within their ``comfort zone,'' lacking the motivation to explore potentially more effective alternatives. To address these challenges, we propose StepHint, a novel RLVR algorithm that utilizes multi-level stepwise hints to help models explore the solution space more effectively. StepHint generates valid reasoning chains from stronger models and partitions these chains into reasoning steps using our proposed adaptive partitioning method. The initial few steps are used as hints, and simultaneously, multiple-level hints (each comprising a different number of steps) are provided to the model. This approach directs the model's exploration toward a promising solution subspace while preserving its flexibility for independent exploration. By providing hints, StepHint mitigates the near-miss reward problem, thereby improving training efficiency. Additionally, the external reasoning pathways help the model develop better reasoning abilities, enabling it to move beyond its ``comfort zone'' and mitigate exploration stagnation. StepHint outperforms competitive RLVR enhancement methods across six mathematical benchmarks, while also demonstrating superior generalization and excelling over baselines on out-of-domain benchmarks.
The Climb Carves Wisdom Deeper Than the Summit: On the Noisy Rewards in Learning to Reason
May 28, 2025Recent studies on post-training large language models (LLMs) for reasoning through reinforcement learning (RL) typically focus on tasks that can be accurately verified and rewarded, such as solving math problems. In contrast, our research investigates the impact of reward noise, a more practical consideration for real-world scenarios involving the post-training of LLMs using reward models. We found that LLMs demonstrate strong robustness to substantial reward noise. For example, manually flipping 40% of the reward function's outputs in math tasks still allows a Qwen-2.5-7B model to achieve rapid convergence, improving its performance on math tasks from 5% to 72%, compared to the 75% accuracy achieved by a model trained with noiseless rewards. Surprisingly, by only rewarding the appearance of key reasoning phrases (namely reasoning pattern reward, RPR), such as ``first, I need to''-without verifying the correctness of answers, the model achieved peak downstream performance (over 70% accuracy for Qwen-2.5-7B) comparable to models trained with strict correctness verification and accurate rewards. Recognizing the importance of the reasoning process over the final results, we combined RPR with noisy reward models. RPR helped calibrate the noisy reward models, mitigating potential false negatives and enhancing the LLM's performance on open-ended tasks. These findings suggest the importance of improving models' foundational abilities during the pre-training phase while providing insights for advancing post-training techniques. Our code and scripts are available at https://github.com/trestad/Noisy-Rewards-in-Learning-to-Reason.
Divide-Fuse-Conquer: Eliciting "Aha Moments" in Multi-Scenario Games
May 22, 2025Large language models (LLMs) have been observed to suddenly exhibit advanced reasoning abilities during reinforcement learning (RL), resembling an ``aha moment'' triggered by simple outcome-based rewards. While RL has proven effective in eliciting such breakthroughs in tasks involving mathematics, coding, and vision, it faces significant challenges in multi-scenario games. The diversity of game rules, interaction modes, and environmental complexities often leads to policies that perform well in one scenario but fail to generalize to others. Simply combining multiple scenarios during training introduces additional challenges, such as training instability and poor performance. To overcome these challenges, we propose Divide-Fuse-Conquer, a framework designed to enhance generalization in multi-scenario RL. This approach starts by heuristically grouping games based on characteristics such as rules and difficulties. Specialized models are then trained for each group to excel at games in the group is what we refer to as the divide step. Next, we fuse model parameters from different groups as a new model, and continue training it for multiple groups, until the scenarios in all groups are conquered. Experiments across 18 TextArena games show that Qwen2.5-32B-Align trained with the Divide-Fuse-Conquer strategy reaches a performance level comparable to Claude3.5, achieving 7 wins and 4 draws. We hope our approach can inspire future research on using reinforcement learning to improve the generalization of LLMs.
More is not always better? Enhancing Many-Shot In-Context Learning with Differentiated and Reweighting Objectives
Jan 07, 2025



Large language models (LLMs) excel at few-shot in-context learning (ICL) without requiring parameter updates. However, as the number of ICL demonstrations increases from a few to many, performance tends to plateau and eventually decline. We identify two primary causes for this trend: the suboptimal negative log-likelihood (NLL) optimization objective and the incremental data noise. To address these issues, we introduce DR-ICL, a novel optimization method that enhances model performance through Differentiated Learning and advantage-based Reweighting objectives. Globally, DR-ICL utilizes differentiated learning to optimize the NLL objective, ensuring that many-shot performance surpasses zero-shot levels. Locally, it dynamically adjusts the weighting of many-shot demonstrations by leveraging cumulative advantages inspired by reinforcement learning, thereby improving generalization. This approach allows the model to handle varying numbers of shots effectively, mitigating the impact of noisy data. Recognizing the lack of multi-task datasets with diverse many-shot distributions, we develop the Many-Shot ICL Benchmark (MICLB)-a large-scale benchmark covering shot numbers from 1 to 350 within sequences of up to 8,000 tokens-for fine-tuning purposes. MICLB facilitates the evaluation of many-shot ICL strategies across seven prominent NLP tasks and 50 distinct datasets. Experimental results demonstrate that LLMs enhanced with DR-ICL achieve significant improvements in many-shot setups across various tasks, including both in-domain and out-of-domain scenarios. We release the code and benchmark dataset hoping to facilitate further research in many-shot ICL.
More Expressive Attention with Negative Weights
Nov 14, 2024We propose a novel attention mechanism, named Cog Attention, that enables attention weights to be negative for enhanced expressiveness, which stems from two key factors: (1) Cog Attention can shift the token deletion and copying function from a static OV matrix to dynamic QK inner products, with the OV matrix now focusing more on refinement or modification. The attention head can simultaneously delete, copy, or retain tokens by assigning them negative, positive, or minimal attention weights, respectively. As a result, a single attention head becomes more flexible and expressive. (2) Cog Attention improves the model's robustness against representational collapse, which can occur when earlier tokens are over-squashed into later positions, leading to homogeneous representations. Negative weights reduce effective information paths from earlier to later tokens, helping to mitigate this issue. We develop Transformer-like models which use Cog Attention as attention modules, including decoder-only models for language modeling and U-ViT diffusion models for image generation. Experiments show that models using Cog Attention exhibit superior performance compared to those employing traditional softmax attention modules. Our approach suggests a promising research direction for rethinking and breaking the entrenched constraints of traditional softmax attention, such as the requirement for non-negative weights.
HoPE: A Novel Positional Encoding Without Long-Term Decay for Enhanced Context Awareness and Extrapolation
Oct 28, 2024



Many positional encodings (PEs) are designed to exhibit long-term decay, based on an entrenched and long-standing inductive opinion: tokens farther away from the current position carry less relevant information. We argue that long-term decay is outdated in the era of LLMs, as LLMs are now applied to tasks demanding precise retrieval of in-context information from arbitrary positions. Firstly, we present empirical analyses on various PEs, demonstrating that models inherently learn attention with only a local-decay pattern while forming a U-shape pattern globally, contradicting the principle of long-term decay. Furthermore, we conduct a detailed analysis of rotary position encoding (RoPE, a prevalent relative positional encoding in LLMs), and found that the U-shape attention is caused by some learned components, which are also the key factor limiting RoPE's expressiveness and extrapolation.Inspired by these insights, we propose High-frequency rotary Position Encoding (HoPE). HoPE replaces the specific components in RoPE with position-independent ones, retaining only high-frequency signals, which also breaks the principle of long-term decay in theory. HoPE achieves two major advantages: (1) Without constraints imposed by long-term decay, contradictory factors that limit spontaneous attention optimization and model extrapolation performance are removed. (2) Components representing positions and semantics are are optimized. These enhances model's context awareness and extrapolation, as validated by extensive experiments.
PEAR: Position-Embedding-Agnostic Attention Re-weighting Enhances Retrieval-Augmented Generation with Zero Inference Overhead
Sep 29, 2024
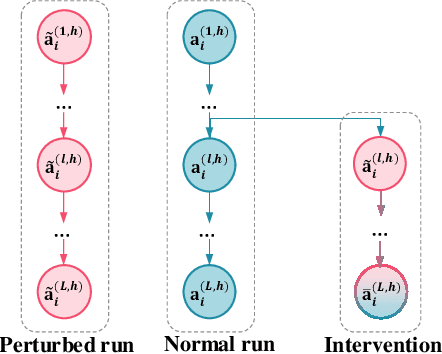
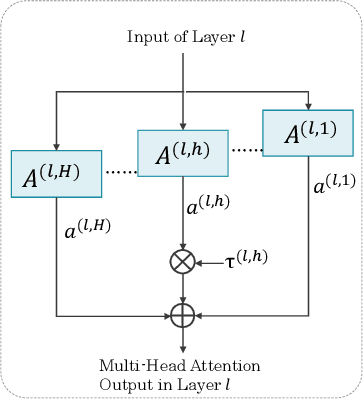

Large language models (LLMs) enhanced with retrieval-augmented generation (RAG) have introduced a new paradigm for web search. However, the limited context awareness of LLMs degrades their performance on RAG tasks. Existing methods to enhance context awareness are often inefficient, incurring time or memory overhead during inference, and many are tailored to specific position embeddings. In this paper, we propose Position-Embedding-Agnostic attention Re-weighting (PEAR), which enhances the context awareness of LLMs with zero inference overhead. Specifically, on a proxy task focused on context copying, we first detect heads which suppress the models' context awareness thereby diminishing RAG performance. To weaken the impact of these heads, we re-weight their outputs with learnable coefficients. The LLM (with frozen parameters) is optimized by adjusting these coefficients to minimize loss on the proxy task. As a result, the coefficients are optimized to values less than one, thereby reducing their tendency to suppress RAG performance. During inference, the optimized coefficients are fixed to re-weight these heads, regardless of the specific task at hand. Our proposed PEAR offers two major advantages over previous approaches: (1) It introduces zero additional inference overhead in terms of memory usage or inference time, while outperforming competitive baselines in accuracy and efficiency across various RAG tasks. (2) It is independent of position embedding algorithms, ensuring broader applicability.
Language Models "Grok" to Copy
Sep 14, 2024We examine the pre-training dynamics of language models, focusing on their ability to copy text from preceding context--a fundamental skill for various LLM applications, including in-context learning (ICL) and retrieval-augmented generation (RAG). We propose a novel perspective that Transformer-based language models develop copying abilities similarly to grokking, which refers to sudden generalization on test set long after the model fit to the training set. Our experiments yield three arguments: (1) The pre-training loss decreases rapidly, while the context copying ability of models initially lags and then abruptly saturates. (2) The speed of developing copying ability is independent of the number of tokens trained, similarly to how grokking speed is unaffected by dataset size as long as the data distribution is preserved. (3) Induction heads, the attention heads responsible for copying, form from shallow to deep layers during training, mirroring the development of circuits in deeper layers during grokking. We contend that the connection between grokking and context copying can provide valuable insights for more effective language model training, ultimately improving in-context performance. For example, we demonstrated that techniques that enhance grokking, such as regularization, either accelerate or enhance the development of context copying.
Mixture-of-Modules: Reinventing Transformers as Dynamic Assemblies of Modules
Jul 09, 2024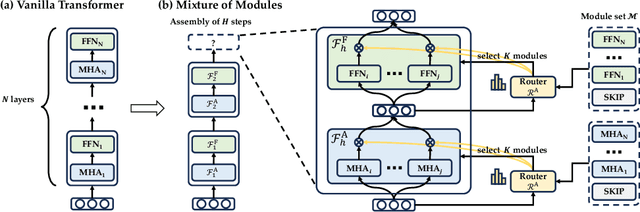
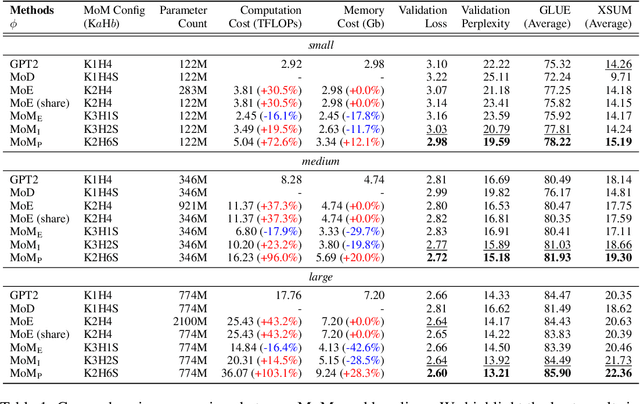
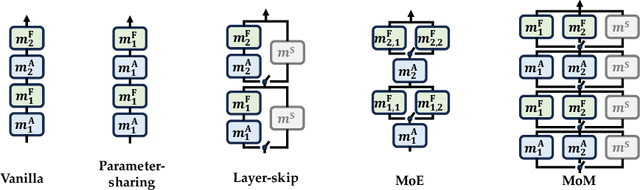
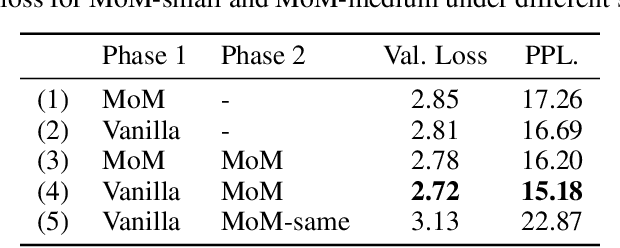
Is it always necessary to compute tokens from shallow to deep layers in Transformers? The continued success of vanilla Transformers and their variants suggests an undoubted "yes". In this work, however, we attempt to break the depth-ordered convention by proposing a novel architecture dubbed mixture-of-modules (MoM), which is motivated by an intuition that any layer, regardless of its position, can be used to compute a token as long as it possesses the needed processing capabilities. The construction of MoM starts from a finite set of modules defined by multi-head attention and feed-forward networks, each distinguished by its unique parameterization. Two routers then iteratively select attention modules and feed-forward modules from the set to process a token. The selection dynamically expands the computation graph in the forward pass of the token, culminating in an assembly of modules. We show that MoM provides not only a unified framework for Transformers and their numerous variants but also a flexible and learnable approach for reducing redundancy in Transformer parameterization. We pre-train various MoMs using OpenWebText. Empirical results demonstrate that MoMs, of different parameter counts, consistently outperform vanilla transformers on both GLUE and XSUM benchmarks. More interestingly, with a fixed parameter budget, MoM-large enables an over 38% increase in depth for computation graphs compared to GPT-2-large, resulting in absolute gains of 1.4 on GLUE and 1 on XSUM. On the other hand, MoM-large also enables an over 60% reduction in depth while involving more modules per layer, yielding a 16% reduction in TFLOPs and a 43% decrease in memory usage compared to GPT-2-large, while maintaining comparable performance.