 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChronos: Learning Temporal Dynamics of Reasoning Chains for Test-Time Scaling
Feb 01, 2026Test-Time Scaling (TTS) has emerged as an effective paradigm for improving the reasoning performance of large language models (LLMs). However, existing methods -- most notably majority voting and heuristic token-level scoring -- treat reasoning traces or tokens equally, thereby being susceptible to substantial variations in trajectory quality and localized logical failures. In this work, we introduce \textbf{Chronos}, a lightweight and plug-and-play chronological reasoning scorer that models each trajectory as a time series. Specifically, Chronos learns to capture trajectory features of token probabilities, assigns quality scores accordingly, and employs a weighted voting mechanism. Extensive evaluations on both in-domain and out-of-domain benchmarks demonstrate that Chronos consistently delivers substantial gains across a variety of models, with negligible computational overhead. Notably, Chronos@128 achieves relative improvements of 34.21\% over Pass@1 and 22.70\% over Maj@128 on HMMT25 using Qwen3-4B-Thinking-2507, highlighting its effectiveness.
Interpretable Reward Model via Sparse Autoencoder
Aug 12, 2025Large language models (LLMs) have been widely deployed across numerous fields. Reinforcement Learning from Human Feedback (RLHF) leverages reward models (RMs) as proxies for human preferences to align LLM behaviors with human values, making the accuracy, reliability, and interpretability of RMs critical for effective alignment. However, traditional RMs lack interpretability, offer limited insight into the reasoning behind reward assignments, and are inflexible toward user preference shifts. While recent multidimensional RMs aim for improved interpretability, they often fail to provide feature-level attribution and require costly annotations. To overcome these limitations, we introduce the Sparse Autoencoder-enhanced Reward Model (\textbf{SARM}), a novel architecture that integrates a pretrained Sparse Autoencoder (SAE) into a reward model. SARM maps the hidden activations of LLM-based RM into an interpretable, sparse, and monosemantic feature space, from which a scalar head aggregates feature activations to produce transparent and conceptually meaningful reward scores. Empirical evaluations demonstrate that SARM facilitates direct feature-level attribution of reward assignments, allows dynamic adjustment to preference shifts, and achieves superior alignment performance compared to conventional reward models. Our code is available at https://github.com/schrieffer-z/sarm.
PatchRec: Multi-Grained Patching for Efficient LLM-based Sequential Recommendation
Jan 25, 2025Large Language Models for sequential recommendation (LLM4SR), which transform user-item interactions into language modeling, have shown promising results. However, due to the limitations of context window size and the computational costs associated with Large Language Models (LLMs), current approaches primarily truncate user history by only considering the textual information of items from the most recent interactions in the input prompt. This truncation fails to fully capture the long-term behavioral patterns of users. To address this, we propose a multi-grained patching framework -- PatchRec. It compresses the textual tokens of an item title into a compact item patch, and further compresses multiple item patches into a denser session patch, with earlier interactions being compressed to a greater degree. The framework consists of two stages: (1) Patch Pre-training, which familiarizes LLMs with item-level compression patterns, and (2) Patch Fine-tuning, which teaches LLMs to model sequences at multiple granularities. Through this simple yet effective approach, empirical results demonstrate that PatchRec outperforms existing methods, achieving significant performance gains with fewer tokens fed to the LLM. Specifically, PatchRec shows up to a 32% improvement in HR@20 on the Goodreads dataset over uncompressed baseline, while using only 7% of the tokens. This multi-grained sequence modeling paradigm, with an adjustable compression ratio, enables LLMs to be efficiently deployed in real-world recommendation systems that handle extremely long user behavior sequences.
More Expressive Attention with Negative Weights
Nov 14, 2024We propose a novel attention mechanism, named Cog Attention, that enables attention weights to be negative for enhanced expressiveness, which stems from two key factors: (1) Cog Attention can shift the token deletion and copying function from a static OV matrix to dynamic QK inner products, with the OV matrix now focusing more on refinement or modification. The attention head can simultaneously delete, copy, or retain tokens by assigning them negative, positive, or minimal attention weights, respectively. As a result, a single attention head becomes more flexible and expressive. (2) Cog Attention improves the model's robustness against representational collapse, which can occur when earlier tokens are over-squashed into later positions, leading to homogeneous representations. Negative weights reduce effective information paths from earlier to later tokens, helping to mitigate this issue. We develop Transformer-like models which use Cog Attention as attention modules, including decoder-only models for language modeling and U-ViT diffusion models for image generation. Experiments show that models using Cog Attention exhibit superior performance compared to those employing traditional softmax attention modules. Our approach suggests a promising research direction for rethinking and breaking the entrenched constraints of traditional softmax attention, such as the requirement for non-negative weights.
RosePO: Aligning LLM-based Recommenders with Human Values
Oct 16, 2024
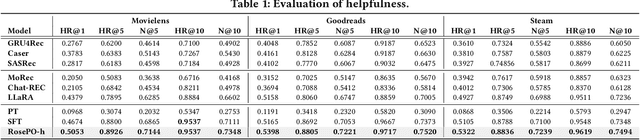
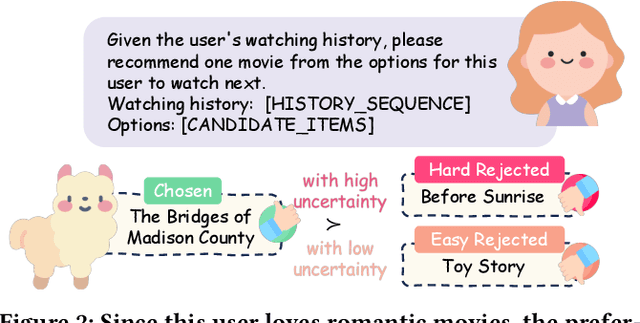

Recently, there has been a growing interest in leveraging Large Language Models (LLMs) for recommendation systems, which usually adapt a pre-trained LLM to the recommendation scenario through supervised fine-tuning (SFT). However, both the pre-training and SFT stages fail to explicitly model the comparative relationships of a user's preferences on different items. To construct a "helpful and harmless" LLM-based recommender, we propose a general framework -- Recommendation with smoothing personalized Preference Optimization (RosePO), which better aligns with customized human values during the post-training stage. Specifically, in addition to the input and chosen response that naturally align with SFT data, we design a rejected sampling strategy tailored for enhancing helpfulness, along with two strategies aimed at mitigating biases to promote harmlessness. To ensure robustness against uncertain labels present in automatically constructed preference data, we introduce a personalized smoothing factor predicted by a preference oracle into the optimization objective. Evaluation on three real-world datasets demonstrates the effectiveness of our method, showcasing not only improved recommendation performance but also mitigation of semantic hallucination and popularity bias.
LLaRA: Aligning Large Language Models with Sequential Recommenders
Dec 05, 2023Sequential recommendation aims to predict the subsequent items matching user preference based on her/his historical interactions. With the development of Large Language Models (LLMs), there is growing interest in exploring the potential of LLMs for sequential recommendation by framing it as a language modeling task. Prior works represent items in the textual prompts using either ID indexing or text indexing and feed the prompts into LLMs, but falling short of either encapsulating comprehensive world knowledge or exhibiting sufficient sequential understanding. To harness the complementary strengths of traditional recommenders (which encode user behavioral knowledge) and LLMs (which possess world knowledge about items), we propose LLaRA -- a Large Language and Recommendation Assistant framework. Specifically, LLaRA represents items in LLM's input prompts using a novel hybrid approach that integrates ID-based item embeddings from traditional recommenders with textual item features. Viewing the ``sequential behavior of the user'' as a new modality in recommendation, we employ an adapter to bridge the modality gap between ID embeddings of the traditional recommenders and the input space of LLMs. Furthermore, instead of directly exposing the hybrid prompt to LLMs, we apply a curriculum learning approach to gradually ramp up training complexity. We first warm up the LLM with text-only prompting, which aligns more naturally with the LLM's language modeling capabilities. Thereafter, we progressively transition to hybrid prompting, training the adapter to incorporate behavioral knowledge from the traditional sequential recommender into the LLM. Extensive experiments demonstrate the efficacy of LLaRA framework. Our code and data are available at https://github.com/ljy0ustc/LLaRA .
Text-to-Image Generation for Abstract Concepts
Sep 27, 2023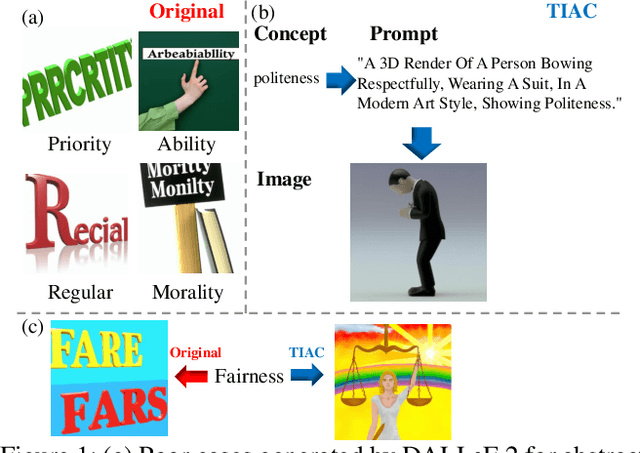
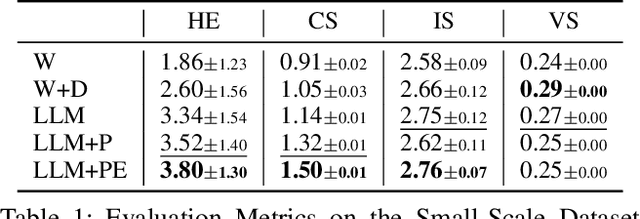
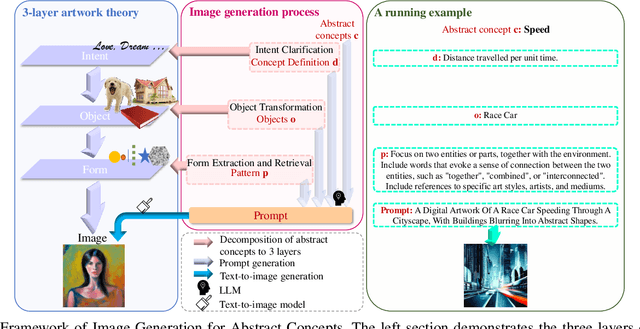
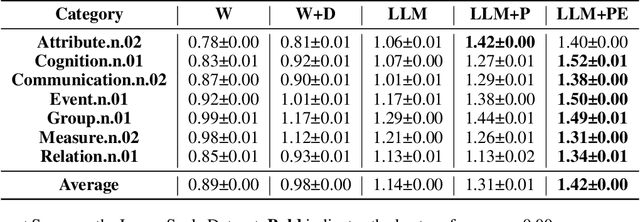
Recent years have witnessed the substantial progress of large-scale models across various domains, such as natural language processing and computer vision, facilitating the expression of concrete concepts. Unlike concrete concepts that are usually directly associated with physical objects, expressing abstract concepts through natural language requires considerable effort, which results from their intricate semantics and connotations. An alternative approach is to leverage images to convey rich visual information as a supplement. Nevertheless, existing Text-to-Image (T2I) models are primarily trained on concrete physical objects and tend to fail to visualize abstract concepts. Inspired by the three-layer artwork theory that identifies critical factors, intent, object and form during artistic creation, we propose a framework of Text-to-Image generation for Abstract Concepts (TIAC). The abstract concept is clarified into a clear intent with a detailed definition to avoid ambiguity. LLMs then transform it into semantic-related physical objects, and the concept-dependent form is retrieved from an LLM-extracted form pattern set. Information from these three aspects will be integrated to generate prompts for T2I models via LLM. Evaluation results from human assessments and our newly designed metric concept score demonstrate the effectiveness of our framework in creating images that can sufficiently express abstract concepts.