 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Dense, Not Long: Dynamic Decoupled Conditional Advantage for Efficient Reasoning
Feb 02, 2026Reinforcement Learning with Verifiable Rewards (RLVR) can elicit strong multi-step reasoning, yet it often encourages overly verbose traces. Moreover, naive length penalties in group-relative optimization can severely hurt accuracy. We attribute this failure to two structural issues: (i) Dilution of Length Baseline, where incorrect responses (with zero length reward) depress the group baseline and over-penalize correct solutions; and (ii) Difficulty-Penalty Mismatch, where a static penalty cannot adapt to problem difficulty, suppressing necessary reasoning on hard instances while leaving redundancy on easy ones. We propose Dynamic Decoupled Conditional Advantage (DDCA) to decouple efficiency optimization from correctness. DDCA computes length advantages conditionally within the correct-response cluster to eliminate baseline dilution, and dynamically scales the penalty strength using the group pass rate as a proxy for difficulty. Experiments on GSM8K, MATH500, AMC23, and AIME25 show that DDCA consistently improves the efficiency--accuracy trade-off relative to adaptive baselines, reducing generated tokens by approximately 60% on simpler tasks (e.g., GSM8K) versus over 20% on harder benchmarks (e.g., AIME25), thereby maintaining or improving accuracy. Code is available at https://github.com/alphadl/DDCA.
DSAEval: Evaluating Data Science Agents on a Wide Range of Real-World Data Science Problems
Jan 20, 2026Recent LLM-based data agents aim to automate data science tasks ranging from data analysis to deep learning. However, the open-ended nature of real-world data science problems, which often span multiple taxonomies and lack standard answers, poses a significant challenge for evaluation. To address this, we introduce DSAEval, a benchmark comprising 641 real-world data science problems grounded in 285 diverse datasets, covering both structured and unstructured data (e.g., vision and text). DSAEval incorporates three distinctive features: (1) Multimodal Environment Perception, which enables agents to interpret observations from multiple modalities including text and vision; (2) Multi-Query Interactions, which mirror the iterative and cumulative nature of real-world data science projects; and (3) Multi-Dimensional Evaluation, which provides a holistic assessment across reasoning, code, and results. We systematically evaluate 11 advanced agentic LLMs using DSAEval. Our results show that Claude-Sonnet-4.5 achieves the strongest overall performance, GPT-5.2 is the most efficient, and MiMo-V2-Flash is the most cost-effective. We further demonstrate that multimodal perception consistently improves performance on vision-related tasks, with gains ranging from 2.04% to 11.30%. Overall, while current data science agents perform well on structured data and routine data anlysis workflows, substantial challenges remain in unstructured domains. Finally, we offer critical insights and outline future research directions to advance the development of data science agents.
Magnitude-Modulated Equivariant Adapter for Parameter-Efficient Fine-Tuning of Equivariant Graph Neural Networks
Nov 10, 2025Pretrained equivariant graph neural networks based on spherical harmonics offer efficient and accurate alternatives to computationally expensive ab-initio methods, yet adapting them to new tasks and chemical environments still requires fine-tuning. Conventional parameter-efficient fine-tuning (PEFT) techniques, such as Adapters and LoRA, typically break symmetry, making them incompatible with those equivariant architectures. ELoRA, recently proposed, is the first equivariant PEFT method. It achieves improved parameter efficiency and performance on many benchmarks. However, the relatively high degrees of freedom it retains within each tensor order can still perturb pretrained feature distributions and ultimately degrade performance. To address this, we present Magnitude-Modulated Equivariant Adapter (MMEA), a novel equivariant fine-tuning method which employs lightweight scalar gating to modulate feature magnitudes on a per-order and per-multiplicity basis. We demonstrate that MMEA preserves strict equivariance and, across multiple benchmarks, consistently improves energy and force predictions to state-of-the-art levels while training fewer parameters than competing approaches. These results suggest that, in many practical scenarios, modulating channel magnitudes is sufficient to adapt equivariant models to new chemical environments without breaking symmetry, pointing toward a new paradigm for equivariant PEFT design.
Accelerating RLHF Training with Reward Variance Increase
May 29, 2025Reinforcement learning from human feedback (RLHF) is an essential technique for ensuring that large language models (LLMs) are aligned with human values and preferences during the post-training phase. As an effective RLHF approach, group relative policy optimization (GRPO) has demonstrated success in many LLM-based applications. However, efficient GRPO-based RLHF training remains a challenge. Recent studies reveal that a higher reward variance of the initial policy model leads to faster RLHF training. Inspired by this finding, we propose a practical reward adjustment model to accelerate RLHF training by provably increasing the reward variance and preserving the relative preferences and reward expectation. Our reward adjustment method inherently poses a nonconvex optimization problem, which is NP-hard to solve in general. To overcome the computational challenges, we design a novel $O(n \log n)$ algorithm to find a global solution of the nonconvex reward adjustment model by explicitly characterizing the extreme points of the feasible set. As an important application, we naturally integrate this reward adjustment model into the GRPO algorithm, leading to a more efficient GRPO with reward variance increase (GRPOVI) algorithm for RLHF training. As an interesting byproduct, we provide an indirect explanation for the empirical effectiveness of GRPO with rule-based reward for RLHF training, as demonstrated in DeepSeek-R1. Experiment results demonstrate that the GRPOVI algorithm can significantly improve the RLHF training efficiency compared to the original GRPO algorithm.
Addressing Missing Data Issue for Diffusion-based Recommendation
May 18, 2025Diffusion models have shown significant potential in generating oracle items that best match user preference with guidance from user historical interaction sequences. However, the quality of guidance is often compromised by unpredictable missing data in observed sequence, leading to suboptimal item generation. Since missing data is uncertain in both occurrence and content, recovering it is impractical and may introduce additional errors. To tackle this challenge, we propose a novel dual-side Thompson sampling-based Diffusion Model (TDM), which simulates extra missing data in the guidance signals and allows diffusion models to handle existing missing data through extrapolation. To preserve user preference evolution in sequences despite extra missing data, we introduce Dual-side Thompson Sampling to implement simulation with two probability models, sampling by exploiting user preference from both item continuity and sequence stability. TDM strategically removes items from sequences based on dual-side Thompson sampling and treats these edited sequences as guidance for diffusion models, enhancing models' robustness to missing data through consistency regularization. Additionally, to enhance the generation efficiency, TDM is implemented under the denoising diffusion implicit models to accelerate the reverse process. Extensive experiments and theoretical analysis validate the effectiveness of TDM in addressing missing data in sequential recommendations.
Enhancing Input-Label Mapping in In-Context Learning with Contrastive Decoding
Feb 19, 2025Large language models (LLMs) excel at a range of tasks through in-context learning (ICL), where only a few task examples guide their predictions. However, prior research highlights that LLMs often overlook input-label mapping information in ICL, relying more on their pre-trained knowledge. To address this issue, we introduce In-Context Contrastive Decoding (ICCD), a novel method that emphasizes input-label mapping by contrasting the output distributions between positive and negative in-context examples. Experiments on 7 natural language understanding (NLU) tasks show that our ICCD method brings consistent and significant improvement (up to +2.1 improvement on average) upon 6 different scales of LLMs without requiring additional training. Our approach is versatile, enhancing performance with various demonstration selection methods, demonstrating its broad applicability and effectiveness. The code and scripts will be publicly released.
A Survey on Large Language Model-based Agents for Statistics and Data Science
Dec 18, 2024In recent years, data science agents powered by Large Language Models (LLMs), known as "data agents," have shown significant potential to transform the traditional data analysis paradigm. This survey provides an overview of the evolution, capabilities, and applications of LLM-based data agents, highlighting their role in simplifying complex data tasks and lowering the entry barrier for users without related expertise. We explore current trends in the design of LLM-based frameworks, detailing essential features such as planning, reasoning, reflection, multi-agent collaboration, user interface, knowledge integration, and system design, which enable agents to address data-centric problems with minimal human intervention. Furthermore, we analyze several case studies to demonstrate the practical applications of various data agents in real-world scenarios. Finally, we identify key challenges and propose future research directions to advance the development of data agents into intelligent statistical analysis software.
One Shot, One Talk: Whole-body Talking Avatar from a Single Image
Dec 02, 2024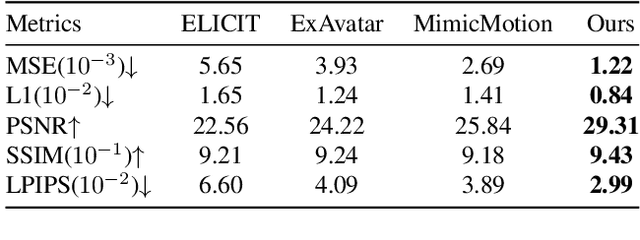
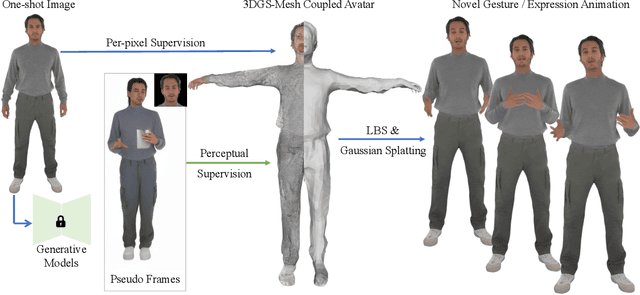
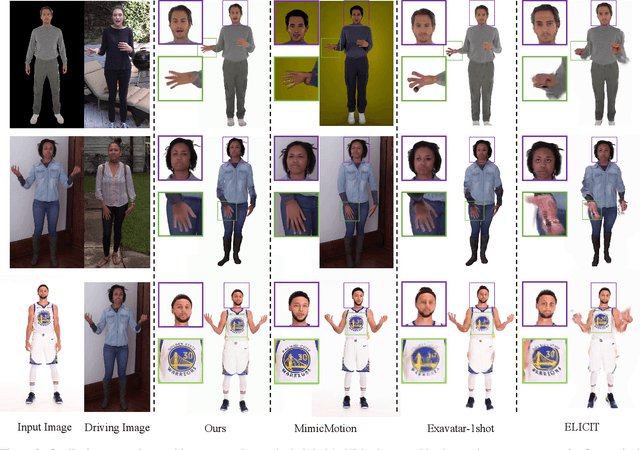

Building realistic and animatable avatars still requires minutes of multi-view or monocular self-rotating videos, and most methods lack precise control over gestures and expressions. To push this boundary, we address the challenge of constructing a whole-body talking avatar from a single image. We propose a novel pipeline that tackles two critical issues: 1) complex dynamic modeling and 2) generalization to novel gestures and expressions. To achieve seamless generalization, we leverage recent pose-guided image-to-video diffusion models to generate imperfect video frames as pseudo-labels. To overcome the dynamic modeling challenge posed by inconsistent and noisy pseudo-videos, we introduce a tightly coupled 3DGS-mesh hybrid avatar representation and apply several key regularizations to mitigate inconsistencies caused by imperfect labels. Extensive experiments on diverse subjects demonstrate that our method enables the creation of a photorealistic, precisely animatable, and expressive whole-body talking avatar from just a single image.
Unified Parameter-Efficient Unlearning for LLMs
Nov 30, 2024



The advent of Large Language Models (LLMs) has revolutionized natural language processing, enabling advanced understanding and reasoning capabilities across a variety of tasks. Fine-tuning these models for specific domains, particularly through Parameter-Efficient Fine-Tuning (PEFT) strategies like LoRA, has become a prevalent practice due to its efficiency. However, this raises significant privacy and security concerns, as models may inadvertently retain and disseminate sensitive or undesirable information. To address these issues, we introduce a novel instance-wise unlearning framework, LLMEraser, which systematically categorizes unlearning tasks and applies precise parameter adjustments using influence functions. Unlike traditional unlearning techniques that are often limited in scope and require extensive retraining, LLMEraser is designed to handle a broad spectrum of unlearning tasks without compromising model performance. Extensive experiments on benchmark datasets demonstrate that LLMEraser excels in efficiently managing various unlearning scenarios while maintaining the overall integrity and efficacy of the models.
RosePO: Aligning LLM-based Recommenders with Human Values
Oct 16, 2024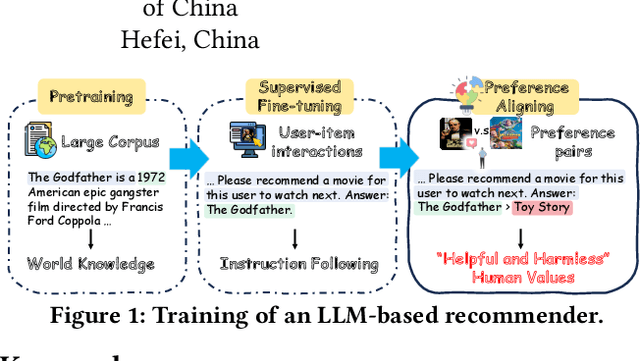
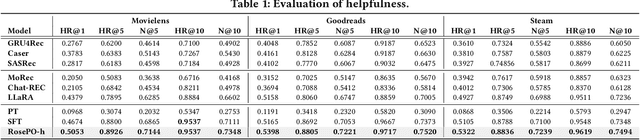
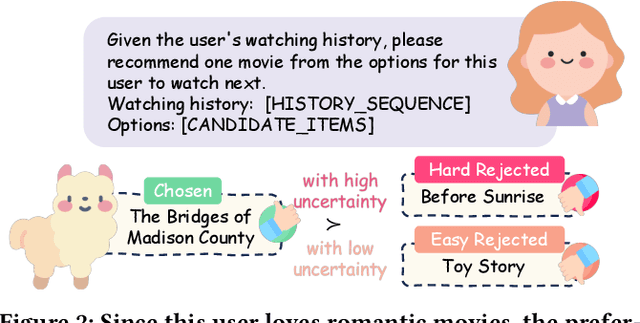

Recently, there has been a growing interest in leveraging Large Language Models (LLMs) for recommendation systems, which usually adapt a pre-trained LLM to the recommendation scenario through supervised fine-tuning (SFT). However, both the pre-training and SFT stages fail to explicitly model the comparative relationships of a user's preferences on different items. To construct a "helpful and harmless" LLM-based recommender, we propose a general framework -- Recommendation with smoothing personalized Preference Optimization (RosePO), which better aligns with customized human values during the post-training stage. Specifically, in addition to the input and chosen response that naturally align with SFT data, we design a rejected sampling strategy tailored for enhancing helpfulness, along with two strategies aimed at mitigating biases to promote harmlessness. To ensure robustness against uncertain labels present in automatically constructed preference data, we introduce a personalized smoothing factor predicted by a preference oracle into the optimization objective. Evaluation on three real-world datasets demonstrates the effectiveness of our method, showcasing not only improved recommendation performance but also mitigation of semantic hallucination and popularity bias.