 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRosePO: Aligning LLM-based Recommenders with Human Values
Paper and Code
Oct 16, 2024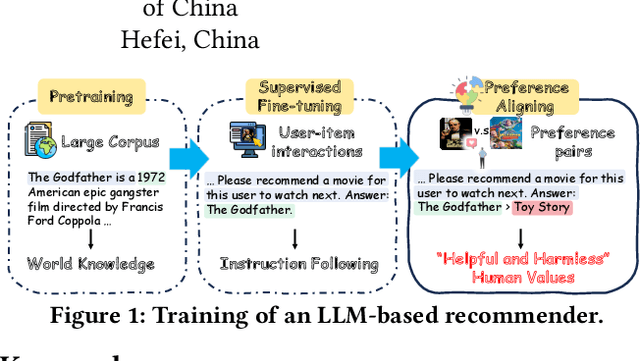
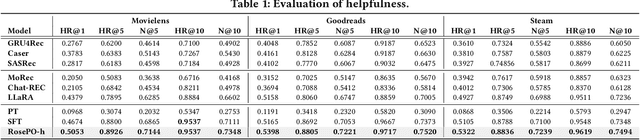
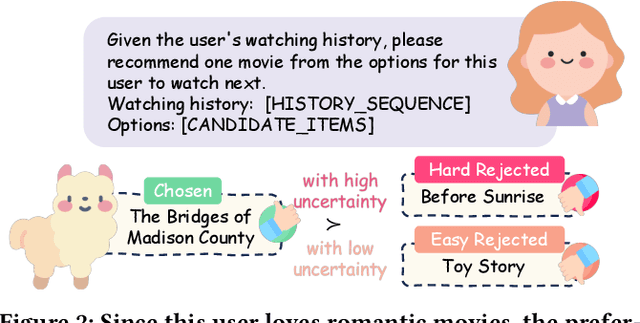

Recently, there has been a growing interest in leveraging Large Language Models (LLMs) for recommendation systems, which usually adapt a pre-trained LLM to the recommendation scenario through supervised fine-tuning (SFT). However, both the pre-training and SFT stages fail to explicitly model the comparative relationships of a user's preferences on different items. To construct a "helpful and harmless" LLM-based recommender, we propose a general framework -- Recommendation with smoothing personalized Preference Optimization (RosePO), which better aligns with customized human values during the post-training stage. Specifically, in addition to the input and chosen response that naturally align with SFT data, we design a rejected sampling strategy tailored for enhancing helpfulness, along with two strategies aimed at mitigating biases to promote harmlessness. To ensure robustness against uncertain labels present in automatically constructed preference data, we introduce a personalized smoothing factor predicted by a preference oracle into the optimization objective. Evaluation on three real-world datasets demonstrates the effectiveness of our method, showcasing not only improved recommendation performance but also mitigation of semantic hallucination and popularity bias.