 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink before Recommendation: Autonomous Reasoning-enhanced Recommender
Oct 27, 2025The core task of recommender systems is to learn user preferences from historical user-item interactions. With the rapid development of large language models (LLMs), recent research has explored leveraging the reasoning capabilities of LLMs to enhance rating prediction tasks. However, existing distillation-based methods suffer from limitations such as the teacher model's insufficient recommendation capability, costly and static supervision, and superficial transfer of reasoning ability. To address these issues, this paper proposes RecZero, a reinforcement learning (RL)-based recommendation paradigm that abandons the traditional multi-model and multi-stage distillation approach. Instead, RecZero trains a single LLM through pure RL to autonomously develop reasoning capabilities for rating prediction. RecZero consists of two key components: (1) "Think-before-Recommendation" prompt construction, which employs a structured reasoning template to guide the model in step-wise analysis of user interests, item features, and user-item compatibility; and (2) rule-based reward modeling, which adopts group relative policy optimization (GRPO) to compute rewards for reasoning trajectories and optimize the LLM. Additionally, the paper explores a hybrid paradigm, RecOne, which combines supervised fine-tuning with RL, initializing the model with cold-start reasoning samples and further optimizing it with RL. Experimental results demonstrate that RecZero and RecOne significantly outperform existing baseline methods on multiple benchmark datasets, validating the superiority of the RL paradigm in achieving autonomous reasoning-enhanced recommender systems.
Quantile Advantage Estimation for Entropy-Safe Reasoning
Sep 26, 2025Reinforcement Learning with Verifiable Rewards (RLVR) strengthens LLM reasoning, but training often oscillates between {entropy collapse} and {entropy explosion}. We trace both hazards to the mean baseline used in value-free RL (e.g., GRPO and DAPO), which improperly penalizes negative-advantage samples under reward outliers. We propose {Quantile Advantage Estimation} (QAE), replacing the mean with a group-wise K-quantile baseline. QAE induces a response-level, two-regime gate: on hard queries (p <= 1 - K) it reinforces rare successes, while on easy queries (p > 1 - K) it targets remaining failures. Under first-order softmax updates, we prove {two-sided entropy safety}, giving lower and upper bounds on one-step entropy change that curb explosion and prevent collapse. Empirically, this minimal modification stabilizes entropy, sparsifies credit assignment (with tuned K, roughly 80% of responses receive zero advantage), and yields sustained pass@1 gains on Qwen3-8B/14B-Base across AIME 2024/2025 and AMC 2023. These results identify {baseline design} -- rather than token-level heuristics -- as the primary mechanism for scaling RLVR.
Addressing Missing Data Issue for Diffusion-based Recommendation
May 18, 2025Diffusion models have shown significant potential in generating oracle items that best match user preference with guidance from user historical interaction sequences. However, the quality of guidance is often compromised by unpredictable missing data in observed sequence, leading to suboptimal item generation. Since missing data is uncertain in both occurrence and content, recovering it is impractical and may introduce additional errors. To tackle this challenge, we propose a novel dual-side Thompson sampling-based Diffusion Model (TDM), which simulates extra missing data in the guidance signals and allows diffusion models to handle existing missing data through extrapolation. To preserve user preference evolution in sequences despite extra missing data, we introduce Dual-side Thompson Sampling to implement simulation with two probability models, sampling by exploiting user preference from both item continuity and sequence stability. TDM strategically removes items from sequences based on dual-side Thompson sampling and treats these edited sequences as guidance for diffusion models, enhancing models' robustness to missing data through consistency regularization. Additionally, to enhance the generation efficiency, TDM is implemented under the denoising diffusion implicit models to accelerate the reverse process. Extensive experiments and theoretical analysis validate the effectiveness of TDM in addressing missing data in sequential recommendations.
AdaViP: Aligning Multi-modal LLMs via Adaptive Vision-enhanced Preference Optimization
Apr 22, 2025Preference alignment through Direct Preference Optimization (DPO) has demonstrated significant effectiveness in aligning multimodal large language models (MLLMs) with human preferences. However, existing methods focus primarily on language preferences while neglecting the critical visual context. In this paper, we propose an Adaptive Vision-enhanced Preference optimization (AdaViP) that addresses these limitations through two key innovations: (1) vision-based preference pair construction, which integrates multiple visual foundation models to strategically remove key visual elements from the image, enhancing MLLMs' sensitivity to visual details; and (2) adaptive preference optimization that dynamically balances vision- and language-based preferences for more accurate alignment. Extensive evaluations across different benchmarks demonstrate our effectiveness. Notably, our AdaViP-7B achieves 93.7% and 96.4% reductions in response-level and mentioned-level hallucination respectively on the Object HalBench, significantly outperforming current state-of-the-art methods.
RePO: ReLU-based Preference Optimization
Mar 10, 2025Aligning large language models (LLMs) with human preferences is critical for real-world deployment, yet existing methods like RLHF face computational and stability challenges. While DPO establishes an offline paradigm with single hyperparameter $\beta$, subsequent methods like SimPO reintroduce complexity through dual parameters ($\beta$, $\gamma$). We propose {ReLU-based Preference Optimization (RePO)}, a streamlined algorithm that eliminates $\beta$ via two advances: (1) retaining SimPO's reference-free margins but removing $\beta$ through gradient analysis, and (2) adopting a ReLU-based max-margin loss that naturally filters trivial pairs. Theoretically, RePO is characterized as SimPO's limiting case ($\beta \to \infty$), where the logistic weighting collapses to binary thresholding, forming a convex envelope of the 0-1 loss. Empirical results on AlpacaEval 2 and Arena-Hard show that RePO outperforms DPO and SimPO across multiple base models, requiring only one hyperparameter to tune.
Position-aware Graph Transformer for Recommendation
Dec 25, 2024Collaborative recommendation fundamentally involves learning high-quality user and item representations from interaction data. Recently, graph convolution networks (GCNs) have advanced the field by utilizing high-order connectivity patterns in interaction graphs, as evidenced by state-of-the-art methods like PinSage and LightGCN. However, one key limitation has not been well addressed in existing solutions: capturing long-range collaborative filtering signals, which are crucial for modeling user preference. In this work, we propose a new graph transformer (GT) framework -- \textit{Position-aware Graph Transformer for Recommendation} (PGTR), which combines the global modeling capability of Transformer blocks with the local neighborhood feature extraction of GCNs. The key insight is to explicitly incorporate node position and structure information from the user-item interaction graph into GT architecture via several purpose-designed positional encodings. The long-range collaborative signals from the Transformer block are then combined linearly with the local neighborhood features from the GCN backbone to enhance node embeddings for final recommendations. Empirical studies demonstrate the effectiveness of the proposed PGTR method when implemented on various GCN-based backbones across four real-world datasets, and the robustness against interaction sparsity as well as noise.
Unified Parameter-Efficient Unlearning for LLMs
Nov 30, 2024



The advent of Large Language Models (LLMs) has revolutionized natural language processing, enabling advanced understanding and reasoning capabilities across a variety of tasks. Fine-tuning these models for specific domains, particularly through Parameter-Efficient Fine-Tuning (PEFT) strategies like LoRA, has become a prevalent practice due to its efficiency. However, this raises significant privacy and security concerns, as models may inadvertently retain and disseminate sensitive or undesirable information. To address these issues, we introduce a novel instance-wise unlearning framework, LLMEraser, which systematically categorizes unlearning tasks and applies precise parameter adjustments using influence functions. Unlike traditional unlearning techniques that are often limited in scope and require extensive retraining, LLMEraser is designed to handle a broad spectrum of unlearning tasks without compromising model performance. Extensive experiments on benchmark datasets demonstrate that LLMEraser excels in efficiently managing various unlearning scenarios while maintaining the overall integrity and efficacy of the models.
RosePO: Aligning LLM-based Recommenders with Human Values
Oct 16, 2024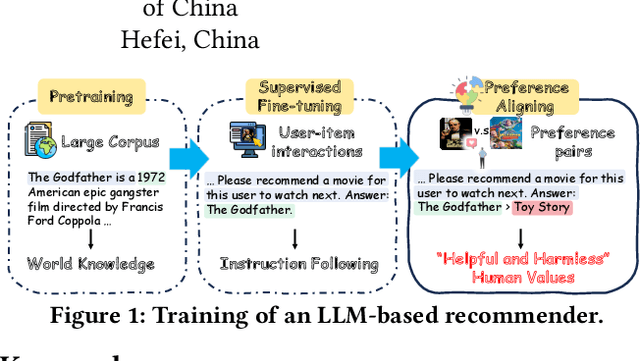
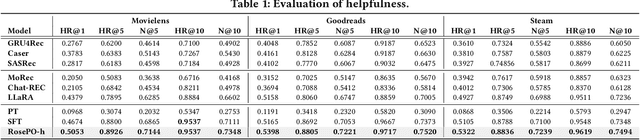
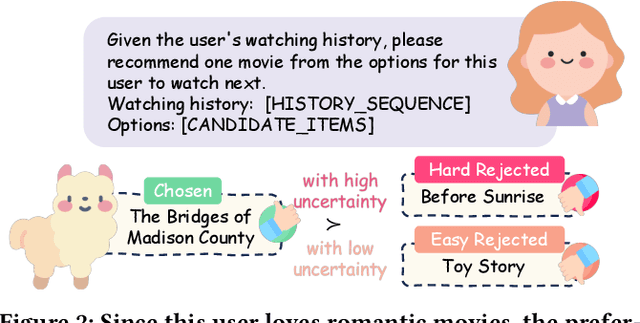

Recently, there has been a growing interest in leveraging Large Language Models (LLMs) for recommendation systems, which usually adapt a pre-trained LLM to the recommendation scenario through supervised fine-tuning (SFT). However, both the pre-training and SFT stages fail to explicitly model the comparative relationships of a user's preferences on different items. To construct a "helpful and harmless" LLM-based recommender, we propose a general framework -- Recommendation with smoothing personalized Preference Optimization (RosePO), which better aligns with customized human values during the post-training stage. Specifically, in addition to the input and chosen response that naturally align with SFT data, we design a rejected sampling strategy tailored for enhancing helpfulness, along with two strategies aimed at mitigating biases to promote harmlessness. To ensure robustness against uncertain labels present in automatically constructed preference data, we introduce a personalized smoothing factor predicted by a preference oracle into the optimization objective. Evaluation on three real-world datasets demonstrates the effectiveness of our method, showcasing not only improved recommendation performance but also mitigation of semantic hallucination and popularity bias.
$α$-DPO: Adaptive Reward Margin is What Direct Preference Optimization Needs
Oct 14, 2024



Aligning large language models (LLMs) with human values and intentions is crucial for their utility, honesty, and safety. Reinforcement learning from human feedback (RLHF) is a popular approach to achieve this alignment, but it faces challenges in computational efficiency and training stability. Recent methods like Direct Preference Optimization (DPO) and Simple Preference Optimization (SimPO) have proposed offline alternatives to RLHF, simplifying the process by reparameterizing the reward function. However, DPO depends on a potentially suboptimal reference model, and SimPO's assumption of a fixed target reward margin may lead to suboptimal decisions in diverse data settings. In this work, we propose $\alpha$-DPO, an adaptive preference optimization algorithm designed to address these limitations by introducing a dynamic reward margin. Specifically, $\alpha$-DPO employs an adaptive preference distribution, balancing the policy model and the reference model to achieve personalized reward margins. We provide theoretical guarantees for $\alpha$-DPO, demonstrating its effectiveness as a surrogate optimization objective and its ability to balance alignment and diversity through KL divergence control. Empirical evaluations on AlpacaEval 2 and Arena-Hard show that $\alpha$-DPO consistently outperforms DPO and SimPO across various model settings, establishing it as a robust approach for fine-tuning LLMs. Our method achieves significant improvements in win rates, highlighting its potential as a powerful tool for LLM alignment. The code is available at https://github.com/junkangwu/alpha-DPO
Text-guided Diffusion Model for 3D Molecule Generation
Oct 04, 2024The de novo generation of molecules with targeted properties is crucial in biology, chemistry, and drug discovery. Current generative models are limited to using single property values as conditions, struggling with complex customizations described in detailed human language. To address this, we propose the text guidance instead, and introduce TextSMOG, a new Text-guided Small Molecule Generation Approach via 3D Diffusion Model which integrates language and diffusion models for text-guided small molecule generation. This method uses textual conditions to guide molecule generation, enhancing both stability and diversity. Experimental results show TextSMOG's proficiency in capturing and utilizing information from textual descriptions, making it a powerful tool for generating 3D molecular structures in response to complex textual customizations.