 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecAware: A Spectral-Content Aware Foundation Model for Unifying Multi-Sensor Learning in Hyperspectral Remote Sensing Mapping
Oct 31, 2025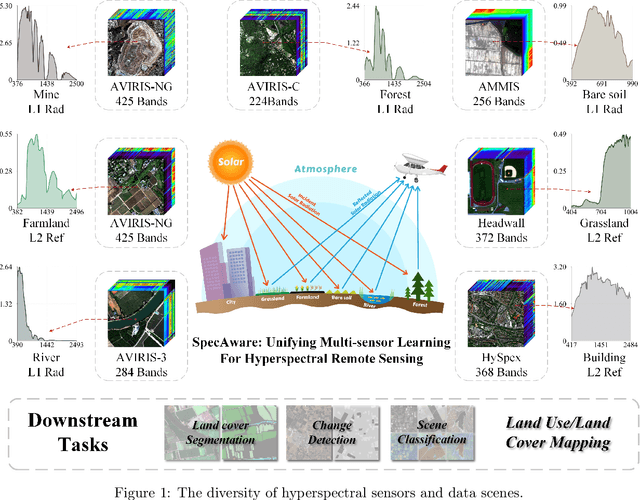
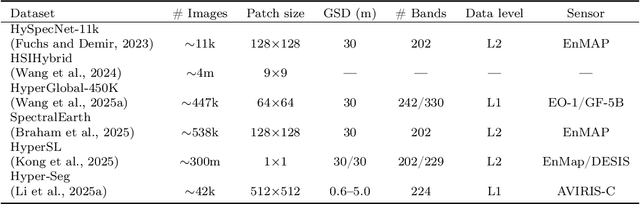
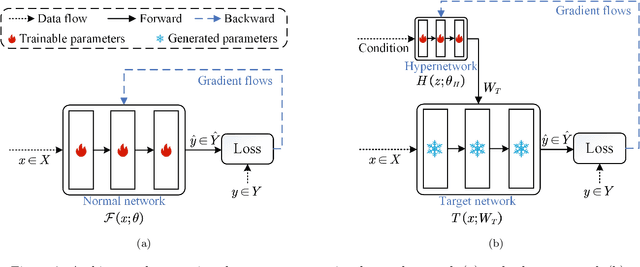

Hyperspectral imaging (HSI) is a vital tool for fine-grained land-use and land-cover (LULC) mapping. However, the inherent heterogeneity of HSI data has long posed a major barrier to developing generalized models via joint training. Although HSI foundation models have shown promise for different downstream tasks, the existing approaches typically overlook the critical guiding role of sensor meta-attributes, and struggle with multi-sensor training, limiting their transferability. To address these challenges, we propose SpecAware, which is a novel hyperspectral spectral-content aware foundation model for unifying multi-sensor learning for HSI mapping. We also constructed the Hyper-400K dataset to facilitate this research, which is a new large-scale, high-quality benchmark dataset with over 400k image patches from diverse airborne AVIRIS sensors. The core of SpecAware is a two-step hypernetwork-driven encoding process for HSI data. Firstly, we designed a meta-content aware module to generate a unique conditional input for each HSI patch, tailored to each spectral band of every sample by fusing the sensor meta-attributes and its own image content. Secondly, we designed the HyperEmbedding module, where a sample-conditioned hypernetwork dynamically generates a pair of matrix factors for channel-wise encoding, consisting of adaptive spatial pattern extraction and latent semantic feature re-projection. Thus, SpecAware gains the ability to perceive and interpret spatial-spectral features across diverse scenes and sensors. This, in turn, allows SpecAware to adaptively process a variable number of spectral channels, establishing a unified framework for joint pre-training. Extensive experiments on six datasets demonstrate that SpecAware can learn superior feature representations, excelling in land-cover semantic segmentation classification, change detection, and scene classification.
Dual-Arm Hierarchical Planning for Laboratory Automation: Vibratory Sieve Shaker Operations
Sep 18, 2025
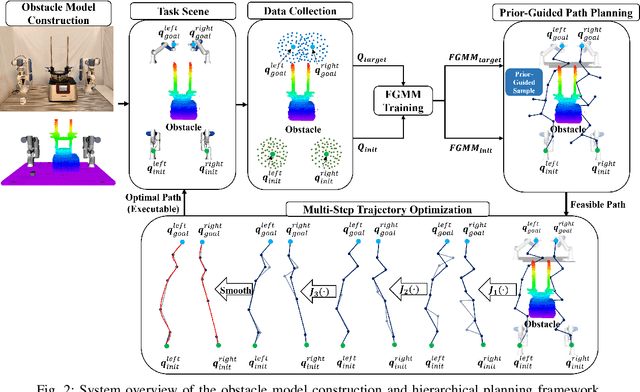
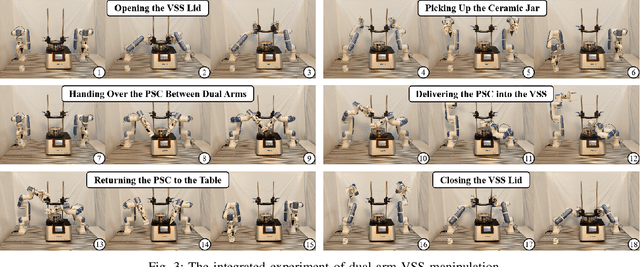
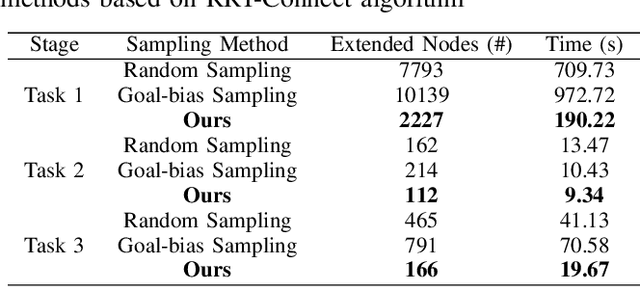
This paper addresses the challenges of automating vibratory sieve shaker operations in a materials laboratory, focusing on three critical tasks: 1) dual-arm lid manipulation in 3 cm clearance spaces, 2) bimanual handover in overlapping workspaces, and 3) obstructed powder sample container delivery with orientation constraints. These tasks present significant challenges, including inefficient sampling in narrow passages, the need for smooth trajectories to prevent spillage, and suboptimal paths generated by conventional methods. To overcome these challenges, we propose a hierarchical planning framework combining Prior-Guided Path Planning and Multi-Step Trajectory Optimization. The former uses a finite Gaussian mixture model to improve sampling efficiency in narrow passages, while the latter refines paths by shortening, simplifying, imposing joint constraints, and B-spline smoothing. Experimental results demonstrate the framework's effectiveness: planning time is reduced by up to 80.4%, and waypoints are decreased by 89.4%. Furthermore, the system completes the full vibratory sieve shaker operation workflow in a physical experiment, validating its practical applicability for complex laboratory automation.
Residual Prior-driven Frequency-aware Network for Image Fusion
Jul 09, 2025



Image fusion aims to integrate complementary information across modalities to generate high-quality fused images, thereby enhancing the performance of high-level vision tasks. While global spatial modeling mechanisms show promising results, constructing long-range feature dependencies in the spatial domain incurs substantial computational costs. Additionally, the absence of ground-truth exacerbates the difficulty of capturing complementary features effectively. To tackle these challenges, we propose a Residual Prior-driven Frequency-aware Network, termed as RPFNet. Specifically, RPFNet employs a dual-branch feature extraction framework: the Residual Prior Module (RPM) extracts modality-specific difference information from residual maps, thereby providing complementary priors for fusion; the Frequency Domain Fusion Module (FDFM) achieves efficient global feature modeling and integration through frequency-domain convolution. Additionally, the Cross Promotion Module (CPM) enhances the synergistic perception of local details and global structures through bidirectional feature interaction. During training, we incorporate an auxiliary decoder and saliency structure loss to strengthen the model's sensitivity to modality-specific differences. Furthermore, a combination of adaptive weight-based frequency contrastive loss and SSIM loss effectively constrains the solution space, facilitating the joint capture of local details and global features while ensuring the retention of complementary information. Extensive experiments validate the fusion performance of RPFNet, which effectively integrates discriminative features, enhances texture details and salient objects, and can effectively facilitate the deployment of the high-level vision task.
Less is More: Unlocking Specialization of Time Series Foundation Models via Structured Pruning
May 29, 2025Scaling laws motivate the development of Time Series Foundation Models (TSFMs) that pre-train vast parameters and achieve remarkable zero-shot forecasting performance. Surprisingly, even after fine-tuning, TSFMs cannot consistently outperform smaller, specialized models trained on full-shot downstream data. A key question is how to realize effective adaptation of TSFMs for a target forecasting task. Through empirical studies on various TSFMs, the pre-trained models often exhibit inherent sparsity and redundancy in computation, suggesting that TSFMs have learned to activate task-relevant network substructures to accommodate diverse forecasting tasks. To preserve this valuable prior knowledge, we propose a structured pruning method to regularize the subsequent fine-tuning process by focusing it on a more relevant and compact parameter space. Extensive experiments on seven TSFMs and six benchmarks demonstrate that fine-tuning a smaller, pruned TSFM significantly improves forecasting performance compared to fine-tuning original models. This "prune-then-finetune" paradigm often enables TSFMs to achieve state-of-the-art performance and surpass strong specialized baselines.
Incentivizing Strong Reasoning from Weak Supervision
May 28, 2025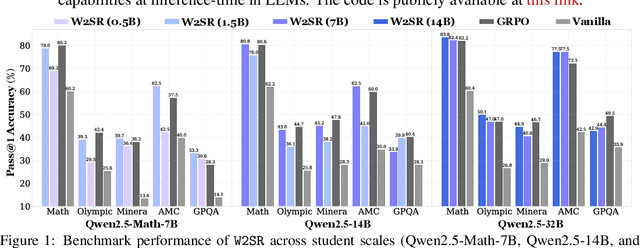
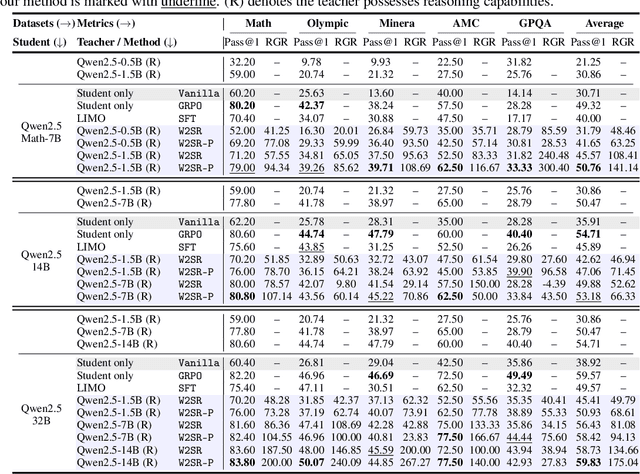
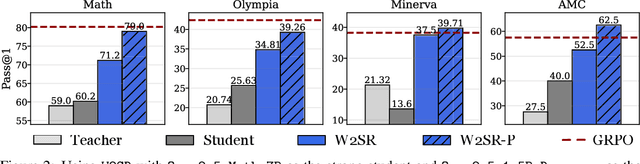
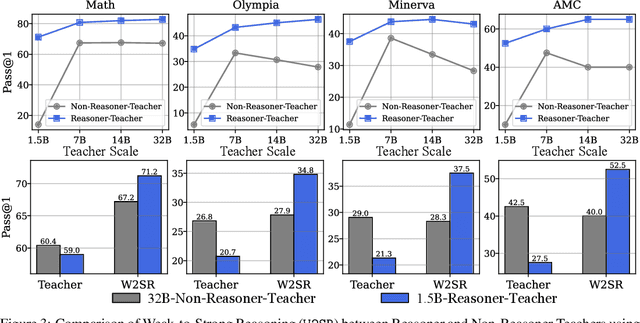
Large language models (LLMs) have demonstrated impressive performance on reasoning-intensive tasks, but enhancing their reasoning abilities typically relies on either reinforcement learning (RL) with verifiable signals or supervised fine-tuning (SFT) with high-quality long chain-of-thought (CoT) demonstrations, both of which are expensive. In this paper, we study a novel problem of incentivizing the reasoning capacity of LLMs without expensive high-quality demonstrations and reinforcement learning. We investigate whether the reasoning capabilities of LLMs can be effectively incentivized via supervision from significantly weaker models. We further analyze when and why such weak supervision succeeds in eliciting reasoning abilities in stronger models. Our findings show that supervision from significantly weaker reasoners can substantially improve student reasoning performance, recovering close to 94% of the gains of expensive RL at a fraction of the cost. Experiments across diverse benchmarks and model architectures demonstrate that weak reasoners can effectively incentivize reasoning in stronger student models, consistently improving performance across a wide range of reasoning tasks. Our results suggest that this simple weak-to-strong paradigm is a promising and generalizable alternative to costly methods for incentivizing strong reasoning capabilities at inference-time in LLMs. The code is publicly available at https://github.com/yuanyige/w2sr.
Incentivizing Reasoning from Weak Supervision
May 26, 2025Large language models (LLMs) have demonstrated impressive performance on reasoning-intensive tasks, but enhancing their reasoning abilities typically relies on either reinforcement learning (RL) with verifiable signals or supervised fine-tuning (SFT) with high-quality long chain-of-thought (CoT) demonstrations, both of which are expensive. In this paper, we study a novel problem of incentivizing the reasoning capacity of LLMs without expensive high-quality demonstrations and reinforcement learning. We investigate whether the reasoning capabilities of LLMs can be effectively incentivized via supervision from significantly weaker models. We further analyze when and why such weak supervision succeeds in eliciting reasoning abilities in stronger models. Our findings show that supervision from significantly weaker reasoners can substantially improve student reasoning performance, recovering close to 94% of the gains of expensive RL at a fraction of the cost. Experiments across diverse benchmarks and model architectures demonstrate that weak reasoners can effectively incentivize reasoning in stronger student models, consistently improving performance across a wide range of reasoning tasks. Our results suggest that this simple weak-to-strong paradigm is a promising and generalizable alternative to costly methods for incentivizing strong reasoning capabilities at inference-time in LLMs. The code is publicly available at https://github.com/yuanyige/W2SR.
GARF: Learning Generalizable 3D Reassembly for Real-World Fractures
Apr 07, 20253D reassembly is a challenging spatial intelligence task with broad applications across scientific domains. While large-scale synthetic datasets have fueled promising learning-based approaches, their generalizability to different domains is limited. Critically, it remains uncertain whether models trained on synthetic datasets can generalize to real-world fractures where breakage patterns are more complex. To bridge this gap, we propose GARF, a generalizable 3D reassembly framework for real-world fractures. GARF leverages fracture-aware pretraining to learn fracture features from individual fragments, with flow matching enabling precise 6-DoF alignments. At inference time, we introduce one-step preassembly, improving robustness to unseen objects and varying numbers of fractures. In collaboration with archaeologists, paleoanthropologists, and ornithologists, we curate Fractura, a diverse dataset for vision and learning communities, featuring real-world fracture types across ceramics, bones, eggshells, and lithics. Comprehensive experiments have shown our approach consistently outperforms state-of-the-art methods on both synthetic and real-world datasets, achieving 82.87\% lower rotation error and 25.15\% higher part accuracy. This sheds light on training on synthetic data to advance real-world 3D puzzle solving, demonstrating its strong generalization across unseen object shapes and diverse fracture types.
RePO: ReLU-based Preference Optimization
Mar 10, 2025Aligning large language models (LLMs) with human preferences is critical for real-world deployment, yet existing methods like RLHF face computational and stability challenges. While DPO establishes an offline paradigm with single hyperparameter $\beta$, subsequent methods like SimPO reintroduce complexity through dual parameters ($\beta$, $\gamma$). We propose {ReLU-based Preference Optimization (RePO)}, a streamlined algorithm that eliminates $\beta$ via two advances: (1) retaining SimPO's reference-free margins but removing $\beta$ through gradient analysis, and (2) adopting a ReLU-based max-margin loss that naturally filters trivial pairs. Theoretically, RePO is characterized as SimPO's limiting case ($\beta \to \infty$), where the logistic weighting collapses to binary thresholding, forming a convex envelope of the 0-1 loss. Empirical results on AlpacaEval 2 and Arena-Hard show that RePO outperforms DPO and SimPO across multiple base models, requiring only one hyperparameter to tune.
Self-Calibrated Dual Contrasting for Annotation-Efficient Bacteria Raman Spectroscopy Clustering and Classification
Dec 28, 2024
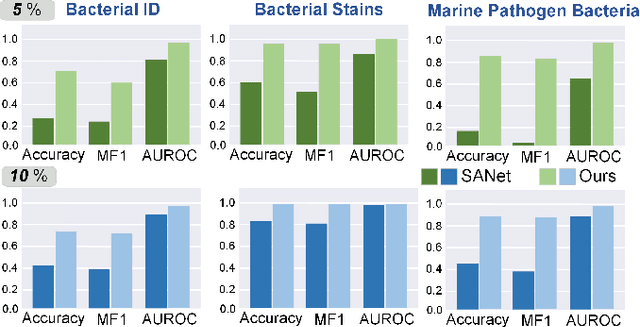


Raman scattering is based on molecular vibration spectroscopy and provides a powerful technology for pathogenic bacteria diagnosis using the unique molecular fingerprint information of a substance. The integration of deep learning technology has significantly improved the efficiency and accuracy of intelligent Raman spectroscopy (RS) recognition. However, the current RS recognition methods based on deep neural networks still require the annotation of a large amount of spectral data, which is labor-intensive. This paper presents a novel annotation-efficient Self-Calibrated Dual Contrasting (SCDC) method for RS recognition that operates effectively with few or no annotation. Our core motivation is to represent the spectrum from two different perspectives in two distinct subspaces: embedding and category. The embedding perspective captures instance-level information, while the category perspective reflects category-level information. Accordingly, we have implemented a dual contrastive learning approach from two perspectives to obtain discriminative representations, which are applicable for Raman spectroscopy recognition under both unsupervised and semi-supervised learning conditions. Furthermore, a self-calibration mechanism is proposed to enhance robustness. Validation of the identification task on three large-scale bacterial Raman spectroscopy datasets demonstrates that our SCDC method achieves robust recognition performance with very few (5$\%$ or 10$\%$) or no annotations, highlighting the potential of the proposed method for biospectral identification in annotation-efficient clinical scenarios.
Adversarial Contrastive Domain-Generative Learning for Bacteria Raman Spectrum Joint Denoising and Cross-Domain Identification
Dec 11, 2024



Raman spectroscopy, as a label-free detection technology, has been widely utilized in the clinical diagnosis of pathogenic bacteria. However, Raman signals are naturally weak and sensitive to the condition of the acquisition process. The characteristic spectra of a bacteria can manifest varying signal-to-noise ratios and domain discrepancies under different acquisition conditions. Consequently, existing methods often face challenges when making identification for unobserved acquisition conditions, i.e., the testing acquisition conditions are unavailable during model training. In this article, a generic framework, namely, an adversarial contrastive domain-generative learning framework, is proposed for joint Raman spectroscopy denoising and cross-domain identification. The proposed method is composed of a domain generation module and a domain task module. Through adversarial learning between these two modules, it utilizes only a single available source domain spectral data to generate extended denoised domains that are semantically consistent with the source domain and extracts domain-invariant representations. Comprehensive case studies indicate that the proposed method can simultaneously conduct spectral denoising without necessitating noise-free ground-truth and can achieve improved diagnostic accuracy and robustness under cross-domain unseen spectral acquisition conditions. This suggests that the proposed method holds remarkable potential as a diagnostic tool in real clinical cases.