 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Augmentation Contrastive Learning for Wearable-based Human Activity Recognition
Jan 30, 2026For low-semantic sensor signals from human activity recognition (HAR), contrastive learning (CL) is essential to implement novel applications or generic models without manual annotation, which is a high-performance self-supervised learning (SSL) method. However, CL relies heavily on data augmentation for pairwise comparisons. Especially for low semantic data in the HAR area, conducting good performance augmentation strategies in pretext tasks still rely on manual attempts lacking generalizability and flexibility. To reduce the augmentation burden, we propose an end-to-end auto-augmentation contrastive learning (AutoCL) method for wearable-based HAR. AutoCL is based on a Siamese network architecture that shares the parameters of the backbone and with a generator embedded to learn auto-augmentation. AutoCL trains the generator based on the representation in the latent space to overcome the disturbances caused by noise and redundant information in raw sensor data. The architecture empirical study indicates the effectiveness of this design. Furthermore, we propose a stop-gradient design and correlation reduction strategy in AutoCL to enhance encoder representation learning. Extensive experiments based on four wide-used HAR datasets demonstrate that the proposed AutoCL method significantly improves recognition accuracy compared with other SOTA methods.
Combating Spurious Correlations in Graph Interpretability via Self-Reflection
Jan 16, 2026Interpretable graph learning has recently emerged as a popular research topic in machine learning. The goal is to identify the important nodes and edges of an input graph that are crucial for performing a specific graph reasoning task. A number of studies have been conducted in this area, and various benchmark datasets have been proposed to facilitate evaluation. Among them, one of the most challenging is the Spurious-Motif benchmark, introduced at ICLR 2022. The datasets in this synthetic benchmark are deliberately designed to include spurious correlations, making it particularly difficult for models to distinguish truly relevant structures from misleading patterns. As a result, existing methods exhibit significantly worse performance on this benchmark compared to others. In this paper, we focus on improving interpretability on the challenging Spurious-Motif datasets. We demonstrate that the self-reflection technique, commonly used in large language models to tackle complex tasks, can also be effectively adapted to enhance interpretability in datasets with strong spurious correlations. Specifically, we propose a self-reflection framework that can be integrated with existing interpretable graph learning methods. When such a method produces importance scores for each node and edge, our framework feeds these predictions back into the original method to perform a second round of evaluation. This iterative process mirrors how large language models employ self-reflective prompting to reassess their previous outputs. We further analyze the reasons behind this improvement from the perspective of graph representation learning, which motivates us to propose a fine-tuning training method based on this feedback mechanism.
Self-Augmented Mixture-of-Experts for QoS Prediction
Jan 16, 2026Quality of Service (QoS) prediction is one of the most fundamental problems in service computing and personalized recommendation. In the problem, there is a set of users and services, each associated with a set of descriptive features. Interactions between users and services produce feedback values, typically represented as numerical QoS metrics such as response time or availability. Given the observed feedback for a subset of user-service pairs, the goal is to predict the QoS values for the remaining pairs. A key challenge in QoS prediction is the inherent sparsity of user-service interactions, as only a small subset of feedback values is typically observed. To address this, we propose a self-augmented strategy that leverages a model's own predictions for iterative refinement. In particular, we partially mask the predicted values and feed them back into the model to predict again. Building on this idea, we design a self-augmented mixture-of-experts model, where multiple expert networks iteratively and collaboratively estimate QoS values. We find that the iterative augmentation process naturally aligns with the MoE architecture by enabling inter-expert communication: in the second round, each expert receives the first-round predictions and refines its output accordingly. Experiments on benchmark datasets show that our method outperforms existing baselines and achieves competitive results.
H-LDM: Hierarchical Latent Diffusion Models for Controllable and Interpretable PCG Synthesis from Clinical Metadata
Nov 18, 2025



Phonocardiogram (PCG) analysis is vital for cardiovascular disease diagnosis, yet the scarcity of labeled pathological data hinders the capability of AI systems. To bridge this, we introduce H-LDM, a Hierarchical Latent Diffusion Model for generating clinically accurate and controllable PCG signals from structured metadata. Our approach features: (1) a multi-scale VAE that learns a physiologically-disentangled latent space, separating rhythm, heart sounds, and murmurs; (2) a hierarchical text-to-biosignal pipeline that leverages rich clinical metadata for fine-grained control over 17 distinct conditions; and (3) an interpretable diffusion process guided by a novel Medical Attention module. Experiments on the PhysioNet CirCor dataset demonstrate state-of-the-art performance, achieving a Fréchet Audio Distance of 9.7, a 92% attribute disentanglement score, and 87.1% clinical validity confirmed by cardiologists. Augmenting diagnostic models with our synthetic data improves the accuracy of rare disease classification by 11.3\%. H-LDM establishes a new direction for data augmentation in cardiac diagnostics, bridging data scarcity with interpretable clinical insights.
GARF: Learning Generalizable 3D Reassembly for Real-World Fractures
Apr 07, 20253D reassembly is a challenging spatial intelligence task with broad applications across scientific domains. While large-scale synthetic datasets have fueled promising learning-based approaches, their generalizability to different domains is limited. Critically, it remains uncertain whether models trained on synthetic datasets can generalize to real-world fractures where breakage patterns are more complex. To bridge this gap, we propose GARF, a generalizable 3D reassembly framework for real-world fractures. GARF leverages fracture-aware pretraining to learn fracture features from individual fragments, with flow matching enabling precise 6-DoF alignments. At inference time, we introduce one-step preassembly, improving robustness to unseen objects and varying numbers of fractures. In collaboration with archaeologists, paleoanthropologists, and ornithologists, we curate Fractura, a diverse dataset for vision and learning communities, featuring real-world fracture types across ceramics, bones, eggshells, and lithics. Comprehensive experiments have shown our approach consistently outperforms state-of-the-art methods on both synthetic and real-world datasets, achieving 82.87\% lower rotation error and 25.15\% higher part accuracy. This sheds light on training on synthetic data to advance real-world 3D puzzle solving, demonstrating its strong generalization across unseen object shapes and diverse fracture types.
AH-GS: Augmented 3D Gaussian Splatting for High-Frequency Detail Representation
Mar 28, 2025



The 3D Gaussian Splatting (3D-GS) is a novel method for scene representation and view synthesis. Although Scaffold-GS achieves higher quality real-time rendering compared to the original 3D-GS, its fine-grained rendering of the scene is extremely dependent on adequate viewing angles. The spectral bias of neural network learning results in Scaffold-GS's poor ability to perceive and learn high-frequency information in the scene. In this work, we propose enhancing the manifold complexity of input features and using network-based feature map loss to improve the image reconstruction quality of 3D-GS models. We introduce AH-GS, which enables 3D Gaussians in structurally complex regions to obtain higher-frequency encodings, allowing the model to more effectively learn the high-frequency information of the scene. Additionally, we incorporate high-frequency reinforce loss to further enhance the model's ability to capture detailed frequency information. Our result demonstrates that our model significantly improves rendering fidelity, and in specific scenarios (e.g., MipNeRf360-garden), our method exceeds the rendering quality of Scaffold-GS in just 15K iterations.
CuDIP: Enhancing Theorem Proving in LLMs via Curriculum Learning-based Direct Preference Optimization
Feb 25, 2025Automated theorem proving (ATP) is one of the most challenging mathematical reasoning tasks for Large Language Models (LLMs). Most existing LLM-based ATP methods rely on supervised fine-tuning, which results in a limited alignment between the theorem proving process and human preferences. Direct Preference Optimization (DPO), which aligns LLMs with human preferences, has shown positive effects for certain tasks. However, the lack of high-quality preference data for theorem proving presents a significant challenge. In this paper, we innovatively apply DPO to formal automated theorem proving and introduces a Curriculum Learning-based DPO Iterative Theorem Proving (CuDIP) method. Specifically, we propose a method for constructing preference data which utilizes LLMs and existing theorem proving data to enhance the diversity of the preference data while reducing the reliance on human preference annotations. We then integrate this preference data construction method with curriculum learning to iteratively fine-tune the theorem proving model through DPO. Experimental results on the MiniF2F and ProofNet datasets demonstrate the effectiveness of the proposed method.
Open-Book Neural Algorithmic Reasoning
Dec 30, 2024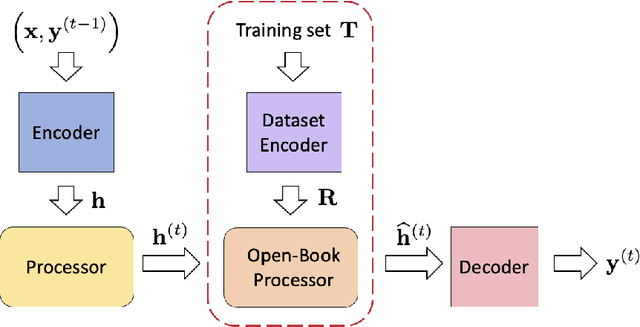
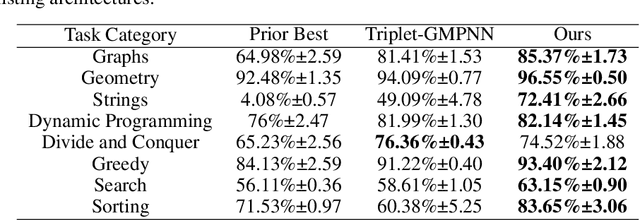
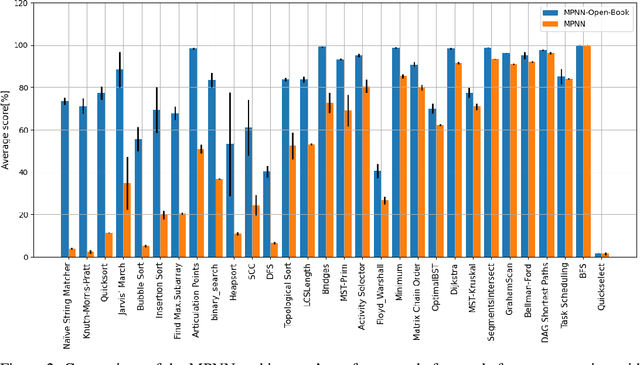
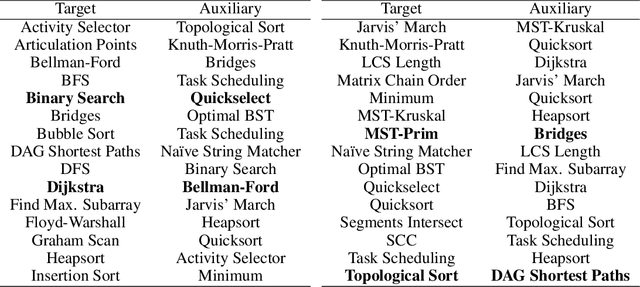
Neural algorithmic reasoning is an emerging area of machine learning that focuses on building neural networks capable of solving complex algorithmic tasks. Recent advancements predominantly follow the standard supervised learning paradigm -- feeding an individual problem instance into the network each time and training it to approximate the execution steps of a classical algorithm. We challenge this mode and propose a novel open-book learning framework. In this framework, whether during training or testing, the network can access and utilize all instances in the training dataset when reasoning for a given instance. Empirical evaluation is conducted on the challenging CLRS Algorithmic Reasoning Benchmark, which consists of 30 diverse algorithmic tasks. Our open-book learning framework exhibits a significant enhancement in neural reasoning capabilities. Further, we notice that there is recent literature suggesting that multi-task training on CLRS can improve the reasoning accuracy of certain tasks, implying intrinsic connections between different algorithmic tasks. We delve into this direction via the open-book framework. When the network reasons for a specific task, we enable it to aggregate information from training instances of other tasks in an attention-based manner. We show that this open-book attention mechanism offers insights into the inherent relationships among various tasks in the benchmark and provides a robust tool for interpretable multi-task training.
A Context-Enhanced Framework for Sequential Graph Reasoning
Dec 12, 2024The paper studies sequential reasoning over graph-structured data, which stands as a fundamental task in various trending fields like automated math problem solving and neural graph algorithm learning, attracting a lot of research interest. Simultaneously managing both sequential and graph-structured information in such tasks presents a notable challenge. Over recent years, many neural architectures in the literature have emerged to tackle the issue. In this work, we generalize the existing architectures and propose a context-enhanced framework. The crucial innovation is that the reasoning of each step does not only rely on the outcome of the preceding step but also leverages the aggregation of information from more historical outcomes. The idea stems from our observation that in sequential graph reasoning, each step's outcome has a much stronger inner connection with each other compared to traditional seq-to-seq tasks. We show that the framework can effectively integrate with the existing methods, enhancing their reasoning abilities. Empirical evaluations are conducted on the challenging CLRS Reasoning Benchmark, and the results demonstrate that the proposed framework significantly improves the performance of existing architectures, yielding state-of-the-art results across the majority of the datasets within the benchmark.
Speech-based Clinical Depression Screening: An Empirical Study
Jun 05, 2024This study investigates the utility of speech signals for AI-based depression screening across varied interaction scenarios, including psychiatric interviews, chatbot conversations, and text readings. Participants includes depressed patients recruited from the outpatient clinics of Peking University Sixth Hospital and control group members from the community, all diagnosed by psychiatrists following standardized diagnostic protocols. We extracted acoustic and deep speech features from each participant's segmented recordings. Classifications were made using neural networks or SVMs, with aggregated clip outcomes determining final assessments. Our analysis across interaction scenarios, speech processing techniques, and feature types confirms speech as a crucial marker for depression screening. Specifically, human-computer interaction matches clinical interview efficacy, surpassing reading tasks. Segment duration and quantity significantly affect model performance, with deep speech features substantially outperforming traditional acoustic features.