 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAM-SD: Retrieval-Augmented Multi-agent framework for Sarcasm Detection
Jan 14, 2026Sarcasm detection remains a significant challenge due to its reliance on nuanced contextual understanding, world knowledge, and multi-faceted linguistic cues that vary substantially across different sarcastic expressions. Existing approaches, from fine-tuned transformers to large language models, apply a uniform reasoning strategy to all inputs, struggling to address the diverse analytical demands of sarcasm. These demands range from modeling contextual expectation violations to requiring external knowledge grounding or recognizing specific rhetorical patterns. To address this limitation, we introduce RAM-SD, a Retrieval-Augmented Multi-Agent framework for Sarcasm Detection. The framework operates through four stages: (1) contextual retrieval grounds the query in both sarcastic and non-sarcastic exemplars; (2) a meta-planner classifies the sarcasm type and selects an optimal reasoning plan from a predefined set; (3) an ensemble of specialized agents performs complementary, multi-view analysis; and (4) an integrator synthesizes these analyses into a final, interpretable judgment with a natural language explanation. Evaluated on four standard benchmarks, RAM-SD achieves a state-of-the-art Macro-F1 of 77.74%, outperforming the strong GPT-4o+CoC baseline by 7.01 points. Our framework not only sets a new performance benchmark but also provides transparent and interpretable reasoning traces, illuminating the cognitive processes behind sarcasm comprehension.
Speech-based Clinical Depression Screening: An Empirical Study
Jun 05, 2024This study investigates the utility of speech signals for AI-based depression screening across varied interaction scenarios, including psychiatric interviews, chatbot conversations, and text readings. Participants includes depressed patients recruited from the outpatient clinics of Peking University Sixth Hospital and control group members from the community, all diagnosed by psychiatrists following standardized diagnostic protocols. We extracted acoustic and deep speech features from each participant's segmented recordings. Classifications were made using neural networks or SVMs, with aggregated clip outcomes determining final assessments. Our analysis across interaction scenarios, speech processing techniques, and feature types confirms speech as a crucial marker for depression screening. Specifically, human-computer interaction matches clinical interview efficacy, surpassing reading tasks. Segment duration and quantity significantly affect model performance, with deep speech features substantially outperforming traditional acoustic features.
Wish I Can Feel What You Feel: A Neural Approach for Empathetic Response Generation
Dec 05, 2022



Expressing empathy is important in everyday conversations, and exploring how empathy arises is crucial in automatic response generation. Most previous approaches consider only a single factor that affects empathy. However, in practice, empathy generation and expression is a very complex and dynamic psychological process. A listener needs to find out events which cause a speaker's emotions (emotion cause extraction), project the events into some experience (knowledge extension), and express empathy in the most appropriate way (communication mechanism). To this end, we propose a novel approach, which integrates the three components - emotion cause, knowledge graph, and communication mechanism for empathetic response generation. Experimental results on the benchmark dataset demonstrate the effectiveness of our method and show that incorporating the key components generates more informative and empathetic responses.
MetaMix: Improved Meta-Learning with Interpolation-based Consistency Regularization
Oct 10, 2020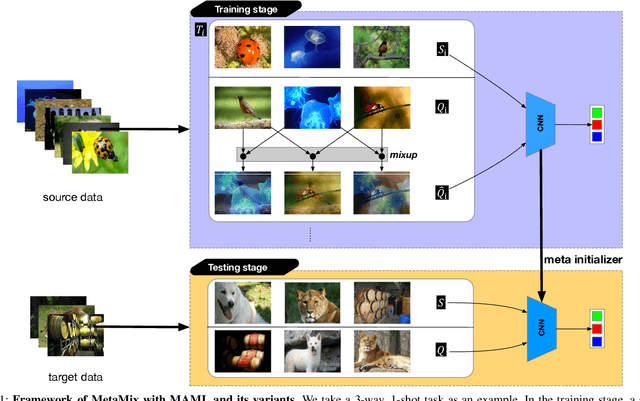
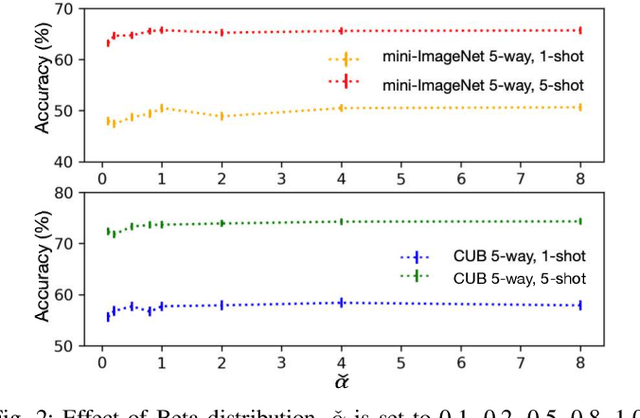
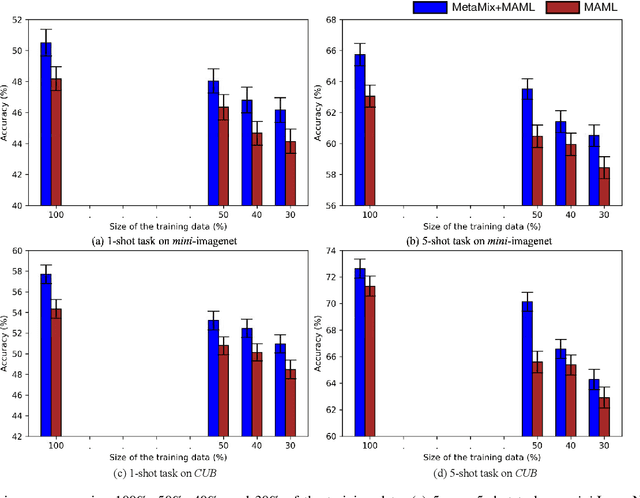
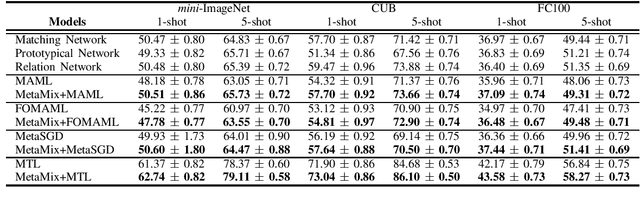
Model-Agnostic Meta-Learning (MAML) and its variants are popular few-shot classification methods. They train an initializer across a variety of sampled learning tasks (also known as episodes) such that the initialized model can adapt quickly to new tasks. However, current MAML-based algorithms have limitations in forming generalizable decision boundaries. In this paper, we propose an approach called MetaMix. It generates virtual feature-target pairs within each episode to regularize the backbone models. MetaMix can be integrated with any of the MAML-based algorithms and learn the decision boundaries generalizing better to new tasks. Experiments on the mini-ImageNet, CUB, and FC100 datasets show that MetaMix improves the performance of MAML-based algorithms and achieves state-of-the-art result when integrated with Meta-Transfer Learning.
Virtual Mixup Training for Unsupervised Domain Adaptation
May 24, 2019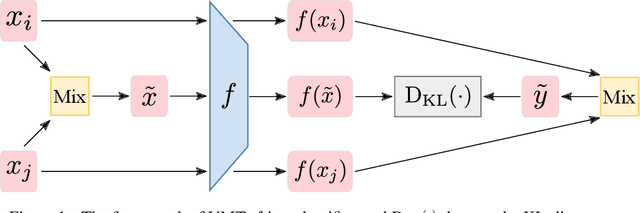
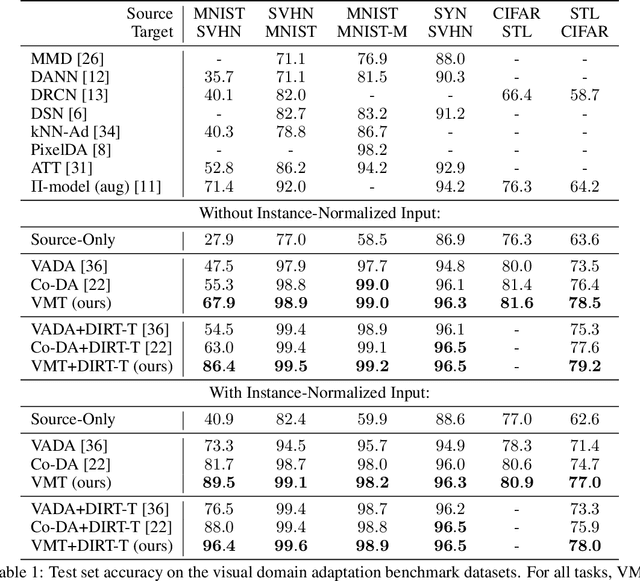
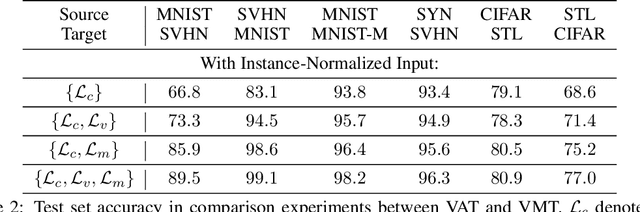

We study the problem of unsupervised domain adaptation which aims to adapt models trained on a labeled source domain to a completely unlabeled target domain. Domain adversarial training is a promising approach and has been a basis for many state-of-the-art models in unsupervised domain adaptation. The idea of domain adversarial training is to align the feature space between the source and target domains by adversarially training a domain classifier and a feature encoder. Recently, cluster assumption has been applied to unsupervised domain adaptation and achieved strong performance. In this paper, we propose a new regularization method called Virtual Mixup Training (VMT), which is able to further constrain the hypothesis of cluster assumption. The idea of VMT is to impose a locally-Lipschitz constraint on the model by smoothing the output distribution along the lines between pairs of training samples. Unlike the traditional mixup model, our method constructs the combination samples without using the label information, allowing it to be applicable to unsupervised domain adaptation. The proposed method is generic and can be combined with existing methods using domain adversarial training. We combine VMT with a recent state-of-the-art model called VADA, and extensive experiments demonstrate that VMT significantly improves the performance of VADA on several domain adaptation benchmark datasets. For the challenging task of adapting MNIST to SVHN, when not using instance normalization, VMT improves the accuracy of VADA by over 30%. When using instance normalization, our model achieves an accuracy of 96.4%, which is very close to the accuracy (96.5%) of the train-on-target model. Code will be made publicly available.
Meta Learning for Few-shot Keyword Spotting
Dec 26, 2018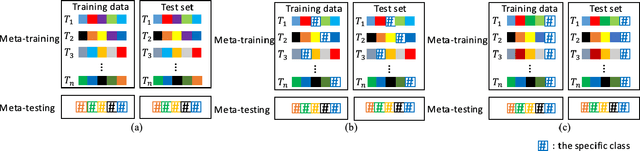
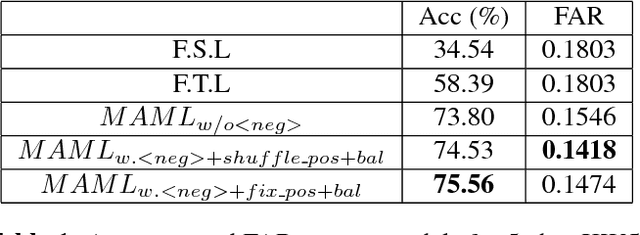
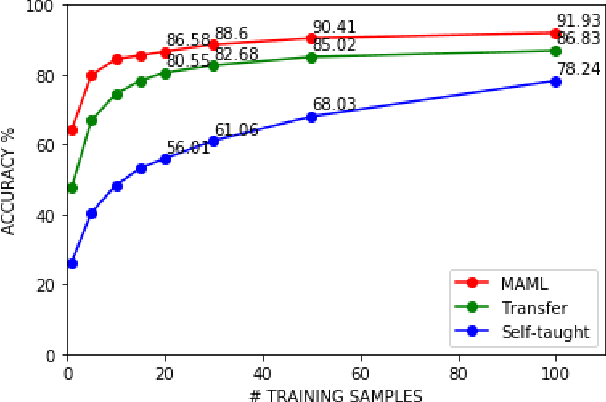
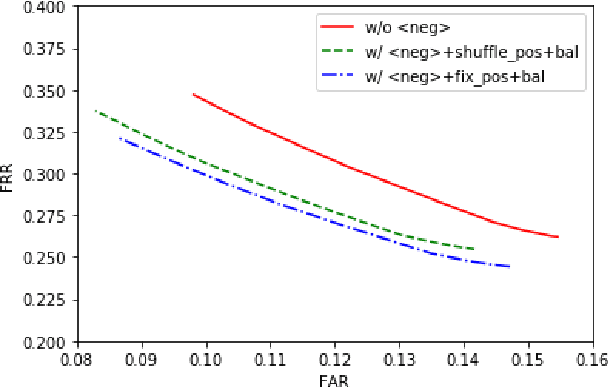
Keyword spotting with limited training data is a challenging task which can be treated as a few-shot learning problem. In this paper, we present a meta-learning approach which learns a good initialization of the base KWS model from existed labeled dataset. Then it can quickly adapt to new tasks of keyword spotting with only a few labeled data. Furthermore, to strengthen the ability of distinguishing the keywords with the others, we incorporate the negative class as external knowledge to the meta-training process, which proves to be effective. Experiments on the Google Speech Commands dataset show that our proposed approach outperforms the baselines.