 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling the Long Video Understanding of Multimodal Large Language Models via Visual Memory Mechanism
Mar 31, 2026Long video understanding is a key challenge that plagues the advancement of \emph{Multimodal Large language Models} (MLLMs). In this paper, we study this problem from the perspective of visual memory mechanism, and proposed a novel and training-free approach, termed \emph{Flexible Memory} (\textbf{FlexMem}). In principle, FlexMem aims to mimic human behavior of video watching, \emph{i.e.}, continually watching video content and recalling the most relevant memory fragments to answer the question. In this way, FlexMem can help MLLMs achieve video understanding of infinite lengths, unlike previous methods that process all video information at once and have input upper-limit. Concretely, FlexMem first consider the visual KV caches as the memory sources, and realize the effective memory transfer and writing via a dual-pathway compression design. Afterwards, FlexMem also explores different memory reading strategies for the diverse video understanding tasks, including the popular streaming one. To validate FlexMem, we apply it to two popular video-MLLMs, and conduct extensive experiments on five long video and one streaming video task. The experimental results show that on \textbf{a single 3090 GPU}, our FlexMem can achieve obvious improvements than existing efficient video understanding methods and process more than \textbf{1k frames}, which also helps the base MLLMs achieve comparable or even better performance than SOTA MLLMs on some benchmarks, \emph{e.g.} , GPT-4o and Gemini-1.5 Pro.
GeoTikzBridge: Advancing Multimodal Code Generation for Geometric Perception and Reasoning
Mar 24, 2026Multimodal Large Language Models (MLLMs) have recently demonstrated remarkable perceptual and reasoning abilities. However, they struggle to perceive fine-grained geometric structures, constraining their ability of geometric understanding and visual reasoning. To address this, we propose GeoTikzBridge, a framework that enhances local geometric perception and visual reasoning through tikz-based code generation. Within this framework, we build two models supported by two complementary datasets. The GeoTikzBridge-Base model is trained on GeoTikz-Base dataset, the largest image-to-tikz dataset to date with 2.5M pairs (16 $\times$ larger than existing open-sourced datasets). This process is achieved via iterative data expansion and a localized geometric transformation strategy. Subsequently, GeoTikzBridge-Instruct is fine-tuned on GeoTikz-Instruct dataset which is the first instruction-augmented tikz dataset supporting visual reasoning. Extensive experimental results demonstrate that our models achieve state-of-the-art performance among open-sourced MLLMs. Furthermore, GeoTikzBridge models can serve as plug-and-play reasoning modules for any MLLM(LLM), enhancing reasoning performance in geometric problem-solving. Datasets and codes are publicly available at: https://github.com/sjy-1995/GeoTikzBridge-Advancing-Multimodal-Code-Generation-for-Geometric-Perception-and-Reasoning.
Speech-Omni-Lite: Portable Speech Interfaces for Vision-Language Models
Mar 10, 2026While large-scale omni-models have demonstrated impressive capabilities across various modalities, their strong performance heavily relies on massive multimodal data and incurs substantial computational costs. This work introduces Speech-Omni-Lite, a cost-efficient framework for extending pre-trained Visual-Language (VL) backbones with speech understanding and generation capabilities, while fully preserving the backbones' vision-language performance. Specifically, the VL backbone is equipped with two lightweight, trainable plug-and-play modules, a speech projector and a speech token generator, while keeping the VL backbone fully frozen. To mitigate the scarcity of spoken QA corpora, a low-cost data construction strategy is proposed to generate Question-Text Answer-Text-Speech (QTATS) data from existing ASR speech-text pairs, facilitating effective speech generation training. Experimental results show that, even with only thousands of hours of speech training data, Speech-Omni-Lite achieves excellent spoken QA performance, which is comparable to omni-models trained on millions of hours of speech data. Furthermore, the learned speech modules exhibit strong transferability across VL backbones.
RADAR: Benchmarking Vision-Language-Action Generalization via Real-World Dynamics, Spatial-Physical Intelligence, and Autonomous Evaluation
Feb 11, 2026VLA models have achieved remarkable progress in embodied intelligence; however, their evaluation remains largely confined to simulations or highly constrained real-world settings. This mismatch creates a substantial reality gap, where strong benchmark performance often masks poor generalization in diverse physical environments. We identify three systemic shortcomings in current benchmarking practices that hinder fair and reliable model comparison. (1) Existing benchmarks fail to model real-world dynamics, overlooking critical factors such as dynamic object configurations, robot initial states, lighting changes, and sensor noise. (2) Current protocols neglect spatial--physical intelligence, reducing evaluation to rote manipulation tasks that do not probe geometric reasoning. (3) The field lacks scalable fully autonomous evaluation, instead relying on simplistic 2D metrics that miss 3D spatial structure or on human-in-the-loop systems that are costly, biased, and unscalable. To address these limitations, we introduce RADAR (Real-world Autonomous Dynamics And Reasoning), a benchmark designed to systematically evaluate VLA generalization under realistic conditions. RADAR integrates three core components: (1) a principled suite of physical dynamics; (2) dedicated tasks that explicitly test spatial reasoning and physical understanding; and (3) a fully autonomous evaluation pipeline based on 3D metrics, eliminating the need for human supervision. We apply RADAR to audit multiple state-of-the-art VLA models and uncover severe fragility beneath their apparent competence. Performance drops precipitously under modest physical dynamics, with the expectation of 3D IoU declining from 0.261 to 0.068 under sensor noise. Moreover, models exhibit limited spatial reasoning capability. These findings position RADAR as a necessary bench toward reliable and generalizable real-world evaluation of VLA models.
FedAdaVR: Adaptive Variance Reduction for Robust Federated Learning under Limited Client Participation
Jan 29, 2026Federated learning (FL) encounters substantial challenges due to heterogeneity, leading to gradient noise, client drift, and partial client participation errors, the last of which is the most pervasive but remains insufficiently addressed in current literature. In this paper, we propose FedAdaVR, a novel FL algorithm aimed at solving heterogeneity issues caused by sporadic client participation by incorporating an adaptive optimiser with a variance reduction technique. This method takes advantage of the most recent stored updates from clients, even when they are absent from the current training round, thereby emulating their presence. Furthermore, we propose FedAdaVR-Quant, which stores client updates in quantised form, significantly reducing the memory requirements (by 50%, 75%, and 87.5%) of FedAdaVR while maintaining equivalent model performance. We analyse the convergence behaviour of FedAdaVR under general nonconvex conditions and prove that our proposed algorithm can eliminate partial client participation error. Extensive experiments conducted on multiple datasets, under both independent and identically distributed (IID) and non-IID settings, demonstrate that FedAdaVR consistently outperforms state-of-the-art baseline methods.
PROST-LLM: Progressively Enhancing the Speech-to-Speech Translation Capability in LLMs
Jan 23, 2026Although Large Language Models (LLMs) excel in many tasks, their application to Speech-to-Speech Translation (S2ST) is underexplored and hindered by data scarcity. To bridge this gap, we propose PROST-LLM (PROgressive Speech-to-speech Translation) to enhance the S2ST capabilities in LLMs progressively. First, we fine-tune the LLMs with the CVSS corpus, employing designed tri-task learning and chain of modality methods to boost the initial performance. Then, leveraging the fine-tuned model, we generate preference pairs through self-sampling and back-translation without human evaluation. Finally, these preference pairs are used for preference optimization to enhance the model's S2ST capability further. Extensive experiments confirm the effectiveness of our proposed PROST-LLM in improving the S2ST capability of LLMs.
DSA-Tokenizer: Disentangled Semantic-Acoustic Tokenization via Flow Matching-based Hierarchical Fusion
Jan 15, 2026Speech tokenizers serve as the cornerstone of discrete Speech Large Language Models (Speech LLMs). Existing tokenizers either prioritize semantic encoding, fuse semantic content with acoustic style inseparably, or achieve incomplete semantic-acoustic disentanglement. To achieve better disentanglement, we propose DSA-Tokenizer, which explicitly disentangles speech into discrete semantic and acoustic tokens via distinct optimization constraints. Specifically, semantic tokens are supervised by ASR to capture linguistic content, while acoustic tokens focus on mel-spectrograms restoration to encode style. To eliminate rigid length constraints between the two sequences, we introduce a hierarchical Flow-Matching decoder that further improve speech generation quality. Furthermore, We employ a joint reconstruction-recombination training strategy to enforce this separation. DSA-Tokenizer enables high fidelity reconstruction and flexible recombination through robust disentanglement, facilitating controllable generation in speech LLMs. Our analysis highlights disentangled tokenization as a pivotal paradigm for future speech modeling. Audio samples are avaialble at https://anonymous.4open.science/w/DSA_Tokenizer_demo/. The code and model will be made publicly available after the paper has been accepted.
LLHA-Net: A Hierarchical Attention Network for Two-View Correspondence Learning
Dec 31, 2025Establishing the correct correspondence of feature points is a fundamental task in computer vision. However, the presence of numerous outliers among the feature points can significantly affect the matching results, reducing the accuracy and robustness of the process. Furthermore, a challenge arises when dealing with a large proportion of outliers: how to ensure the extraction of high-quality information while reducing errors caused by negative samples. To address these issues, in this paper, we propose a novel method called Layer-by-Layer Hierarchical Attention Network, which enhances the precision of feature point matching in computer vision by addressing the issue of outliers. Our method incorporates stage fusion, hierarchical extraction, and an attention mechanism to improve the network's representation capability by emphasizing the rich semantic information of feature points. Specifically, we introduce a layer-by-layer channel fusion module, which preserves the feature semantic information from each stage and achieves overall fusion, thereby enhancing the representation capability of the feature points. Additionally, we design a hierarchical attention module that adaptively captures and fuses global perception and structural semantic information using an attention mechanism. Finally, we propose two architectures to extract and integrate features, thereby improving the adaptability of our network. We conduct experiments on two public datasets, namely YFCC100M and SUN3D, and the results demonstrate that our proposed method outperforms several state-of-the-art techniques in both outlier removal and camera pose estimation. Source code is available at http://www.linshuyuan.com.
FedOAED: Federated On-Device Autoencoder Denoiser for Heterogeneous Data under Limited Client Availability
Dec 19, 2025

Over the last few decades, machine learning (ML) and deep learning (DL) solutions have demonstrated their potential across many applications by leveraging large amounts of high-quality data. However, strict data-sharing regulations such as the General Data Protection Regulation (GDPR) and the Health Insurance Portability and Accountability Act (HIPAA) have prevented many data-driven applications from being realised. Federated Learning (FL), in which raw data never leaves local devices, has shown promise in overcoming these limitations. Although FL has grown rapidly in recent years, it still struggles with heterogeneity, which produces gradient noise, client-drift, and increased variance from partial client participation. In this paper, we propose FedOAED, a novel federated learning algorithm designed to mitigate client-drift arising from multiple local training updates and the variance induced by partial client participation. FedOAED incorporates an on-device autoencoder denoiser on the client side to mitigate client-drift and variance resulting from heterogeneous data under limited client availability. Experiments on multiple vision datasets under Non-IID settings demonstrate that FedOAED consistently outperforms state-of-the-art baselines.
Neural Collapse in Test-Time Adaptation
Dec 11, 2025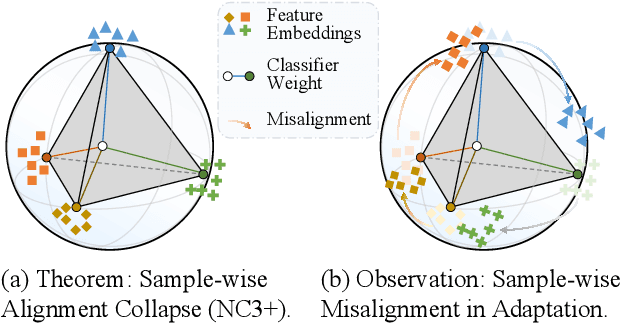
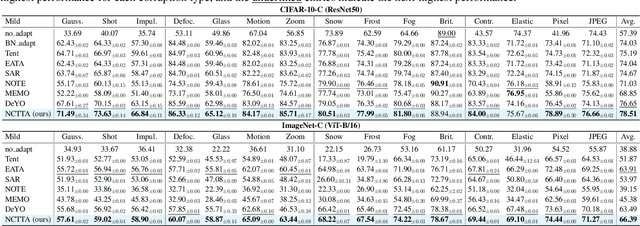
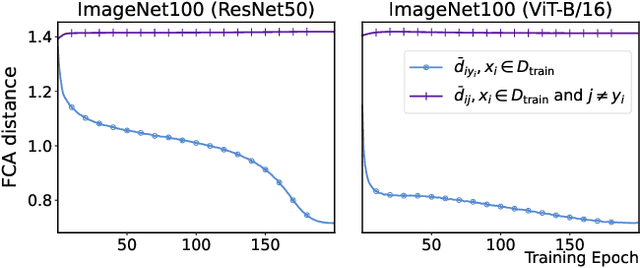
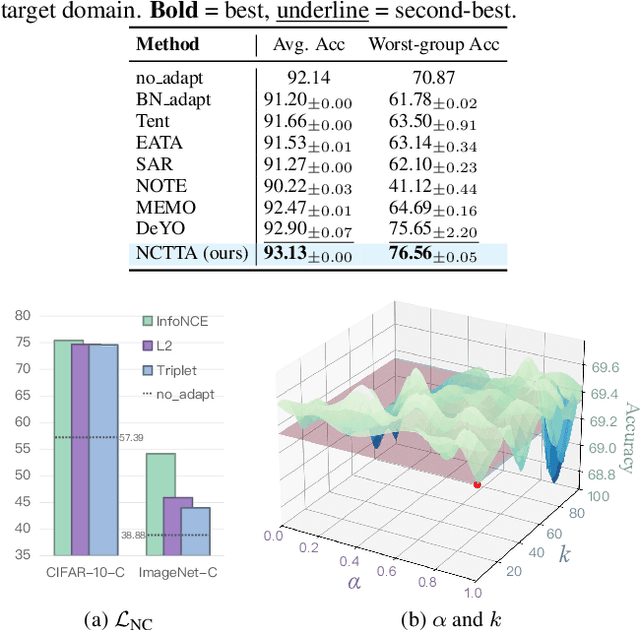
Test-Time Adaptation (TTA) enhances model robustness to out-of-distribution (OOD) data by updating the model online during inference, yet existing methods lack theoretical insights into the fundamental causes of performance degradation under domain shifts. Recently, Neural Collapse (NC) has been proposed as an emergent geometric property of deep neural networks (DNNs), providing valuable insights for TTA. In this work, we extend NC to the sample-wise level and discover a novel phenomenon termed Sample-wise Alignment Collapse (NC3+), demonstrating that a sample's feature embedding, obtained by a trained model, aligns closely with the corresponding classifier weight. Building on NC3+, we identify that the performance degradation stems from sample-wise misalignment in adaptation which exacerbates under larger distribution shifts. This indicates the necessity of realigning the feature embeddings with their corresponding classifier weights. However, the misalignment makes pseudo-labels unreliable under domain shifts. To address this challenge, we propose NCTTA, a novel feature-classifier alignment method with hybrid targets to mitigate the impact of unreliable pseudo-labels, which blends geometric proximity with predictive confidence. Extensive experiments demonstrate the effectiveness of NCTTA in enhancing robustness to domain shifts. For example, NCTTA outperforms Tent by 14.52% on ImageNet-C.