 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Better Cephalometric Landmark Detection with Diffusion Data Generation
May 09, 2025Cephalometric landmark detection is essential for orthodontic diagnostics and treatment planning. Nevertheless, the scarcity of samples in data collection and the extensive effort required for manual annotation have significantly impeded the availability of diverse datasets. This limitation has restricted the effectiveness of deep learning-based detection methods, particularly those based on large-scale vision models. To address these challenges, we have developed an innovative data generation method capable of producing diverse cephalometric X-ray images along with corresponding annotations without human intervention. To achieve this, our approach initiates by constructing new cephalometric landmark annotations using anatomical priors. Then, we employ a diffusion-based generator to create realistic X-ray images that correspond closely with these annotations. To achieve precise control in producing samples with different attributes, we introduce a novel prompt cephalometric X-ray image dataset. This dataset includes real cephalometric X-ray images and detailed medical text prompts describing the images. By leveraging these detailed prompts, our method improves the generation process to control different styles and attributes. Facilitated by the large, diverse generated data, we introduce large-scale vision detection models into the cephalometric landmark detection task to improve accuracy. Experimental results demonstrate that training with the generated data substantially enhances the performance. Compared to methods without using the generated data, our approach improves the Success Detection Rate (SDR) by 6.5%, attaining a notable 82.2%. All code and data are available at: https://um-lab.github.io/cepha-generation
Reducing CT Metal Artifacts by Learning Latent Space Alignment with Gemstone Spectral Imaging Data
Mar 27, 2025Metal artifacts in CT slices have long posed challenges in medical diagnostics. These artifacts degrade image quality, resulting in suboptimal visualization and complicating the accurate interpretation of tissues adjacent to metal implants. To address these issues, we introduce the Latent Gemstone Spectral Imaging (GSI) Alignment Framework, which effectively reduces metal artifacts while avoiding the introduction of noise information. Our work is based on a key finding that even artifact-affected ordinary CT sequences contain sufficient information to discern detailed structures. The challenge lies in the inability to clearly represent this information. To address this issue, we developed an Alignment Framework that adjusts the representation of ordinary CT images to match GSI CT sequences. GSI is an advanced imaging technique using multiple energy levels to mitigate artifacts caused by metal implants. By aligning the representation to GSI data, we can effectively suppress metal artifacts while clearly revealing detailed structure, without introducing extraneous information into CT sequences. To facilitate the application, we propose a new dataset, Artifacts-GSI, captured from real patients with metal implants, and establish a new benchmark based on this dataset. Experimental results show that our method significantly reduces metal artifacts and greatly enhances the readability of CT slices. All our code and data are available at: https://um-lab.github.io/GSI-MAR/
Deep Learning Techniques for Automatic Lateral X-ray Cephalometric Landmark Detection: Is the Problem Solved?
Sep 24, 2024Localization of the craniofacial landmarks from lateral cephalograms is a fundamental task in cephalometric analysis. The automation of the corresponding tasks has thus been the subject of intense research over the past decades. In this paper, we introduce the "Cephalometric Landmark Detection (CL-Detection)" dataset, which is the largest publicly available and comprehensive dataset for cephalometric landmark detection. This multi-center and multi-vendor dataset includes 600 lateral X-ray images with 38 landmarks acquired with different equipment from three medical centers. The overarching objective of this paper is to measure how far state-of-the-art deep learning methods can go for cephalometric landmark detection. Following the 2023 MICCAI CL-Detection Challenge, we report the results of the top ten research groups using deep learning methods. Results show that the best methods closely approximate the expert analysis, achieving a mean detection rate of 75.719% and a mean radial error of 1.518 mm. While there is room for improvement, these findings undeniably open the door to highly accurate and fully automatic location of craniofacial landmarks. We also identify scenarios for which deep learning methods are still failing. Both the dataset and detailed results are publicly available online, while the platform will remain open for the community to benchmark future algorithm developments at https://cl-detection2023.grand-challenge.org/.
DME-Driver: Integrating Human Decision Logic and 3D Scene Perception in Autonomous Driving
Jan 08, 2024In the field of autonomous driving, two important features of autonomous driving car systems are the explainability of decision logic and the accuracy of environmental perception. This paper introduces DME-Driver, a new autonomous driving system that enhances the performance and reliability of autonomous driving system. DME-Driver utilizes a powerful vision language model as the decision-maker and a planning-oriented perception model as the control signal generator. To ensure explainable and reliable driving decisions, the logical decision-maker is constructed based on a large vision language model. This model follows the logic employed by experienced human drivers and makes decisions in a similar manner. On the other hand, the generation of accurate control signals relies on precise and detailed environmental perception, which is where 3D scene perception models excel. Therefore, a planning oriented perception model is employed as the signal generator. It translates the logical decisions made by the decision-maker into accurate control signals for the self-driving cars. To effectively train the proposed model, a new dataset for autonomous driving was created. This dataset encompasses a diverse range of human driver behaviors and their underlying motivations. By leveraging this dataset, our model achieves high-precision planning accuracy through a logical thinking process.
Multi-Resolution Fusion for Fully Automatic Cephalometric Landmark Detection
Oct 04, 2023

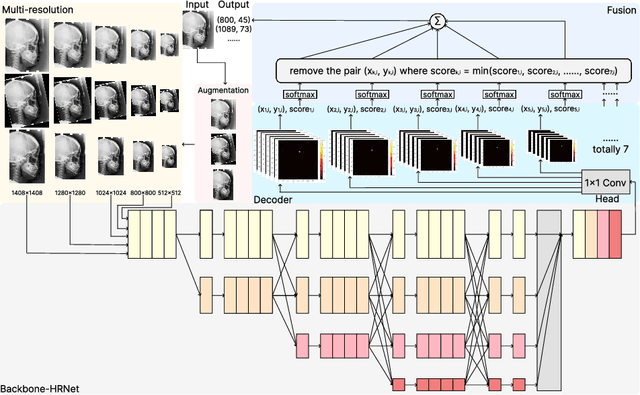

Cephalometric landmark detection on lateral skull X-ray images plays a crucial role in the diagnosis of certain dental diseases. Accurate and effective identification of these landmarks presents a significant challenge. Based on extensive data observations and quantitative analyses, we discovered that visual features from different receptive fields affect the detection accuracy of various landmarks differently. As a result, we employed an image pyramid structure, integrating multiple resolutions as input to train a series of models with different receptive fields, aiming to achieve the optimal feature combination for each landmark. Moreover, we applied several data augmentation techniques during training to enhance the model's robustness across various devices and measurement alternatives. We implemented this method in the Cephalometric Landmark Detection in Lateral X-ray Images 2023 Challenge and achieved a Mean Radial Error (MRE) of 1.62 mm and a Success Detection Rate (SDR) 2.0mm of 74.18% in the final testing phase.