 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Reinforcing Prototype Evolution with Dual-Knowledge Cooperation for Semi-Supervised Lifelong Person Re-Identification
Jul 02, 2025Current lifelong person re-identification (LReID) methods predominantly rely on fully labeled data streams. However, in real-world scenarios where annotation resources are limited, a vast amount of unlabeled data coexists with scarce labeled samples, leading to the Semi-Supervised LReID (Semi-LReID) problem where LReID methods suffer severe performance degradation. Existing LReID methods, even when combined with semi-supervised strategies, suffer from limited long-term adaptation performance due to struggling with the noisy knowledge occurring during unlabeled data utilization. In this paper, we pioneer the investigation of Semi-LReID, introducing a novel Self-Reinforcing Prototype Evolution with Dual-Knowledge Cooperation framework (SPRED). Our key innovation lies in establishing a self-reinforcing cycle between dynamic prototype-guided pseudo-label generation and new-old knowledge collaborative purification to enhance the utilization of unlabeled data. Specifically, learnable identity prototypes are introduced to dynamically capture the identity distributions and generate high-quality pseudo-labels. Then, the dual-knowledge cooperation scheme integrates current model specialization and historical model generalization, refining noisy pseudo-labels. Through this cyclic design, reliable pseudo-labels are progressively mined to improve current-stage learning and ensure positive knowledge propagation over long-term learning. Experiments on the established Semi-LReID benchmarks show that our SPRED achieves state-of-the-art performance. Our source code is available at https://github.com/zhoujiahuan1991/ICCV2025-SPRED
Componential Prompt-Knowledge Alignment for Domain Incremental Learning
May 07, 2025Domain Incremental Learning (DIL) aims to learn from non-stationary data streams across domains while retaining and utilizing past knowledge. Although prompt-based methods effectively store multi-domain knowledge in prompt parameters and obtain advanced performance through cross-domain prompt fusion, we reveal an intrinsic limitation: component-wise misalignment between domain-specific prompts leads to conflicting knowledge integration and degraded predictions. This arises from the random positioning of knowledge components within prompts, where irrelevant component fusion introduces interference.To address this, we propose Componential Prompt-Knowledge Alignment (KA-Prompt), a novel prompt-based DIL method that introduces component-aware prompt-knowledge alignment during training, significantly improving both the learning and inference capacity of the model. KA-Prompt operates in two phases: (1) Initial Componential Structure Configuring, where a set of old prompts containing knowledge relevant to the new domain are mined via greedy search, which is then exploited to initialize new prompts to achieve reusable knowledge transfer and establish intrinsic alignment between new and old prompts. (2) Online Alignment Preservation, which dynamically identifies the target old prompts and applies adaptive componential consistency constraints as new prompts evolve. Extensive experiments on DIL benchmarks demonstrate the effectiveness of our KA-Prompt. Our source code is available at https://github.com/zhoujiahuan1991/ICML2025-KA-Prompt
STOP: Integrated Spatial-Temporal Dynamic Prompting for Video Understanding
Mar 20, 2025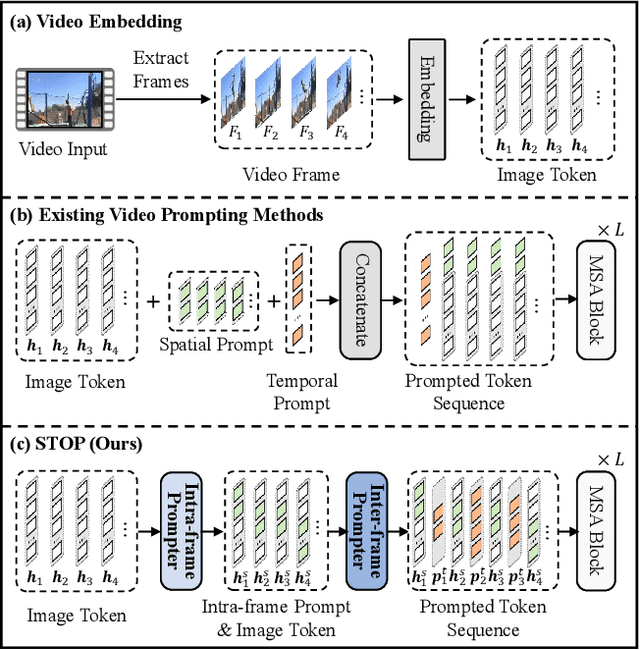
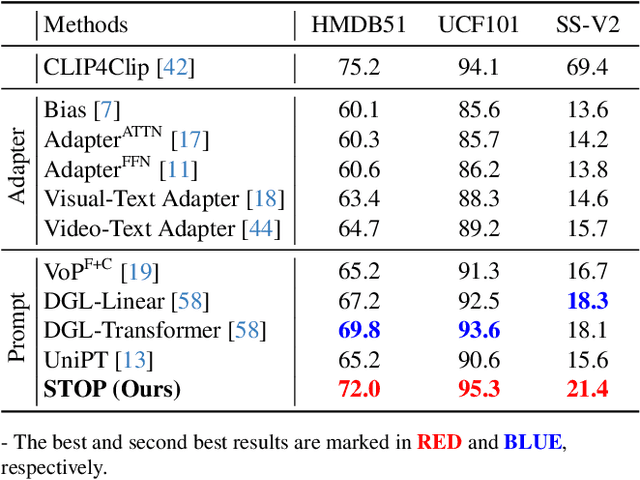
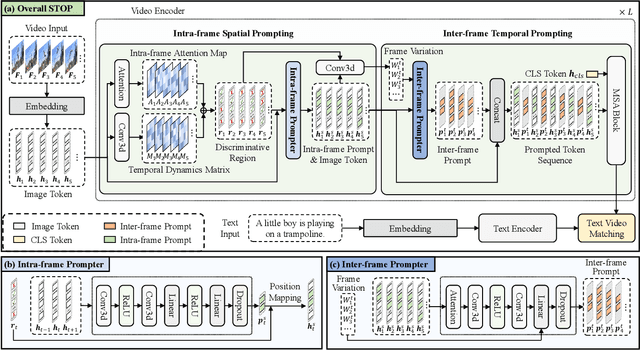
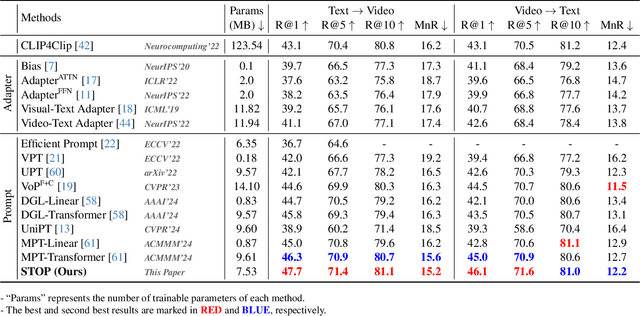
Pre-trained on tremendous image-text pairs, vision-language models like CLIP have demonstrated promising zero-shot generalization across numerous image-based tasks. However, extending these capabilities to video tasks remains challenging due to limited labeled video data and high training costs. Recent video prompting methods attempt to adapt CLIP for video tasks by introducing learnable prompts, but they typically rely on a single static prompt for all video sequences, overlooking the diverse temporal dynamics and spatial variations that exist across frames. This limitation significantly hinders the model's ability to capture essential temporal information for effective video understanding. To address this, we propose an integrated Spatial-TempOral dynamic Prompting (STOP) model which consists of two complementary modules, the intra-frame spatial prompting and inter-frame temporal prompting. Our intra-frame spatial prompts are designed to adaptively highlight discriminative regions within each frame by leveraging intra-frame attention and temporal variation, allowing the model to focus on areas with substantial temporal dynamics and capture fine-grained spatial details. Additionally, to highlight the varying importance of frames for video understanding, we further introduce inter-frame temporal prompts, dynamically inserting prompts between frames with high temporal variance as measured by frame similarity. This enables the model to prioritize key frames and enhances its capacity to understand temporal dependencies across sequences. Extensive experiments on various video benchmarks demonstrate that STOP consistently achieves superior performance against state-of-the-art methods. The code is available at https://github.com/zhoujiahuan1991/CVPR2025-STOP.
SCAP: Transductive Test-Time Adaptation via Supportive Clique-based Attribute Prompting
Mar 17, 2025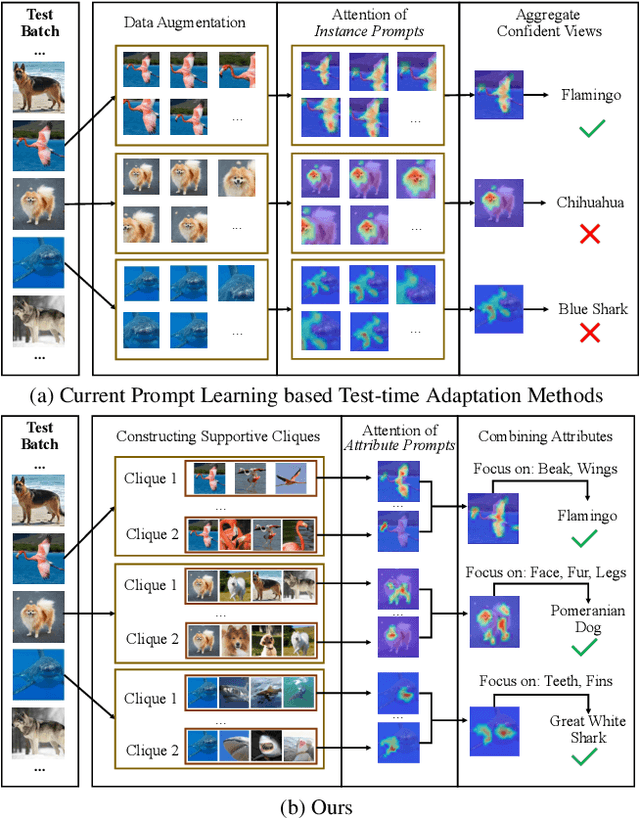
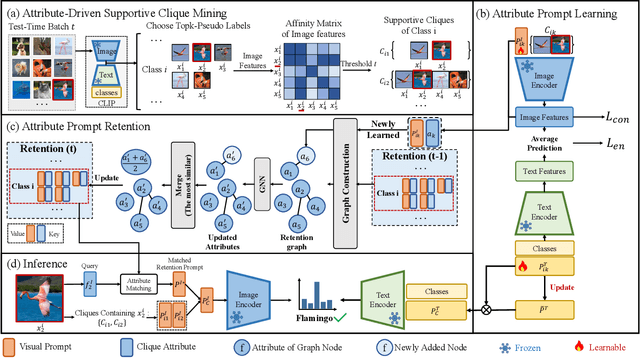
Vision-language models (VLMs) encounter considerable challenges when adapting to domain shifts stemming from changes in data distribution. Test-time adaptation (TTA) has emerged as a promising approach to enhance VLM performance under such conditions. In practice, test data often arrives in batches, leading to increasing interest in the transductive TTA setting. However, existing TTA methods primarily focus on individual test samples, overlooking crucial cross-sample correlations within a batch. While recent ViT-based TTA methods have introduced batch-level adaptation, they remain suboptimal for VLMs due to inadequate integration of the text modality. To address these limitations, we propose a novel transductive TTA framework, Supportive Clique-based Attribute Prompting (SCAP), which effectively combines visual and textual information to enhance adaptation by generating fine-grained attribute prompts across test batches. SCAP first forms supportive cliques of test samples in an unsupervised manner based on visual similarity and learns an attribute prompt for each clique, capturing shared attributes critical for adaptation. For each test sample, SCAP aggregates attribute prompts from its associated cliques, providing enriched contextual information. To ensure adaptability over time, we incorporate a retention module that dynamically updates attribute prompts and their associated attributes as new data arrives. Comprehensive experiments across multiple benchmarks demonstrate that SCAP outperforms existing state-of-the-art methods, significantly advancing VLM generalization under domain shifts. Our code is available at https://github.com/zhoujiahuan1991/CVPR2025-SCAP.
DASK: Distribution Rehearsing via Adaptive Style Kernel Learning for Exemplar-Free Lifelong Person Re-Identification
Dec 12, 2024



Lifelong person re-identification (LReID) is an important but challenging task that suffers from catastrophic forgetting due to significant domain gaps between training steps. Existing LReID approaches typically rely on data replay and knowledge distillation to mitigate this issue. However, data replay methods compromise data privacy by storing historical exemplars, while knowledge distillation methods suffer from limited performance due to the cumulative forgetting of undistilled knowledge. To overcome these challenges, we propose a novel paradigm that models and rehearses the distribution of the old domains to enhance knowledge consolidation during the new data learning, possessing a strong anti-forgetting capacity without storing any exemplars. Specifically, we introduce an exemplar-free LReID method called Distribution Rehearsing via Adaptive Style Kernel Learning (DASK). DASK includes a Distribution Rehearser Learning mechanism that learns to transform arbitrary distribution data into the current data style at each learning step. To enhance the style transfer capacity of DRL, an Adaptive Kernel Prediction network is explored to achieve an instance-specific distribution adjustment. Additionally, we design a Distribution Rehearsing-driven LReID Training module, which rehearses old distribution based on the new data via the old AKPNet model, achieving effective new-old knowledge accumulation under a joint knowledge consolidation scheme. Experimental results show our DASK outperforms the existing methods by 3.6%-6.8% and 4.5%-6.5% on anti-forgetting and generalization capacity, respectively. Our code is available at https://github.com/zhoujiahuan1991/AAAI2025-DASK
Deep Learning Techniques for Automatic Lateral X-ray Cephalometric Landmark Detection: Is the Problem Solved?
Sep 24, 2024Localization of the craniofacial landmarks from lateral cephalograms is a fundamental task in cephalometric analysis. The automation of the corresponding tasks has thus been the subject of intense research over the past decades. In this paper, we introduce the "Cephalometric Landmark Detection (CL-Detection)" dataset, which is the largest publicly available and comprehensive dataset for cephalometric landmark detection. This multi-center and multi-vendor dataset includes 600 lateral X-ray images with 38 landmarks acquired with different equipment from three medical centers. The overarching objective of this paper is to measure how far state-of-the-art deep learning methods can go for cephalometric landmark detection. Following the 2023 MICCAI CL-Detection Challenge, we report the results of the top ten research groups using deep learning methods. Results show that the best methods closely approximate the expert analysis, achieving a mean detection rate of 75.719% and a mean radial error of 1.518 mm. While there is room for improvement, these findings undeniably open the door to highly accurate and fully automatic location of craniofacial landmarks. We also identify scenarios for which deep learning methods are still failing. Both the dataset and detailed results are publicly available online, while the platform will remain open for the community to benchmark future algorithm developments at https://cl-detection2023.grand-challenge.org/.
Category-Aware Transformer Network for Better Human-Object Interaction Detection
Apr 11, 2022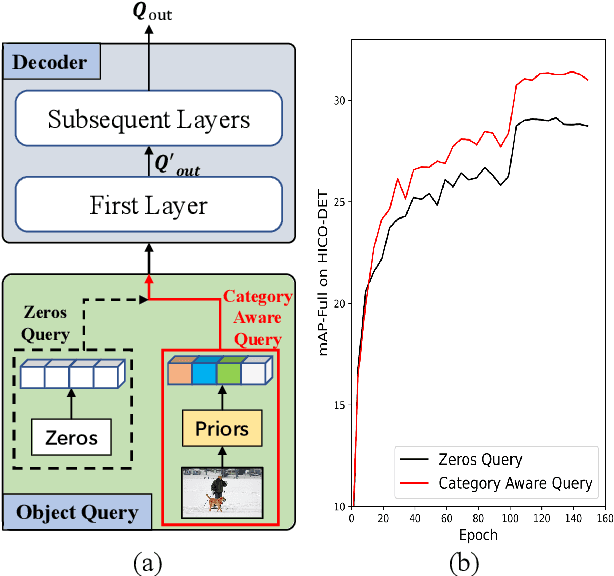
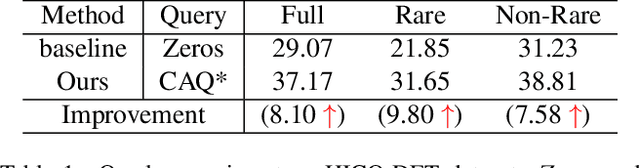
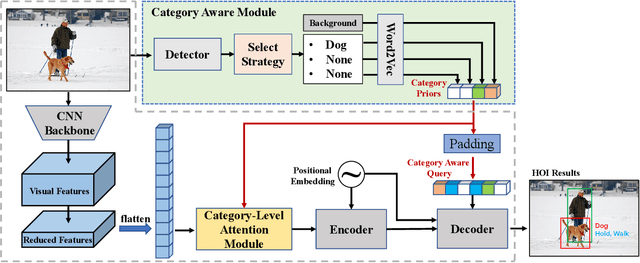
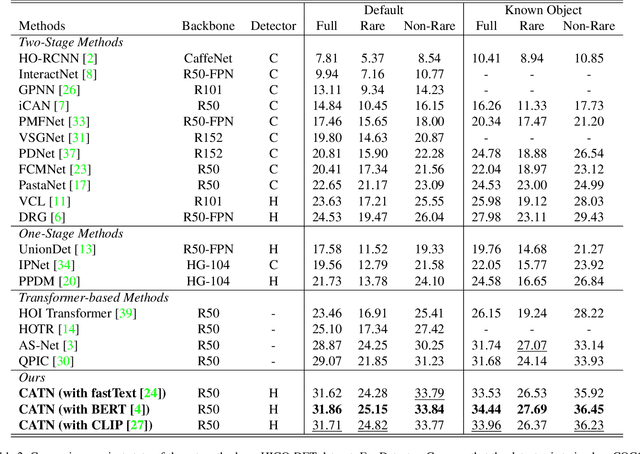
Human-Object Interactions (HOI) detection, which aims to localize a human and a relevant object while recognizing their interaction, is crucial for understanding a still image. Recently, transformer-based models have significantly advanced the progress of HOI detection. However, the capability of these models has not been fully explored since the Object Query of the model is always simply initialized as just zeros, which would affect the performance. In this paper, we try to study the issue of promoting transformer-based HOI detectors by initializing the Object Query with category-aware semantic information. To this end, we innovatively propose the Category-Aware Transformer Network (CATN). Specifically, the Object Query would be initialized via category priors represented by an external object detection model to yield better performance. Moreover, such category priors can be further used for enhancing the representation ability of features via the attention mechanism. We have firstly verified our idea via the Oracle experiment by initializing the Object Query with the groundtruth category information. And then extensive experiments have been conducted to show that a HOI detection model equipped with our idea outperforms the baseline by a large margin to achieve a new state-of-the-art result.
Effective Actor-centric Human-object Interaction Detection
Feb 24, 2022
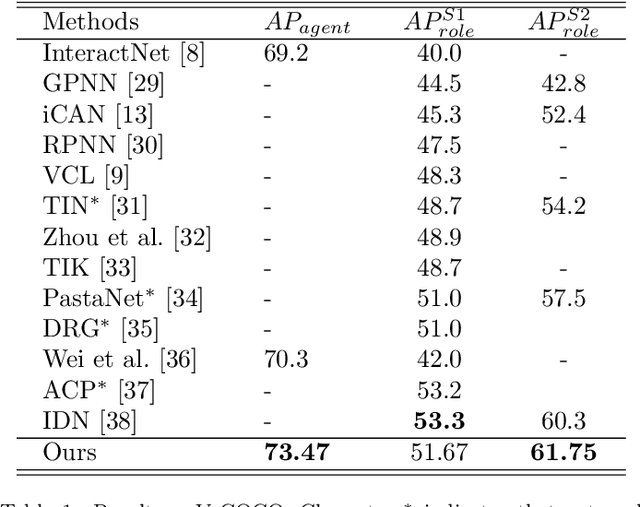
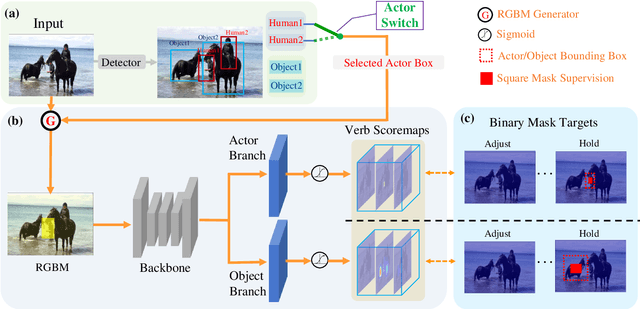
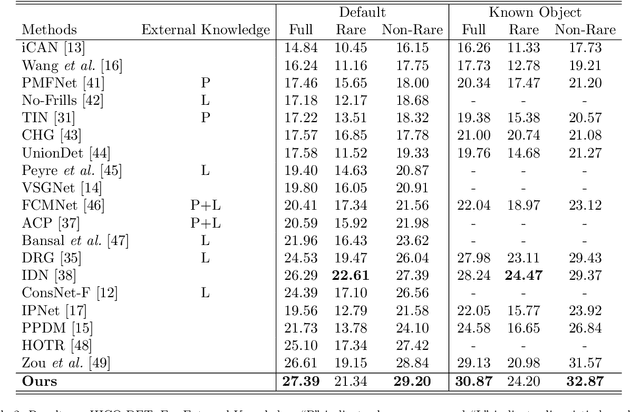
While Human-Object Interaction(HOI) Detection has achieved tremendous advances in recent, it still remains challenging due to complex interactions with multiple humans and objects occurring in images, which would inevitably lead to ambiguities. Most existing methods either generate all human-object pair candidates and infer their relationships by cropped local features successively in a two-stage manner, or directly predict interaction points in a one-stage procedure. However, the lack of spatial configurations or reasoning steps of two- or one- stage methods respectively limits their performance in such complex scenes. To avoid this ambiguity, we propose a novel actor-centric framework. The main ideas are that when inferring interactions: 1) the non-local features of the entire image guided by actor position are obtained to model the relationship between the actor and context, and then 2) we use an object branch to generate pixel-wise interaction area prediction, where the interaction area denotes the object central area. Moreover, we also use an actor branch to get interaction prediction of the actor and propose a novel composition strategy based on center-point indexing to generate the final HOI prediction. Thanks to the usage of the non-local features and the partly-coupled property of the human-objects composition strategy, our proposed framework can detect HOI more accurately especially for complex images. Extensive experimental results show that our method achieves the state-of-the-art on the challenging V-COCO and HICO-DET benchmarks and is more robust especially in multiple persons and/or objects scenes.