 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchorDiff: Training-Free Concept Grounding for MM-DiTs via Anchor-Based Graph Propagation
May 26, 2026Multi-Modal Diffusion Transformers (MM-DiTs) encode rich representations for training-free concept grounding, but existing attention-based methods often produce overlapping activations on visually confusable concepts, a failure mode we call concept leakage, where target responses spill over to non-target objects. To address this issue, we propose AnchorDiff, a training-free grounding method that decouples semantic localization from structural refinement. AnchorDiff selects a high-confidence anchor from concept-to-image attention map and propagates it as a one-hot seed over a hybrid graph derived from image-to-image self-attention. The graph uses output-space similarity for dense within-object propagation and a row-wise attention gate to suppress cross-object connections. Additionally, we introduce the Multi-Concept Confusion Dataset, which contains images with multiple visually similar concepts and separate masks, enabling explicit evaluation of concept leakage. Experiments show that AnchorDiff achieves strong grounding performance on ImageNet-Segmentation and PascalVOC, while substantially reducing concept leakage on our Multi-Concept Confusion Dataset.
EMOdiffhead: Continuously Emotional Control in Talking Head Generation via Diffusion
Sep 11, 2024



The task of audio-driven portrait animation involves generating a talking head video using an identity image and an audio track of speech. While many existing approaches focus on lip synchronization and video quality, few tackle the challenge of generating emotion-driven talking head videos. The ability to control and edit emotions is essential for producing expressive and realistic animations. In response to this challenge, we propose EMOdiffhead, a novel method for emotional talking head video generation that not only enables fine-grained control of emotion categories and intensities but also enables one-shot generation. Given the FLAME 3D model's linearity in expression modeling, we utilize the DECA method to extract expression vectors, that are combined with audio to guide a diffusion model in generating videos with precise lip synchronization and rich emotional expressiveness. This approach not only enables the learning of rich facial information from emotion-irrelevant data but also facilitates the generation of emotional videos. It effectively overcomes the limitations of emotional data, such as the lack of diversity in facial and background information, and addresses the absence of emotional details in emotion-irrelevant data. Extensive experiments and user studies demonstrate that our approach achieves state-of-the-art performance compared to other emotion portrait animation methods.
Brain-Conditional Multimodal Synthesis: A Survey and Taxonomy
Jan 03, 2024In the era of Artificial Intelligence Generated Content (AIGC), conditional multimodal synthesis technologies (e.g., text-to-image, text-to-video, text-to-audio, etc) are gradually reshaping the natural content in the real world. The key to multimodal synthesis technology is to establish the mapping relationship between different modalities. Brain signals, serving as potential reflections of how the brain interprets external information, exhibit a distinctive One-to-Many correspondence with various external modalities. This correspondence makes brain signals emerge as a promising guiding condition for multimodal content synthesis. Brian-conditional multimodal synthesis refers to decoding brain signals back to perceptual experience, which is crucial for developing practical brain-computer interface systems and unraveling complex mechanisms underlying how the brain perceives and comprehends external stimuli. This survey comprehensively examines the emerging field of AIGC-based Brain-conditional Multimodal Synthesis, termed AIGC-Brain, to delineate the current landscape and future directions. To begin, related brain neuroimaging datasets, functional brain regions, and mainstream generative models are introduced as the foundation of AIGC-Brain decoding and analysis. Next, we provide a comprehensive taxonomy for AIGC-Brain decoding models and present task-specific representative work and detailed implementation strategies to facilitate comparison and in-depth analysis. Quality assessments are then introduced for both qualitative and quantitative evaluation. Finally, this survey explores insights gained, providing current challenges and outlining prospects of AIGC-Brain. Being the inaugural survey in this domain, this paper paves the way for the progress of AIGC-Brain research, offering a foundational overview to guide future work.
A Grammatical Compositional Model for Video Action Detection
Oct 04, 2023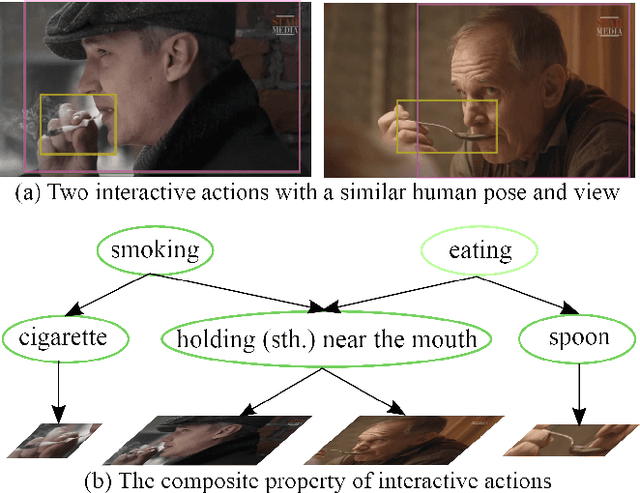

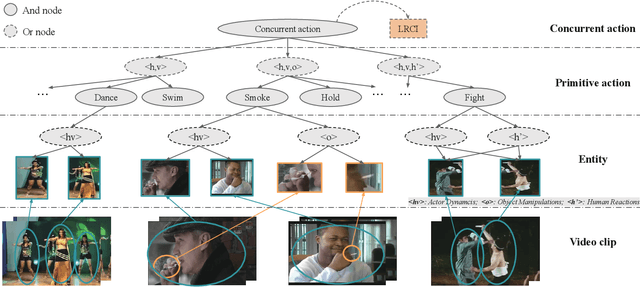

Analysis of human actions in videos demands understanding complex human dynamics, as well as the interaction between actors and context. However, these interaction relationships usually exhibit large intra-class variations from diverse human poses or object manipulations, and fine-grained inter-class differences between similar actions. Thus the performance of existing methods is severely limited. Motivated by the observation that interactive actions can be decomposed into actor dynamics and participating objects or humans, we propose to investigate the composite property of them. In this paper, we present a novel Grammatical Compositional Model (GCM) for action detection based on typical And-Or graphs. Our model exploits the intrinsic structures and latent relationships of actions in a hierarchical manner to harness both the compositionality of grammar models and the capability of expressing rich features of DNNs. The proposed model can be readily embodied into a neural network module for efficient optimization in an end-to-end manner. Extensive experiments are conducted on the AVA dataset and the Something-Else task to demonstrate the superiority of our model, meanwhile the interpretability is enhanced through an inference parsing procedure.
UniBrain: Unify Image Reconstruction and Captioning All in One Diffusion Model from Human Brain Activity
Aug 14, 2023



Image reconstruction and captioning from brain activity evoked by visual stimuli allow researchers to further understand the connection between the human brain and the visual perception system. While deep generative models have recently been employed in this field, reconstructing realistic captions and images with both low-level details and high semantic fidelity is still a challenging problem. In this work, we propose UniBrain: Unify Image Reconstruction and Captioning All in One Diffusion Model from Human Brain Activity. For the first time, we unify image reconstruction and captioning from visual-evoked functional magnetic resonance imaging (fMRI) through a latent diffusion model termed Versatile Diffusion. Specifically, we transform fMRI voxels into text and image latent for low-level information and guide the backward diffusion process through fMRI-based image and text conditions derived from CLIP to generate realistic captions and images. UniBrain outperforms current methods both qualitatively and quantitatively in terms of image reconstruction and reports image captioning results for the first time on the Natural Scenes Dataset (NSD) dataset. Moreover, the ablation experiments and functional region-of-interest (ROI) analysis further exhibit the superiority of UniBrain and provide comprehensive insight for visual-evoked brain decoding.
Base Placement Optimization for Coverage Mobile Manipulation Tasks
Apr 17, 2023
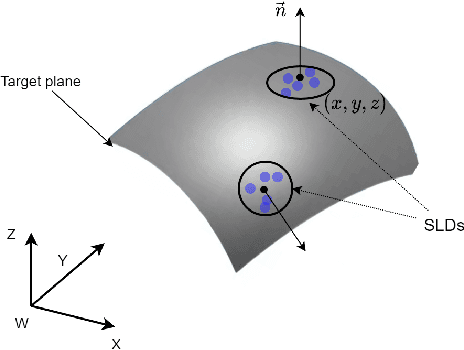
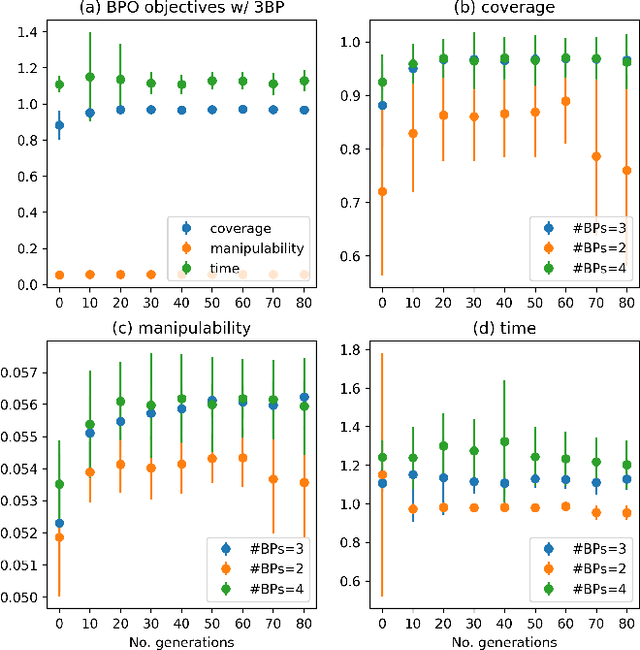
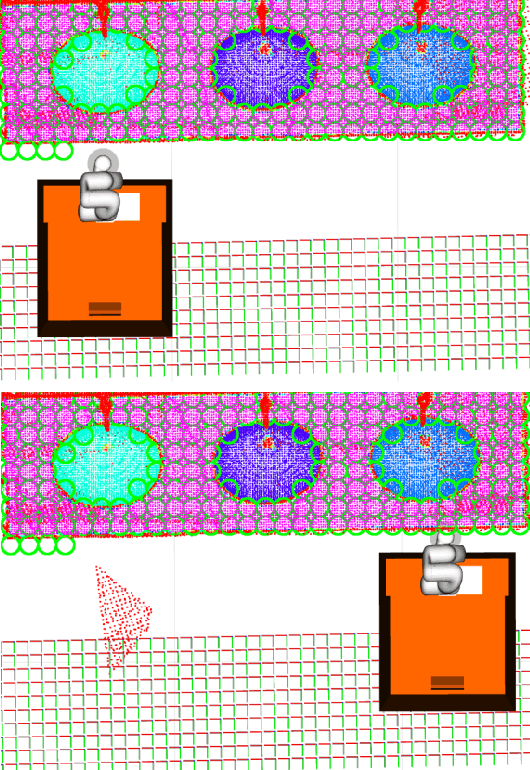
Base placement optimization (BPO) is a fundamental capability for mobile manipulation and has been researched for decades. However, it is still very challenging for some reasons. First, compared with humans, current robots are extremely inflexible, and therefore have higher requirements on the accuracy of base placements (BPs). Second, the BP and task constraints are coupled with each other. The optimal BP depends on the task constraints, and in BP will affect task constraints in turn. More tricky is that some task constraints are flexible and non-deterministic. Third, except for fulfilling tasks, some other performance metrics such as optimal energy consumption and minimal execution time need to be considered, which makes the BPO problem even more complicated. In this paper, a Scale-like disc (SLD) representation of the workspace is used to decouple task constraints and BPs. To evaluate reachability and return optimal working pose over SLDs, a reachability map (RM) is constructed offline. In order to optimize the objectives of coverage, manipulability, and time cost simultaneously, this paper formulates the BPO as a multi-objective optimization problem (MOOP). Among them, the time optimal objective is modeled as a traveling salesman problem (TSP), which is more in line with the actual situation. The evolutionary method is used to solve the MOOP. Besides, to ensure the validity and optimality of the solution, collision detection is performed on the candidate BPs, and solutions from BPO are further fine-tuned according to the specific given task. Finally, the proposed method is used to solve a real-world toilet coverage cleaning task. Experiments show that the optimized BPs can significantly improve the coverage and efficiency of the task.
High-Fidelity Variable-Rate Image Compression via Invertible Activation Transformation
Sep 12, 2022
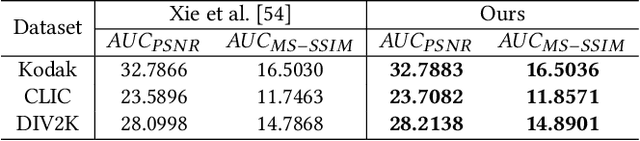
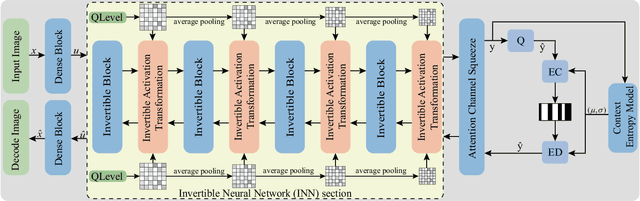
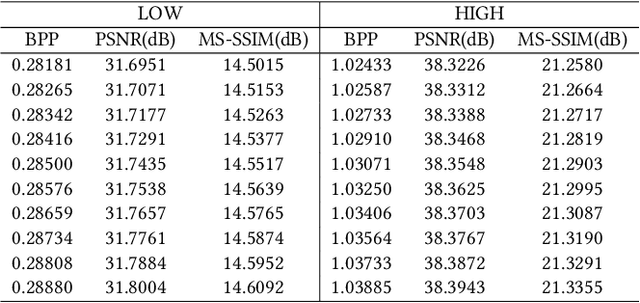
Learning-based methods have effectively promoted the community of image compression. Meanwhile, variational autoencoder (VAE) based variable-rate approaches have recently gained much attention to avoid the usage of a set of different networks for various compression rates. Despite the remarkable performance that has been achieved, these approaches would be readily corrupted once multiple compression/decompression operations are executed, resulting in the fact that image quality would be tremendously dropped and strong artifacts would appear. Thus, we try to tackle the issue of high-fidelity fine variable-rate image compression and propose the Invertible Activation Transformation (IAT) module. We implement the IAT in a mathematical invertible manner on a single rate Invertible Neural Network (INN) based model and the quality level (QLevel) would be fed into the IAT to generate scaling and bias tensors. IAT and QLevel together give the image compression model the ability of fine variable-rate control while better maintaining the image fidelity. Extensive experiments demonstrate that the single rate image compression model equipped with our IAT module has the ability to achieve variable-rate control without any compromise. And our IAT-embedded model obtains comparable rate-distortion performance with recent learning-based image compression methods. Furthermore, our method outperforms the state-of-the-art variable-rate image compression method by a large margin, especially after multiple re-encodings.
Category-Aware Transformer Network for Better Human-Object Interaction Detection
Apr 11, 2022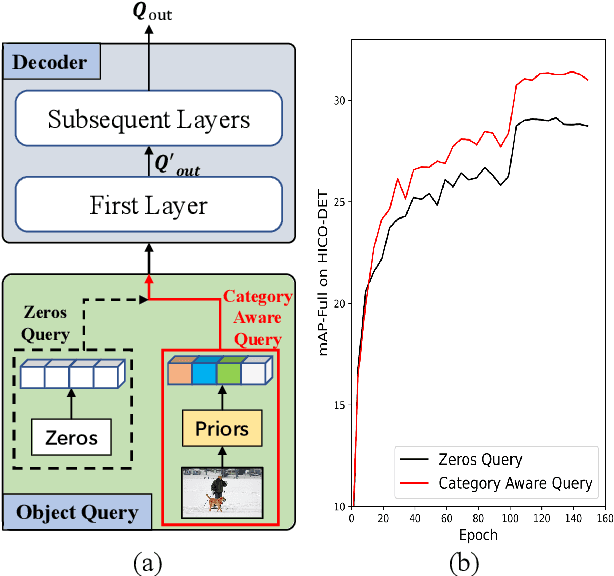
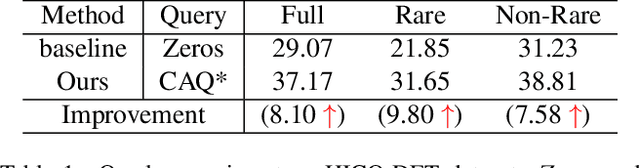
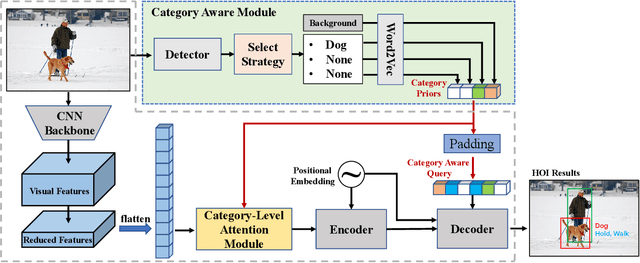
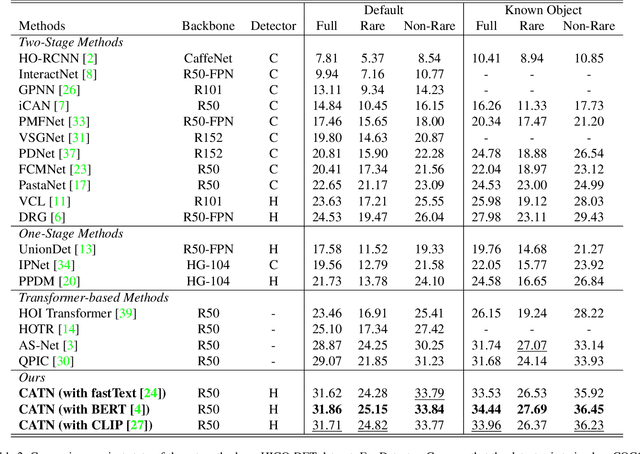
Human-Object Interactions (HOI) detection, which aims to localize a human and a relevant object while recognizing their interaction, is crucial for understanding a still image. Recently, transformer-based models have significantly advanced the progress of HOI detection. However, the capability of these models has not been fully explored since the Object Query of the model is always simply initialized as just zeros, which would affect the performance. In this paper, we try to study the issue of promoting transformer-based HOI detectors by initializing the Object Query with category-aware semantic information. To this end, we innovatively propose the Category-Aware Transformer Network (CATN). Specifically, the Object Query would be initialized via category priors represented by an external object detection model to yield better performance. Moreover, such category priors can be further used for enhancing the representation ability of features via the attention mechanism. We have firstly verified our idea via the Oracle experiment by initializing the Object Query with the groundtruth category information. And then extensive experiments have been conducted to show that a HOI detection model equipped with our idea outperforms the baseline by a large margin to achieve a new state-of-the-art result.
Effective Actor-centric Human-object Interaction Detection
Feb 24, 2022
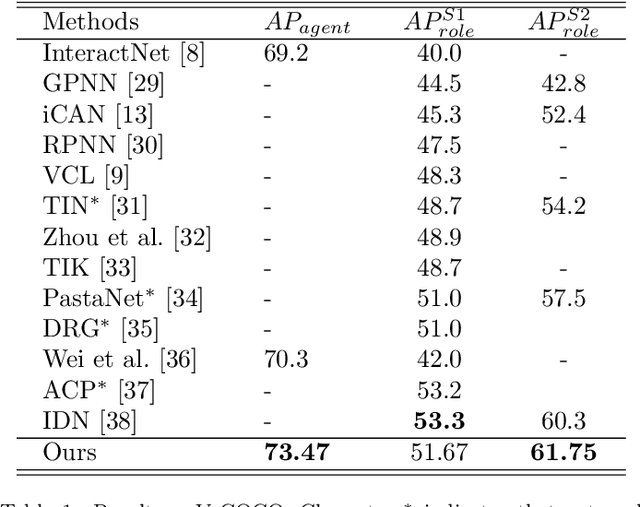
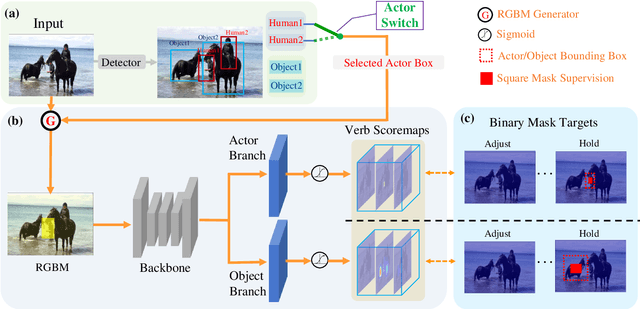
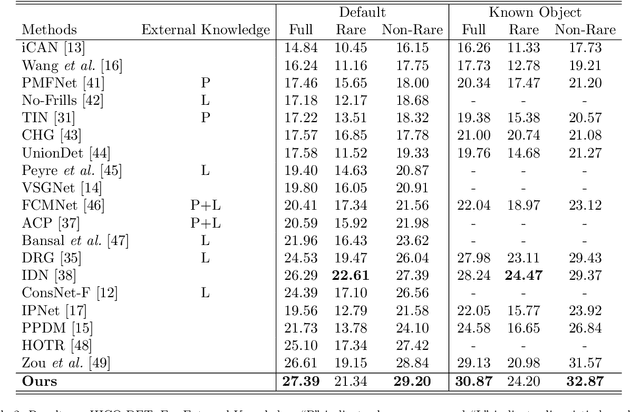
While Human-Object Interaction(HOI) Detection has achieved tremendous advances in recent, it still remains challenging due to complex interactions with multiple humans and objects occurring in images, which would inevitably lead to ambiguities. Most existing methods either generate all human-object pair candidates and infer their relationships by cropped local features successively in a two-stage manner, or directly predict interaction points in a one-stage procedure. However, the lack of spatial configurations or reasoning steps of two- or one- stage methods respectively limits their performance in such complex scenes. To avoid this ambiguity, we propose a novel actor-centric framework. The main ideas are that when inferring interactions: 1) the non-local features of the entire image guided by actor position are obtained to model the relationship between the actor and context, and then 2) we use an object branch to generate pixel-wise interaction area prediction, where the interaction area denotes the object central area. Moreover, we also use an actor branch to get interaction prediction of the actor and propose a novel composition strategy based on center-point indexing to generate the final HOI prediction. Thanks to the usage of the non-local features and the partly-coupled property of the human-objects composition strategy, our proposed framework can detect HOI more accurately especially for complex images. Extensive experimental results show that our method achieves the state-of-the-art on the challenging V-COCO and HICO-DET benchmarks and is more robust especially in multiple persons and/or objects scenes.
Learning Oriented Remote Sensing Object Detection via Naive Geometric Computing
Dec 01, 2021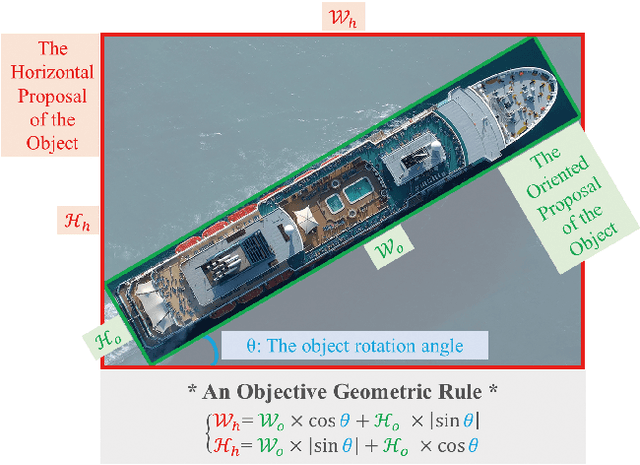
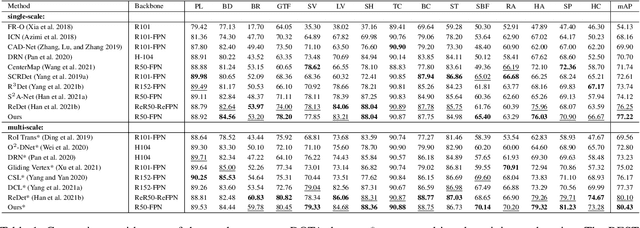
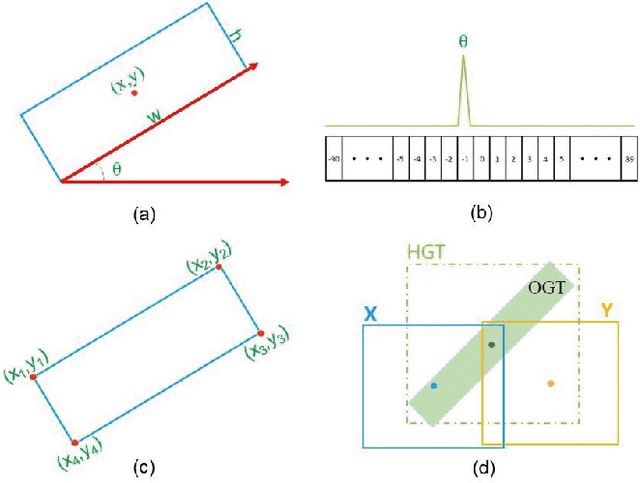
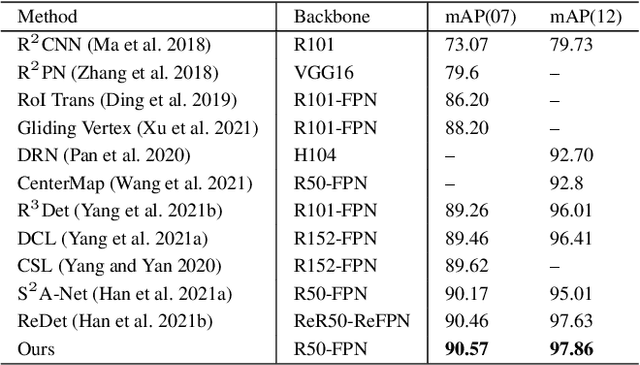
Detecting oriented objects along with estimating their rotation information is one crucial step for analyzing remote sensing images. Despite that many methods proposed recently have achieved remarkable performance, most of them directly learn to predict object directions under the supervision of only one (e.g. the rotation angle) or a few (e.g. several coordinates) groundtruth values individually. Oriented object detection would be more accurate and robust if extra constraints, with respect to proposal and rotation information regression, are adopted for joint supervision during training. To this end, we innovatively propose a mechanism that simultaneously learns the regression of horizontal proposals, oriented proposals, and rotation angles of objects in a consistent manner, via naive geometric computing, as one additional steady constraint (see Figure 1). An oriented center prior guided label assignment strategy is proposed for further enhancing the quality of proposals, yielding better performance. Extensive experiments demonstrate the model equipped with our idea significantly outperforms the baseline by a large margin to achieve a new state-of-the-art result without any extra computational burden during inference. Our proposed idea is simple and intuitive that can be readily implemented. Source codes and trained models are involved in supplementary files.