 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR4-CGQA: Retrieval-based Vision Language Models for Computer Graphics Image Quality Assessment
Mar 11, 2026Immersive Computer Graphics (CGs) rendering has become ubiquitous in modern daily life. However, comprehensively evaluating CG quality remains challenging for two reasons: First, existing CG datasets lack systematic descriptions of rendering quality; and second existing CG quality assessment methods cannot provide reasonable text-based explanations. To address these issues, we first identify six key perceptual dimensions of CG quality from the user perspective and construct a dataset of 3500 CG images with corresponding quality descriptions. Each description covers CG style, content, and perceived quality along the selected dimensions. Furthermore, we use a subset of the dataset to build several question-answer benchmarks based on the descriptions in order to evaluate the responses of existing Vision Language Models (VLMs). We find that current VLMs are not sufficiently accurate in judging fine-grained CG quality, but that descriptions of visually similar images can significantly improve a VLM's understanding of a given CG image. Motivated by this observation, we adopt retrieval-augmented generation and propose a two-stream retrieval framework that effectively enhances the CG quality assessment capabilities of VLMs. Experiments on several representative VLMs demonstrate that our method substantially improves their performance on CG quality assessment.
MUGSQA: Novel Multi-Uncertainty-Based Gaussian Splatting Quality Assessment Method, Dataset, and Benchmarks
Nov 10, 2025

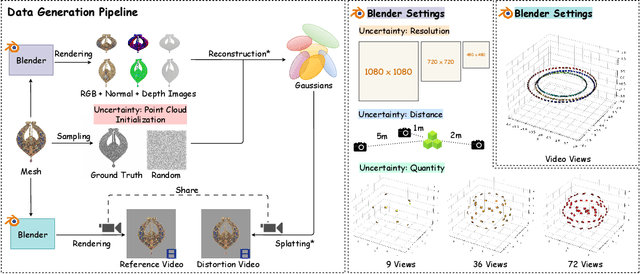
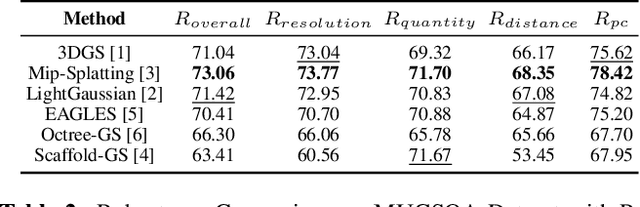
Gaussian Splatting (GS) has recently emerged as a promising technique for 3D object reconstruction, delivering high-quality rendering results with significantly improved reconstruction speed. As variants continue to appear, assessing the perceptual quality of 3D objects reconstructed with different GS-based methods remains an open challenge. To address this issue, we first propose a unified multi-distance subjective quality assessment method that closely mimics human viewing behavior for objects reconstructed with GS-based methods in actual applications, thereby better collecting perceptual experiences. Based on it, we also construct a novel GS quality assessment dataset named MUGSQA, which is constructed considering multiple uncertainties of the input data. These uncertainties include the quantity and resolution of input views, the view distance, and the accuracy of the initial point cloud. Moreover, we construct two benchmarks: one to evaluate the robustness of various GS-based reconstruction methods under multiple uncertainties, and the other to evaluate the performance of existing quality assessment metrics. Our dataset and benchmark code will be released soon.
Divide-and-Conquer: Dual-Hierarchical Optimization for Semantic 4D Gaussian Spatting
Mar 25, 2025Semantic 4D Gaussians can be used for reconstructing and understanding dynamic scenes, with temporal variations than static scenes. Directly applying static methods to understand dynamic scenes will fail to capture the temporal features. Few works focus on dynamic scene understanding based on Gaussian Splatting, since once the same update strategy is employed for both dynamic and static parts, regardless of the distinction and interaction between Gaussians, significant artifacts and noise appear. We propose Dual-Hierarchical Optimization (DHO), which consists of Hierarchical Gaussian Flow and Hierarchical Gaussian Guidance in a divide-and-conquer manner. The former implements effective division of static and dynamic rendering and features. The latter helps to mitigate the issue of dynamic foreground rendering distortion in textured complex scenes. Extensive experiments show that our method consistently outperforms the baselines on both synthetic and real-world datasets, and supports various downstream tasks. Project Page: https://sweety-yan.github.io/DHO.
Perceptual-Distortion Balanced Image Super-Resolution is a Multi-Objective Optimization Problem
Sep 05, 2024

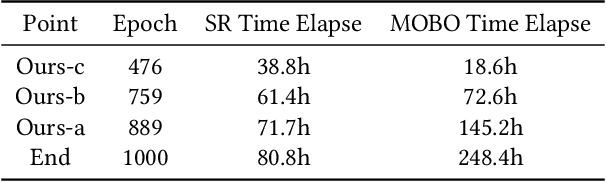

Training Single-Image Super-Resolution (SISR) models using pixel-based regression losses can achieve high distortion metrics scores (e.g., PSNR and SSIM), but often results in blurry images due to insufficient recovery of high-frequency details. Conversely, using GAN or perceptual losses can produce sharp images with high perceptual metric scores (e.g., LPIPS), but may introduce artifacts and incorrect textures. Balancing these two types of losses can help achieve a trade-off between distortion and perception, but the challenge lies in tuning the loss function weights. To address this issue, we propose a novel method that incorporates Multi-Objective Optimization (MOO) into the training process of SISR models to balance perceptual quality and distortion. We conceptualize the relationship between loss weights and image quality assessment (IQA) metrics as black-box objective functions to be optimized within our Multi-Objective Bayesian Optimization Super-Resolution (MOBOSR) framework. This approach automates the hyperparameter tuning process, reduces overall computational cost, and enables the use of numerous loss functions simultaneously. Extensive experiments demonstrate that MOBOSR outperforms state-of-the-art methods in terms of both perceptual quality and distortion, significantly advancing the perception-distortion Pareto frontier. Our work points towards a new direction for future research on balancing perceptual quality and fidelity in nearly all image restoration tasks. The source code and pretrained models are available at: https://github.com/ZhuKeven/MOBOSR.
Powerful Lossy Compression for Noisy Images
Mar 26, 2024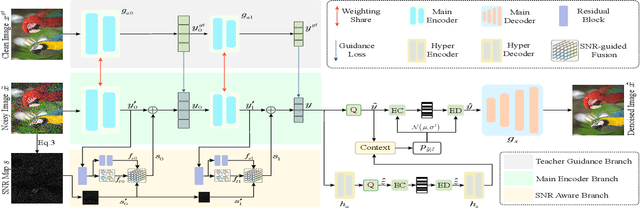
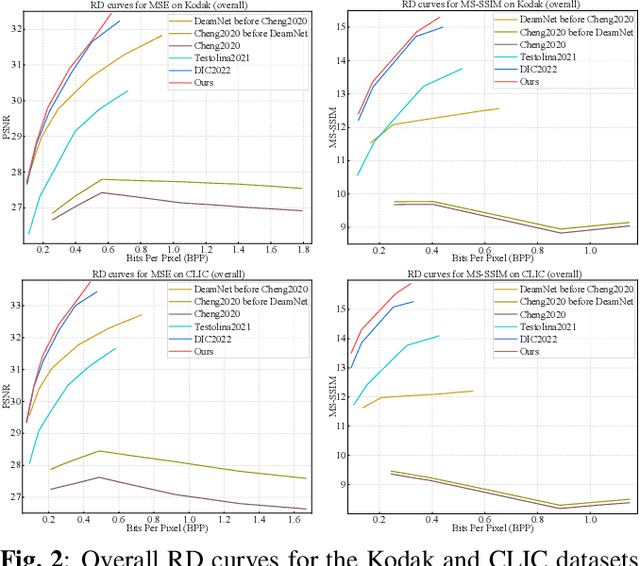
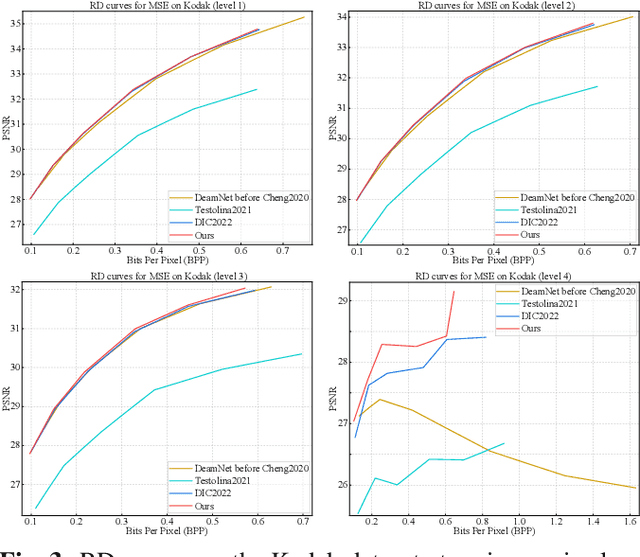
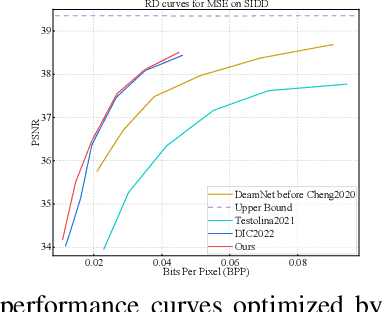
Image compression and denoising represent fundamental challenges in image processing with many real-world applications. To address practical demands, current solutions can be categorized into two main strategies: 1) sequential method; and 2) joint method. However, sequential methods have the disadvantage of error accumulation as there is information loss between multiple individual models. Recently, the academic community began to make some attempts to tackle this problem through end-to-end joint methods. Most of them ignore that different regions of noisy images have different characteristics. To solve these problems, in this paper, our proposed signal-to-noise ratio~(SNR) aware joint solution exploits local and non-local features for image compression and denoising simultaneously. We design an end-to-end trainable network, which includes the main encoder branch, the guidance branch, and the signal-to-noise ratio~(SNR) aware branch. We conducted extensive experiments on both synthetic and real-world datasets, demonstrating that our joint solution outperforms existing state-of-the-art methods.
Jointly Optimizing Image Compression with Low-light Image Enhancement
May 24, 2023
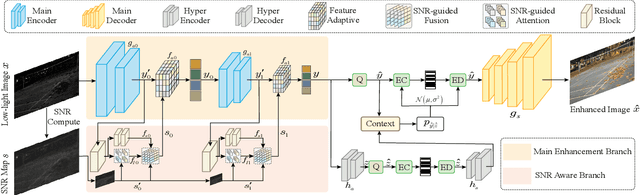
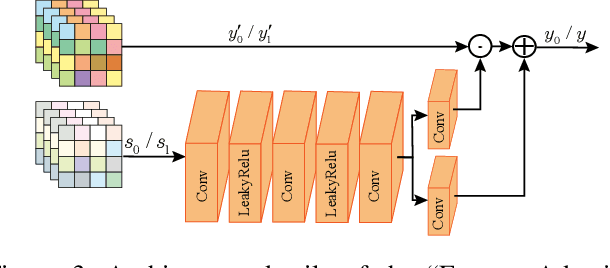
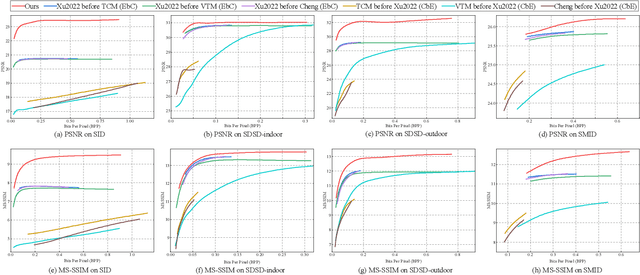
Learning-based image compression methods have made great progress. Most of them are designed for generic natural images. In fact, low-light images frequently occur due to unavoidable environmental influences or technical limitations, such as insufficient lighting or limited exposure time. %When general-purpose image compression algorithms compress low-light images, useful detail information is lost, resulting in a dramatic decrease in image enhancement. Once low-light images are compressed by existing general image compression approaches, useful information(e.g., texture details) would be lost resulting in a dramatic performance decrease in low-light image enhancement. To simultaneously achieve a higher compression rate and better enhancement performance for low-light images, we propose a novel image compression framework with joint optimization of low-light image enhancement. We design an end-to-end trainable two-branch architecture with lower computational cost, which includes the main enhancement branch and the signal-to-noise ratio~(SNR) aware branch. Experimental results show that our proposed joint optimization framework achieves a significant improvement over existing ``Compress before Enhance" or ``Enhance before Compress" sequential solutions for low-light images. Source codes are included in the supplementary material.
High-Fidelity Variable-Rate Image Compression via Invertible Activation Transformation
Sep 12, 2022
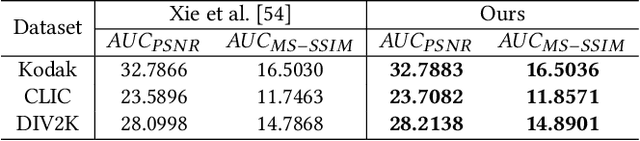
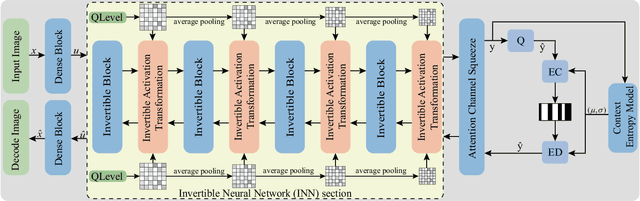
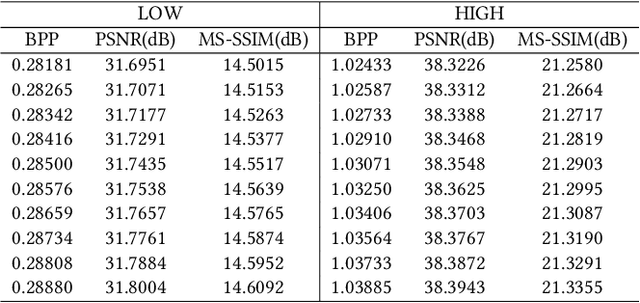
Learning-based methods have effectively promoted the community of image compression. Meanwhile, variational autoencoder (VAE) based variable-rate approaches have recently gained much attention to avoid the usage of a set of different networks for various compression rates. Despite the remarkable performance that has been achieved, these approaches would be readily corrupted once multiple compression/decompression operations are executed, resulting in the fact that image quality would be tremendously dropped and strong artifacts would appear. Thus, we try to tackle the issue of high-fidelity fine variable-rate image compression and propose the Invertible Activation Transformation (IAT) module. We implement the IAT in a mathematical invertible manner on a single rate Invertible Neural Network (INN) based model and the quality level (QLevel) would be fed into the IAT to generate scaling and bias tensors. IAT and QLevel together give the image compression model the ability of fine variable-rate control while better maintaining the image fidelity. Extensive experiments demonstrate that the single rate image compression model equipped with our IAT module has the ability to achieve variable-rate control without any compromise. And our IAT-embedded model obtains comparable rate-distortion performance with recent learning-based image compression methods. Furthermore, our method outperforms the state-of-the-art variable-rate image compression method by a large margin, especially after multiple re-encodings.