 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Attribute Disentanglement and Reinforcement for Lifelong Person Re-Identification
Mar 20, 2026Lifelong person re-identification (LReID) aims to learn from varying domains to obtain a unified person retrieval model. Existing LReID approaches typically focus on learning from scratch or a visual classification-pretrained model, while the Vision-Language Model (VLM) has shown generalizable knowledge in a variety of tasks. Although existing methods can be directly adapted to the VLM, since they only consider global-aware learning, the fine-grained attribute knowledge is underleveraged, leading to limited acquisition and anti-forgetting capacity. To address this problem, we introduce a novel VLM-driven LReID approach named Vision-Language Attribute Disentanglement and Reinforcement (VLADR). Our key idea is to explicitly model the universally shared human attributes to improve inter-domain knowledge transfer, thereby effectively utilizing historical knowledge to reinforce new knowledge learning and alleviate forgetting. Specifically, VLADR includes a Multi-grain Text Attribute Disentanglement mechanism that mines the global and diverse local text attributes of an image. Then, an Inter-domain Cross-modal Attribute Reinforcement scheme is developed, which introduces cross-modal attribute alignment to guide visual attribute extraction and adopts inter-domain attribute alignment to achieve fine-grained knowledge transfer. Experimental results demonstrate that our VLADR outperforms the state-of-the-art methods by 1.9\%-2.2\% and 2.1\%-2.5\% on anti-forgetting and generalization capacity. Our source code is available at https://github.com/zhoujiahuan1991/CVPR2026-VLADR
PETRA: Pretrained Evolutionary Transformer for SARS-CoV-2 Mutation Prediction
Nov 06, 2025Since its emergence, SARS-CoV-2 has demonstrated a rapid and unpredictable evolutionary trajectory, characterized by the continual emergence of immune-evasive variants. This poses persistent challenges to public health and vaccine development. While large-scale generative pre-trained transformers (GPTs) have revolutionized the modeling of sequential data, their direct applications to noisy viral genomic sequences are limited. In this paper, we introduce PETRA(Pretrained Evolutionary TRAnsformer), a novel transformer approach based on evolutionary trajectories derived from phylogenetic trees rather than raw RNA sequences. This method effectively mitigates sequencing noise and captures the hierarchical structure of viral evolution. With a weighted training framework to address substantial geographical and temporal imbalances in global sequence data, PETRA excels in predicting future SARS-CoV-2 mutations, achieving a weighted recall@1 of 9.45% for nucleotide mutations and 17.10\% for spike amino-acid mutations, compared to 0.49% and 6.64% respectively for the best baseline. PETRA also demonstrates its ability to aid in the real-time mutation prediction of major clades like 24F(XEC) and 25A(LP.8.1). The code is open sourced on https://github.com/xz-keg/PETra
Self-Reinforcing Prototype Evolution with Dual-Knowledge Cooperation for Semi-Supervised Lifelong Person Re-Identification
Jul 02, 2025Current lifelong person re-identification (LReID) methods predominantly rely on fully labeled data streams. However, in real-world scenarios where annotation resources are limited, a vast amount of unlabeled data coexists with scarce labeled samples, leading to the Semi-Supervised LReID (Semi-LReID) problem where LReID methods suffer severe performance degradation. Existing LReID methods, even when combined with semi-supervised strategies, suffer from limited long-term adaptation performance due to struggling with the noisy knowledge occurring during unlabeled data utilization. In this paper, we pioneer the investigation of Semi-LReID, introducing a novel Self-Reinforcing Prototype Evolution with Dual-Knowledge Cooperation framework (SPRED). Our key innovation lies in establishing a self-reinforcing cycle between dynamic prototype-guided pseudo-label generation and new-old knowledge collaborative purification to enhance the utilization of unlabeled data. Specifically, learnable identity prototypes are introduced to dynamically capture the identity distributions and generate high-quality pseudo-labels. Then, the dual-knowledge cooperation scheme integrates current model specialization and historical model generalization, refining noisy pseudo-labels. Through this cyclic design, reliable pseudo-labels are progressively mined to improve current-stage learning and ensure positive knowledge propagation over long-term learning. Experiments on the established Semi-LReID benchmarks show that our SPRED achieves state-of-the-art performance. Our source code is available at https://github.com/zhoujiahuan1991/ICCV2025-SPRED
GAPrompt: Geometry-Aware Point Cloud Prompt for 3D Vision Model
May 07, 2025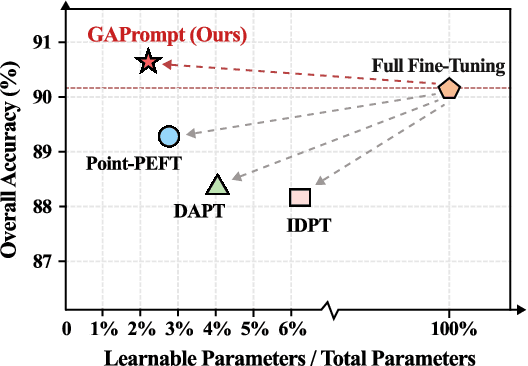
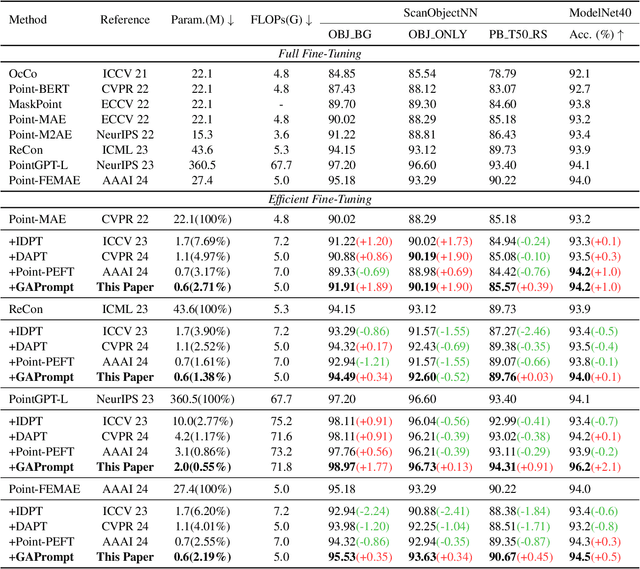
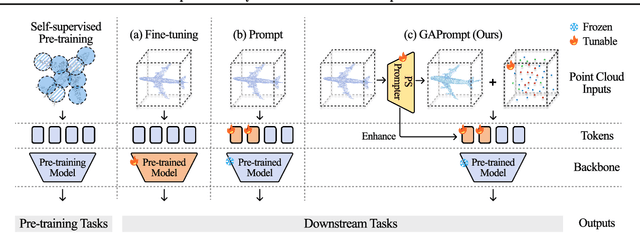
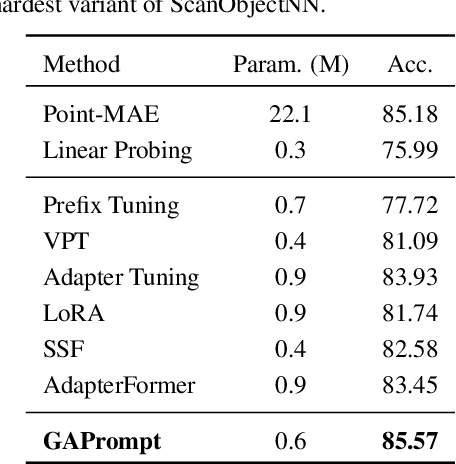
Pre-trained 3D vision models have gained significant attention for their promising performance on point cloud data. However, fully fine-tuning these models for downstream tasks is computationally expensive and storage-intensive. Existing parameter-efficient fine-tuning (PEFT) approaches, which focus primarily on input token prompting, struggle to achieve competitive performance due to their limited ability to capture the geometric information inherent in point clouds. To address this challenge, we propose a novel Geometry-Aware Point Cloud Prompt (GAPrompt) that leverages geometric cues to enhance the adaptability of 3D vision models. First, we introduce a Point Prompt that serves as an auxiliary input alongside the original point cloud, explicitly guiding the model to capture fine-grained geometric details. Additionally, we present a Point Shift Prompter designed to extract global shape information from the point cloud, enabling instance-specific geometric adjustments at the input level. Moreover, our proposed Prompt Propagation mechanism incorporates the shape information into the model's feature extraction process, further strengthening its ability to capture essential geometric characteristics. Extensive experiments demonstrate that GAPrompt significantly outperforms state-of-the-art PEFT methods and achieves competitive results compared to full fine-tuning on various benchmarks, while utilizing only 2.19% of trainable parameters. Our code is available at https://github.com/zhoujiahuan1991/ICML2025-VGP.
Componential Prompt-Knowledge Alignment for Domain Incremental Learning
May 07, 2025Domain Incremental Learning (DIL) aims to learn from non-stationary data streams across domains while retaining and utilizing past knowledge. Although prompt-based methods effectively store multi-domain knowledge in prompt parameters and obtain advanced performance through cross-domain prompt fusion, we reveal an intrinsic limitation: component-wise misalignment between domain-specific prompts leads to conflicting knowledge integration and degraded predictions. This arises from the random positioning of knowledge components within prompts, where irrelevant component fusion introduces interference.To address this, we propose Componential Prompt-Knowledge Alignment (KA-Prompt), a novel prompt-based DIL method that introduces component-aware prompt-knowledge alignment during training, significantly improving both the learning and inference capacity of the model. KA-Prompt operates in two phases: (1) Initial Componential Structure Configuring, where a set of old prompts containing knowledge relevant to the new domain are mined via greedy search, which is then exploited to initialize new prompts to achieve reusable knowledge transfer and establish intrinsic alignment between new and old prompts. (2) Online Alignment Preservation, which dynamically identifies the target old prompts and applies adaptive componential consistency constraints as new prompts evolve. Extensive experiments on DIL benchmarks demonstrate the effectiveness of our KA-Prompt. Our source code is available at https://github.com/zhoujiahuan1991/ICML2025-KA-Prompt
Token Coordinated Prompt Attention is Needed for Visual Prompting
May 05, 2025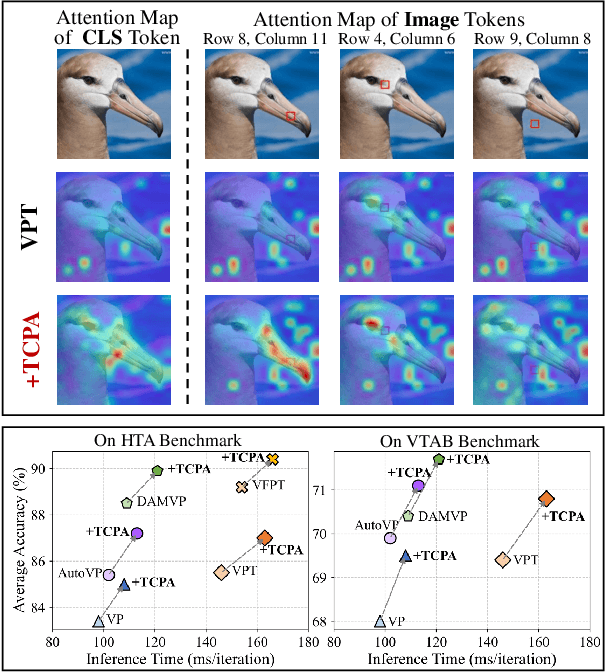
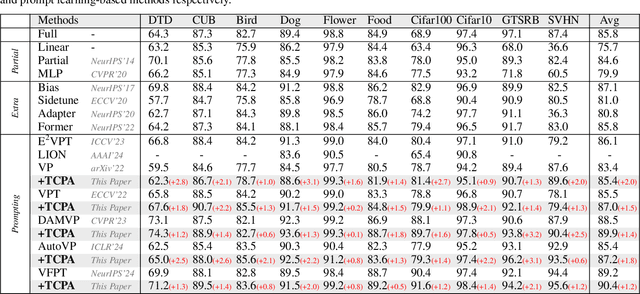
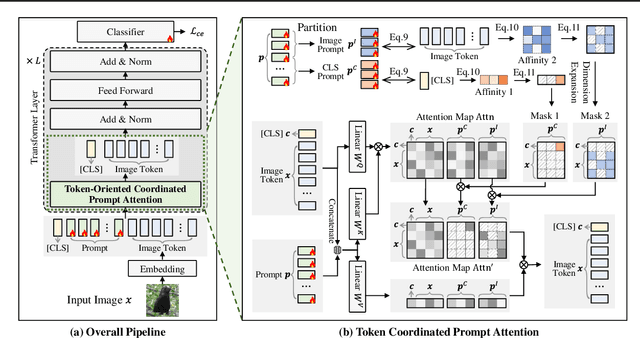
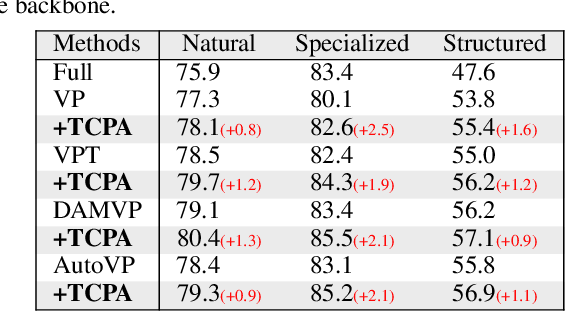
Visual prompting techniques are widely used to efficiently fine-tune pretrained Vision Transformers (ViT) by learning a small set of shared prompts for all tokens. However, existing methods overlook the unique roles of different tokens in conveying discriminative information and interact with all tokens using the same prompts, thereby limiting the representational capacity of ViT. This often leads to indistinguishable and biased prompt-extracted features, hindering performance. To address this issue, we propose a plug-and-play Token Coordinated Prompt Attention (TCPA) module, which assigns specific coordinated prompts to different tokens for attention-based interactions. Firstly, recognizing the distinct functions of CLS and image tokens-global information aggregation and local feature extraction, we disentangle the prompts into CLS Prompts and Image Prompts, which interact exclusively with CLS tokens and image tokens through attention mechanisms. This enhances their respective discriminative abilities. Furthermore, as different image tokens correspond to distinct image patches and contain diverse information, we employ a matching function to automatically assign coordinated prompts to individual tokens. This enables more precise attention interactions, improving the diversity and representational capacity of the extracted features. Extensive experiments across various benchmarks demonstrate that TCPA significantly enhances the diversity and discriminative power of the extracted features. The code is available at https://github.com/zhoujiahuan1991/ICML2025-TCPA.
Incremental Object Keypoint Learning
Mar 26, 2025Existing progress in object keypoint estimation primarily benefits from the conventional supervised learning paradigm based on numerous data labeled with pre-defined keypoints. However, these well-trained models can hardly detect the undefined new keypoints in test time, which largely hinders their feasibility for diverse downstream tasks. To handle this, various solutions are explored but still suffer from either limited generalizability or transferability. Therefore, in this paper, we explore a novel keypoint learning paradigm in that we only annotate new keypoints in the new data and incrementally train the model, without retaining any old data, called Incremental object Keypoint Learning (IKL). A two-stage learning scheme as a novel baseline tailored to IKL is developed. In the first Knowledge Association stage, given the data labeled with only new keypoints, an auxiliary KA-Net is trained to automatically associate the old keypoints to these new ones based on their spatial and intrinsic anatomical relations. In the second Mutual Promotion stage, based on a keypoint-oriented spatial distillation loss, we jointly leverage the auxiliary KA-Net and the old model for knowledge consolidation to mutually promote the estimation of all old and new keypoints. Owing to the investigation of the correlations between new and old keypoints, our proposed method can not just effectively mitigate the catastrophic forgetting of old keypoints, but may even further improve the estimation of the old ones and achieve a positive transfer beyond anti-forgetting. Such an observation has been solidly verified by extensive experiments on different keypoint datasets, where our method exhibits superiority in alleviating the forgetting issue and boosting performance while enjoying labeling efficiency even under the low-shot data regime.
Divide-and-Conquer: Dual-Hierarchical Optimization for Semantic 4D Gaussian Spatting
Mar 25, 2025Semantic 4D Gaussians can be used for reconstructing and understanding dynamic scenes, with temporal variations than static scenes. Directly applying static methods to understand dynamic scenes will fail to capture the temporal features. Few works focus on dynamic scene understanding based on Gaussian Splatting, since once the same update strategy is employed for both dynamic and static parts, regardless of the distinction and interaction between Gaussians, significant artifacts and noise appear. We propose Dual-Hierarchical Optimization (DHO), which consists of Hierarchical Gaussian Flow and Hierarchical Gaussian Guidance in a divide-and-conquer manner. The former implements effective division of static and dynamic rendering and features. The latter helps to mitigate the issue of dynamic foreground rendering distortion in textured complex scenes. Extensive experiments show that our method consistently outperforms the baselines on both synthetic and real-world datasets, and supports various downstream tasks. Project Page: https://sweety-yan.github.io/DHO.
STOP: Integrated Spatial-Temporal Dynamic Prompting for Video Understanding
Mar 20, 2025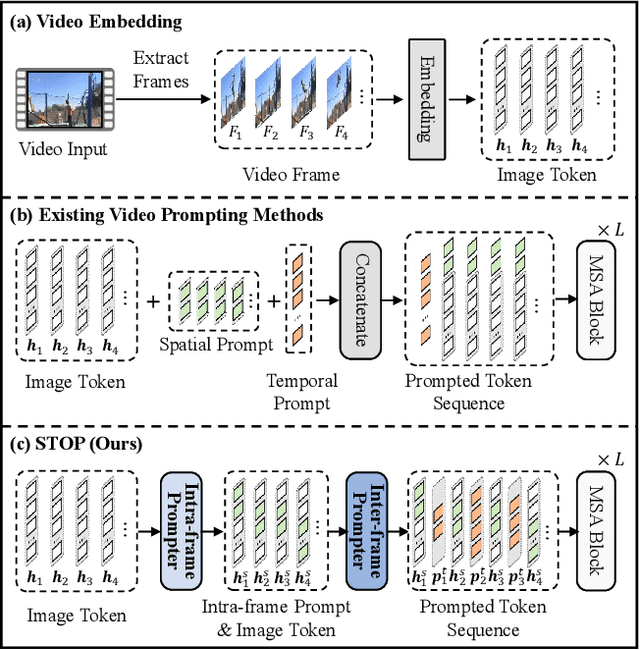
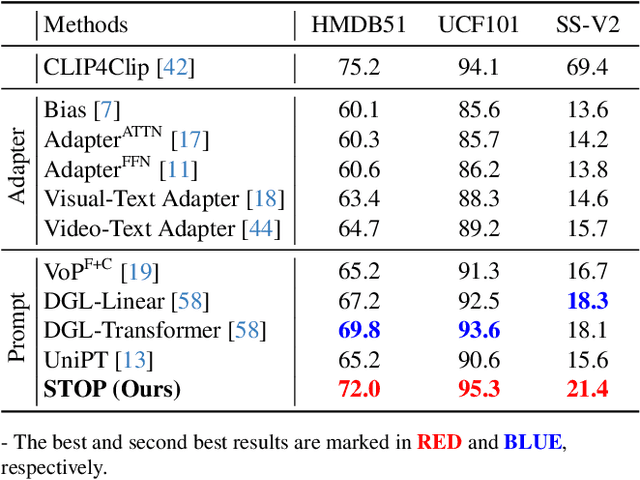
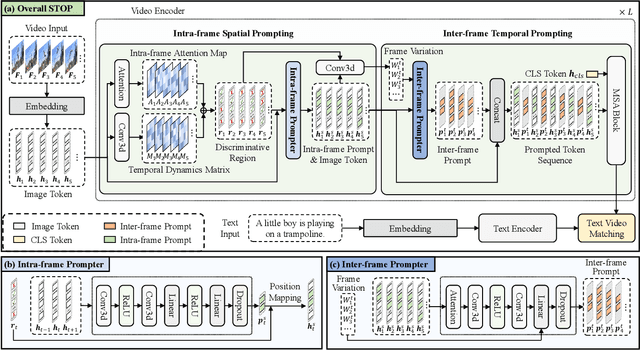
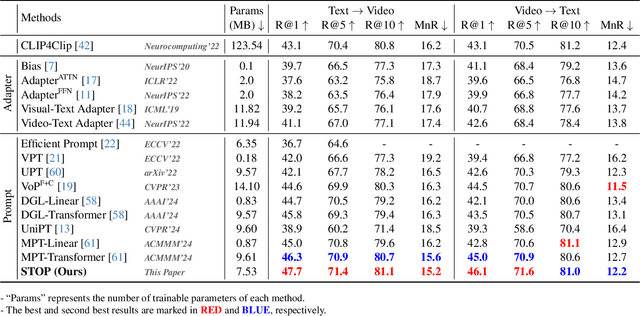
Pre-trained on tremendous image-text pairs, vision-language models like CLIP have demonstrated promising zero-shot generalization across numerous image-based tasks. However, extending these capabilities to video tasks remains challenging due to limited labeled video data and high training costs. Recent video prompting methods attempt to adapt CLIP for video tasks by introducing learnable prompts, but they typically rely on a single static prompt for all video sequences, overlooking the diverse temporal dynamics and spatial variations that exist across frames. This limitation significantly hinders the model's ability to capture essential temporal information for effective video understanding. To address this, we propose an integrated Spatial-TempOral dynamic Prompting (STOP) model which consists of two complementary modules, the intra-frame spatial prompting and inter-frame temporal prompting. Our intra-frame spatial prompts are designed to adaptively highlight discriminative regions within each frame by leveraging intra-frame attention and temporal variation, allowing the model to focus on areas with substantial temporal dynamics and capture fine-grained spatial details. Additionally, to highlight the varying importance of frames for video understanding, we further introduce inter-frame temporal prompts, dynamically inserting prompts between frames with high temporal variance as measured by frame similarity. This enables the model to prioritize key frames and enhances its capacity to understand temporal dependencies across sequences. Extensive experiments on various video benchmarks demonstrate that STOP consistently achieves superior performance against state-of-the-art methods. The code is available at https://github.com/zhoujiahuan1991/CVPR2025-STOP.
DriveEditor: A Unified 3D Information-Guided Framework for Controllable Object Editing in Driving Scenes
Dec 27, 2024
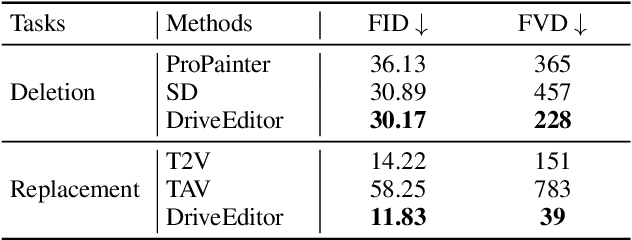
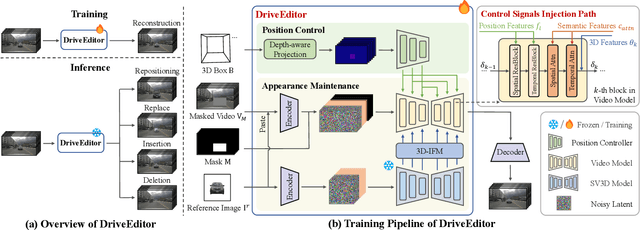
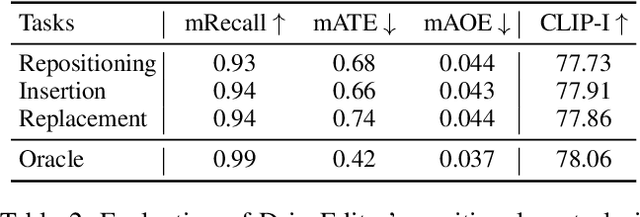
Vision-centric autonomous driving systems require diverse data for robust training and evaluation, which can be augmented by manipulating object positions and appearances within existing scene captures. While recent advancements in diffusion models have shown promise in video editing, their application to object manipulation in driving scenarios remains challenging due to imprecise positional control and difficulties in preserving high-fidelity object appearances. To address these challenges in position and appearance control, we introduce DriveEditor, a diffusion-based framework for object editing in driving videos. DriveEditor offers a unified framework for comprehensive object editing operations, including repositioning, replacement, deletion, and insertion. These diverse manipulations are all achieved through a shared set of varying inputs, processed by identical position control and appearance maintenance modules. The position control module projects the given 3D bounding box while preserving depth information and hierarchically injects it into the diffusion process, enabling precise control over object position and orientation. The appearance maintenance module preserves consistent attributes with a single reference image by employing a three-tiered approach: low-level detail preservation, high-level semantic maintenance, and the integration of 3D priors from a novel view synthesis model. Extensive qualitative and quantitative evaluations on the nuScenes dataset demonstrate DriveEditor's exceptional fidelity and controllability in generating diverse driving scene edits, as well as its remarkable ability to facilitate downstream tasks.