 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniVTG: A Large-Scale Dataset and Training Paradigm for Open-World Video Temporal Grounding
Apr 28, 2026Video Temporal Grounding (VTG), the task of localizing video segments from text queries, struggles in open-world settings due to limited dataset scale and semantic diversity, causing performance gaps between common and rare concepts. To overcome these limitations, we introduce OmniVTG, a new large-scale dataset for open-world VTG, coupled with a Self-Correction Chain-of-Thought (CoT) training paradigm designed to enhance the grounding capabilities of Multimodal Large Language Models (MLLMs). Our OmniVTG is constructed via a novel Semantic Coverage Iterative Expansion pipeline, which first identifies gaps in the vocabulary of existing datasets and collects videos that are highly likely to contain these target concepts. For high-quality annotation, we leverage the insight that modern MLLMs excel at dense captioning more than direct grounding and design a caption-centric data engine to prompt MLLMs to generate dense, timestamped descriptions. Beyond the dataset, we observe that simple supervised finetuning (SFT) is insufficient, as a performance gap between rare and common concepts still persists. We find that MLLMs' video understanding ability significantly surpasses their direct grounding ability. Based on this, we propose a Self-Correction Chain-of-Thought (CoT) training paradigm. We train the MLLM to first predict, then use its understanding capabilities to reflect on and refine its own predictions. This capability is instilled via a three-stage pipeline of SFT, CoT finetuning, and reinforcement learning. Extensive experiments show our approach not only excels at open-world grounding in our OmniVTG dataset but also achieves state-of-the-art zero-shot performance on four existing VTG benchmarks. Code is available at https://github.com/oceanflowlab/OmniVTG.
Taxonomy-Aware Representation Alignment for Hierarchical Visual Recognition with Large Multimodal Models
Feb 28, 2026A high-performing, general-purpose visual understanding model should map visual inputs to a taxonomic tree of labels, identify novel categories beyond the training set for which few or no publicly available images exist. Large Multimodal Models (LMMs) have achieved remarkable progress in fine-grained visual recognition (FGVR) for known categories. However, they remain limited in hierarchical visual recognition (HVR) that aims at predicting consistent label paths from coarse to fine categories, especially for novel categories. To tackle these challenges, we propose Taxonomy-Aware Representation Alignment (TARA), a simple yet effective strategy to inject taxonomic knowledge into LMMs. TARA leverages representations from biology foundation models (BFMs) that encode rich biological relationships through hierarchical contrastive learning. By aligning the intermediate representations of visual features with those of BFMs, LMMs are encouraged to extract discriminative visual cues well structured in the taxonomy tree. Additionally, we align the representations of the first answer token with the ground-truth label, flexibly bridging the gap between contextualized visual features and categories of varying granularity according to user intent. Experiments demonstrate that TARA consistently enhances LMMs' hierarchical consistency and leaf node accuracy, enabling reliable recognition of both known and novel categories within complex biological taxonomies. Code is available at https://github.com/PKU-ICST-MIPL/TARA_CVPR2026.
Venus: Benchmarking and Empowering Multimodal Large Language Models for Aesthetic Guidance and Cropping
Feb 27, 2026The widespread use of smartphones has made photography ubiquitous, yet a clear gap remains between ordinary users and professional photographers, who can identify aesthetic issues and provide actionable shooting guidance during capture. We define this capability as aesthetic guidance (AG) -- an essential but largely underexplored domain in computational aesthetics. Existing multimodal large language models (MLLMs) primarily offer overly positive feedback, failing to identify issues or provide actionable guidance. Without AG capability, they cannot effectively identify distracting regions or optimize compositional balance, thus also struggling in aesthetic cropping, which aims to refine photo composition through reframing after capture. To address this, we introduce AesGuide, the first large-scale AG dataset and benchmark with 10,748 photos annotated with aesthetic scores, analyses, and guidance. Building upon it, we propose Venus, a two-stage framework that first empowers MLLMs with AG capability through progressively complex aesthetic questions and then activates their aesthetic cropping power via CoT-based rationales. Extensive experiments show that Venus substantially improves AG capability and achieves state-of-the-art (SOTA) performance in aesthetic cropping, enabling interpretable and interactive aesthetic refinement across both stages of photo creation. Code is available at https://github.com/PKU-ICST-MIPL/Venus_CVPR2026.
TiFRe: Text-guided Video Frame Reduction for Efficient Video Multi-modal Large Language Models
Feb 09, 2026With the rapid development of Large Language Models (LLMs), Video Multi-Modal Large Language Models (Video MLLMs) have achieved remarkable performance in video-language tasks such as video understanding and question answering. However, Video MLLMs face high computational costs, particularly in processing numerous video frames as input, which leads to significant attention computation overhead. A straightforward approach to reduce computational costs is to decrease the number of input video frames. However, simply selecting key frames at a fixed frame rate (FPS) often overlooks valuable information in non-key frames, resulting in notable performance degradation. To address this, we propose Text-guided Video Frame Reduction (TiFRe), a framework that reduces input frames while preserving essential video information. TiFRe uses a Text-guided Frame Sampling (TFS) strategy to select key frames based on user input, which is processed by an LLM to generate a CLIP-style prompt. Pre-trained CLIP encoders calculate the semantic similarity between the prompt and each frame, selecting the most relevant frames as key frames. To preserve video semantics, TiFRe employs a Frame Matching and Merging (FMM) mechanism, which integrates non-key frame information into the selected key frames, minimizing information loss. Experiments show that TiFRe effectively reduces computational costs while improving performance on video-language tasks.
Fine-R1: Make Multi-modal LLMs Excel in Fine-Grained Visual Recognition by Chain-of-Thought Reasoning
Feb 07, 2026Any entity in the visual world can be hierarchically grouped based on shared characteristics and mapped to fine-grained sub-categories. While Multi-modal Large Language Models (MLLMs) achieve strong performance on coarse-grained visual tasks, they often struggle with Fine-Grained Visual Recognition (FGVR). Adapting general-purpose MLLMs to FGVR typically requires large amounts of annotated data, which is costly to obtain, leaving a substantial performance gap compared to contrastive CLIP models dedicated for discriminative tasks. Moreover, MLLMs tend to overfit to seen sub-categories and generalize poorly to unseen ones. To address these challenges, we propose Fine-R1, an MLLM tailored for FGVR through an R1-style training framework: (1) Chain-of-Thought Supervised Fine-tuning, where we construct a high-quality FGVR CoT dataset with rationales of "visual analysis, candidate sub-categories, comparison, and prediction", transition the model into a strong open-world classifier; and (2) Triplet Augmented Policy Optimization, where Intra-class Augmentation mixes trajectories from anchor and positive images within the same category to improve robustness to intra-class variance, while Inter-class Augmentation maximizes the response distinction conditioned on images across sub-categories to enhance discriminative ability. With only 4-shot training, Fine-R1 outperforms existing general MLLMs, reasoning MLLMs, and even contrastive CLIP models in identifying both seen and unseen sub-categories, showing promise in working in knowledge-intensive domains where gathering expert annotations for all sub-categories is arduous. Code is available at https://github.com/PKU-ICST-MIPL/FineR1_ICLR2026.
Multi-Resolution Alignment for Voxel Sparsity in Camera-Based 3D Semantic Scene Completion
Feb 03, 2026Camera-based 3D semantic scene completion (SSC) offers a cost-effective solution for assessing the geometric occupancy and semantic labels of each voxel in the surrounding 3D scene with image inputs, providing a voxel-level scene perception foundation for the perception-prediction-planning autonomous driving systems. Although significant progress has been made in existing methods, their optimization rely solely on the supervision from voxel labels and face the challenge of voxel sparsity as a large portion of voxels in autonomous driving scenarios are empty, which limits both optimization efficiency and model performance. To address this issue, we propose a \textit{Multi-Resolution Alignment (MRA)} approach to mitigate voxel sparsity in camera-based 3D semantic scene completion, which exploits the scene and instance level alignment across multi-resolution 3D features as auxiliary supervision. Specifically, we first propose the Multi-resolution View Transformer module, which projects 2D image features into multi-resolution 3D features and aligns them at the scene level through fusing discriminative seed features. Furthermore, we design the Cubic Semantic Anisotropy module to identify the instance-level semantic significance of each voxel, accounting for the semantic differences of a specific voxel against its neighboring voxels within a cubic area. Finally, we devise a Critical Distribution Alignment module, which selects critical voxels as instance-level anchors with the guidance of cubic semantic anisotropy, and applies a circulated loss for auxiliary supervision on the critical feature distribution consistency across different resolutions. The code is available at https://github.com/PKU-ICST-MIPL/MRA_TIP.
Bi-C2R: Bidirectional Continual Compatible Representation for Re-indexing Free Lifelong Person Re-identification
Dec 31, 2025Lifelong person Re-IDentification (L-ReID) exploits sequentially collected data to continuously train and update a ReID model, focusing on the overall performance of all data. Its main challenge is to avoid the catastrophic forgetting problem of old knowledge while training on new data. Existing L-ReID methods typically re-extract new features for all historical gallery images for inference after each update, known as "re-indexing". However, historical gallery data typically suffers from direct saving due to the data privacy issue and the high re-indexing costs for large-scale gallery images. As a result, it inevitably leads to incompatible retrieval between query features extracted by the updated model and gallery features extracted by those before the update, greatly impairing the re-identification performance. To tackle the above issue, this paper focuses on a new task called Re-index Free Lifelong person Re-IDentification (RFL-ReID), which requires performing lifelong person re-identification without re-indexing historical gallery images. Therefore, RFL-ReID is more challenging than L-ReID, requiring continuous learning and balancing new and old knowledge in diverse streaming data, and making the features output by the new and old models compatible with each other. To this end, we propose a Bidirectional Continuous Compatible Representation (Bi-C2R) framework to continuously update the gallery features extracted by the old model to perform efficient L-ReID in a compatible manner. We verify our proposed Bi-C2R method through theoretical analysis and extensive experiments on multiple benchmarks, which demonstrate that the proposed method can achieve leading performance on both the introduced RFL-ReID task and the traditional L-ReID task.
CKDA: Cross-modality Knowledge Disentanglement and Alignment for Visible-Infrared Lifelong Person Re-identification
Nov 19, 2025Lifelong person Re-IDentification (LReID) aims to match the same person employing continuously collected individual data from different scenarios. To achieve continuous all-day person matching across day and night, Visible-Infrared Lifelong person Re-IDentification (VI-LReID) focuses on sequential training on data from visible and infrared modalities and pursues average performance over all data. To this end, existing methods typically exploit cross-modal knowledge distillation to alleviate the catastrophic forgetting of old knowledge. However, these methods ignore the mutual interference of modality-specific knowledge acquisition and modality-common knowledge anti-forgetting, where conflicting knowledge leads to collaborative forgetting. To address the above problems, this paper proposes a Cross-modality Knowledge Disentanglement and Alignment method, called CKDA, which explicitly separates and preserves modality-specific knowledge and modality-common knowledge in a balanced way. Specifically, a Modality-Common Prompting (MCP) module and a Modality-Specific Prompting (MSP) module are proposed to explicitly disentangle and purify discriminative information that coexists and is specific to different modalities, avoiding the mutual interference between both knowledge. In addition, a Cross-modal Knowledge Alignment (CKA) module is designed to further align the disentangled new knowledge with the old one in two mutually independent inter- and intra-modality feature spaces based on dual-modality prototypes in a balanced manner. Extensive experiments on four benchmark datasets verify the effectiveness and superiority of our CKDA against state-of-the-art methods. The source code of this paper is available at https://github.com/PKU-ICST-MIPL/CKDA-AAAI2026.
HD$^2$-SSC: High-Dimension High-Density Semantic Scene Completion for Autonomous Driving
Nov 13, 2025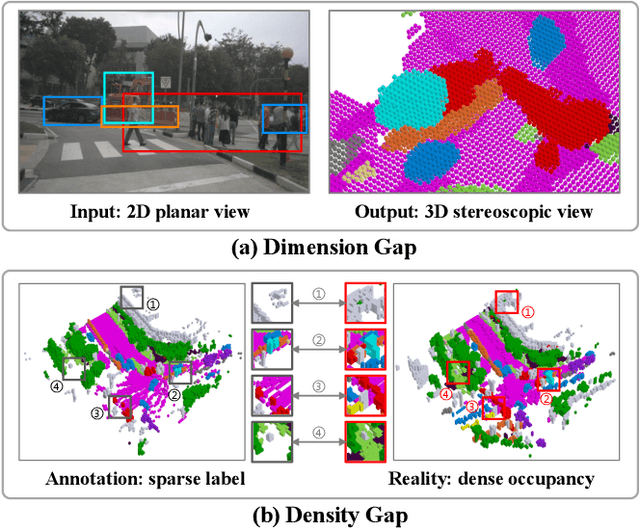
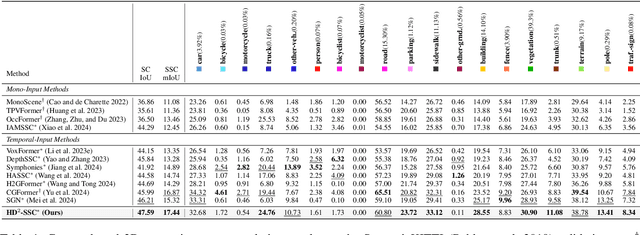
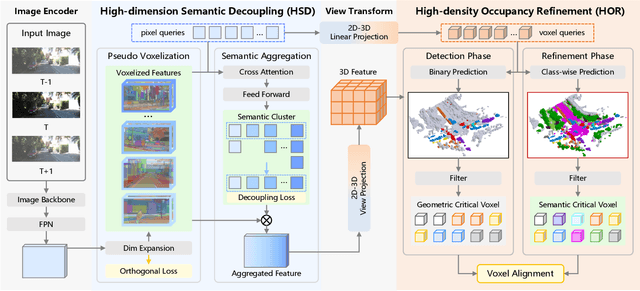
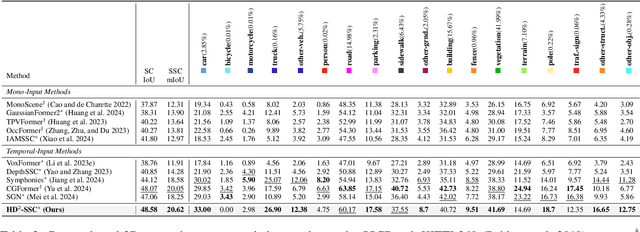
Camera-based 3D semantic scene completion (SSC) plays a crucial role in autonomous driving, enabling voxelized 3D scene understanding for effective scene perception and decision-making. Existing SSC methods have shown efficacy in improving 3D scene representations, but suffer from the inherent input-output dimension gap and annotation-reality density gap, where the 2D planner view from input images with sparse annotated labels leads to inferior prediction of real-world dense occupancy with a 3D stereoscopic view. In light of this, we propose the corresponding High-Dimension High-Density Semantic Scene Completion (HD$^2$-SSC) framework with expanded pixel semantics and refined voxel occupancies. To bridge the dimension gap, a High-dimension Semantic Decoupling module is designed to expand 2D image features along a pseudo third dimension, decoupling coarse pixel semantics from occlusions, and then identify focal regions with fine semantics to enrich image features. To mitigate the density gap, a High-density Occupancy Refinement module is devised with a "detect-and-refine" architecture to leverage contextual geometric and semantic structures for enhanced semantic density with the completion of missing voxels and correction of erroneous ones. Extensive experiments and analyses on the SemanticKITTI and SSCBench-KITTI-360 datasets validate the effectiveness of our HD$^2$-SSC framework.
Interact-Custom: Customized Human Object Interaction Image Generation
Aug 28, 2025Compositional Customized Image Generation aims to customize multiple target concepts within generation content, which has gained attention for its wild application. Existing approaches mainly concentrate on the target entity's appearance preservation, while neglecting the fine-grained interaction control among target entities. To enable the model of such interaction control capability, we focus on human object interaction scenario and propose the task of Customized Human Object Interaction Image Generation(CHOI), which simultaneously requires identity preservation for target human object and the interaction semantic control between them. Two primary challenges exist for CHOI:(1)simultaneous identity preservation and interaction control demands require the model to decompose the human object into self-contained identity features and pose-oriented interaction features, while the current HOI image datasets fail to provide ideal samples for such feature-decomposed learning.(2)inappropriate spatial configuration between human and object may lead to the lack of desired interaction semantics. To tackle it, we first process a large-scale dataset, where each sample encompasses the same pair of human object involving different interactive poses. Then we design a two-stage model Interact-Custom, which firstly explicitly models the spatial configuration by generating a foreground mask depicting the interaction behavior, then under the guidance of this mask, we generate the target human object interacting while preserving their identities features. Furthermore, if the background image and the union location of where the target human object should appear are provided by users, Interact-Custom also provides the optional functionality to specify them, offering high content controllability. Extensive experiments on our tailored metrics for CHOI task demonstrate the effectiveness of our approach.