 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREL-SF4PASS: Panoramic Semantic Segmentation with REL Depth Representation and Spherical Fusion
Jan 23, 2026As an important and challenging problem in computer vision, Panoramic Semantic Segmentation (PASS) aims to give complete scene perception based on an ultra-wide angle of view. Most PASS methods often focus on spherical geometry with RGB input or using the depth information in original or HHA format, which does not make full use of panoramic image geometry. To address these shortcomings, we propose REL-SF4PASS with our REL depth representation based on cylindrical coordinate and Spherical-dynamic Multi-Modal Fusion SMMF. REL is made up of Rectified Depth, Elevation-Gained Vertical Inclination Angle, and Lateral Orientation Angle, which fully represents 3D space in cylindrical coordinate style and the surface normal direction. SMMF aims to ensure the diversity of fusion for different panoramic image regions and reduce the breakage of cylinder side surface expansion in ERP projection, which uses different fusion strategies to match the different regions in panoramic images. Experimental results show that REL-SF4PASS considerably improves performance and robustness on popular benchmark, Stanford2D3D Panoramic datasets. It gains 2.35% average mIoU improvement on all 3 folds and reduces the performance variance by approximately 70% when facing 3D disturbance.
SphereDrag: Spherical Geometry-Aware Panoramic Image Editing
Jun 13, 2025Image editing has made great progress on planar images, but panoramic image editing remains underexplored. Due to their spherical geometry and projection distortions, panoramic images present three key challenges: boundary discontinuity, trajectory deformation, and uneven pixel density. To tackle these issues, we propose SphereDrag, a novel panoramic editing framework utilizing spherical geometry knowledge for accurate and controllable editing. Specifically, adaptive reprojection (AR) uses adaptive spherical rotation to deal with discontinuity; great-circle trajectory adjustment (GCTA) tracks the movement trajectory more accurate; spherical search region tracking (SSRT) adaptively scales the search range based on spherical location to address uneven pixel density. Also, we construct PanoBench, a panoramic editing benchmark, including complex editing tasks involving multiple objects and diverse styles, which provides a standardized evaluation framework. Experiments show that SphereDrag gains a considerable improvement compared with existing methods in geometric consistency and image quality, achieving up to 10.5% relative improvement.
Focusing Image Generation to Mitigate Spurious Correlations
Dec 27, 2024



Instance features in images exhibit spurious correlations with background features, affecting the training process of deep neural classifiers. This leads to insufficient attention to instance features by the classifier, resulting in erroneous classification outcomes. In this paper, we propose a data augmentation method called Spurious Correlations Guided Synthesis (SCGS) that mitigates spurious correlations through image generation model. This approach does not require expensive spurious attribute (group) labels for the training data and can be widely applied to other debiasing methods. Specifically, SCGS first identifies the incorrect attention regions of a pre-trained classifier on the training images, and then uses an image generation model to generate new training data based on these incorrect attended regions. SCGS increases the diversity and scale of the dataset to reduce the impact of spurious correlations on classifiers. Changes in the classifier's attention regions and experimental results on three different domain datasets demonstrate that this method is effective in reducing the classifier's reliance on spurious correlations.
CP-UNet: Contour-based Probabilistic Model for Medical Ultrasound Images Segmentation
Nov 21, 2024Deep learning-based segmentation methods are widely utilized for detecting lesions in ultrasound images. Throughout the imaging procedure, the attenuation and scattering of ultrasound waves cause contour blurring and the formation of artifacts, limiting the clarity of the acquired ultrasound images. To overcome this challenge, we propose a contour-based probabilistic segmentation model CP-UNet, which guides the segmentation network to enhance its focus on contour during decoding. We design a novel down-sampling module to enable the contour probability distribution modeling and encoding stages to acquire global-local features. Furthermore, the Gaussian Mixture Model utilizes optimized features to model the contour distribution, capturing the uncertainty of lesion boundaries. Extensive experiments with several state-of-the-art deep learning segmentation methods on three ultrasound image datasets show that our method performs better on breast and thyroid lesions segmentation.
Online Parallel Multi-Task Relationship Learning via Alternating Direction Method of Multipliers
Nov 09, 2024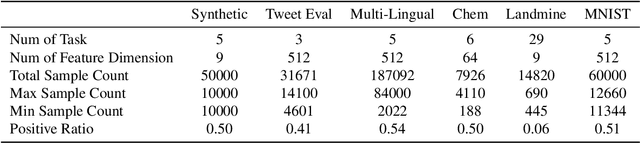
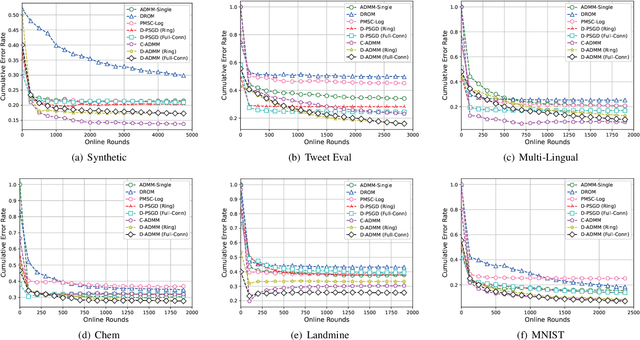
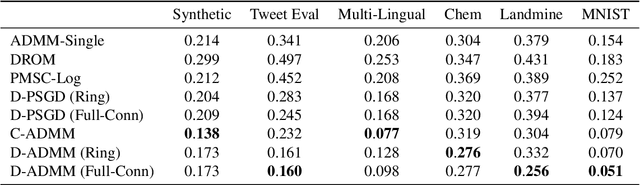
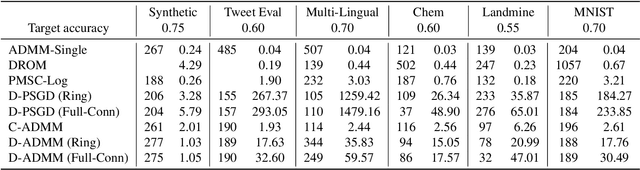
Online multi-task learning (OMTL) enhances streaming data processing by leveraging the inherent relations among multiple tasks. It can be described as an optimization problem in which a single loss function is defined for multiple tasks. Existing gradient-descent-based methods for this problem might suffer from gradient vanishing and poor conditioning issues. Furthermore, the centralized setting hinders their application to online parallel optimization, which is vital to big data analytics. Therefore, this study proposes a novel OMTL framework based on the alternating direction multiplier method (ADMM), a recent breakthrough in optimization suitable for the distributed computing environment because of its decomposable and easy-to-implement nature. The relations among multiple tasks are modeled dynamically to fit the constant changes in an online scenario. In a classical distributed computing architecture with a central server, the proposed OMTL algorithm with the ADMM optimizer outperforms SGD-based approaches in terms of accuracy and efficiency. Because the central server might become a bottleneck when the data scale grows, we further tailor the algorithm to a decentralized setting, so that each node can work by only exchanging information with local neighbors. Experimental results on a synthetic and several real-world datasets demonstrate the efficiency of our methods.
SphereDiffusion: Spherical Geometry-Aware Distortion Resilient Diffusion Model
Mar 15, 2024Controllable spherical panoramic image generation holds substantial applicative potential across a variety of domains.However, it remains a challenging task due to the inherent spherical distortion and geometry characteristics, resulting in low-quality content generation.In this paper, we introduce a novel framework of SphereDiffusion to address these unique challenges, for better generating high-quality and precisely controllable spherical panoramic images.For the spherical distortion characteristic, we embed the semantics of the distorted object with text encoding, then explicitly construct the relationship with text-object correspondence to better use the pre-trained knowledge of the planar images.Meanwhile, we employ a deformable technique to mitigate the semantic deviation in latent space caused by spherical distortion.For the spherical geometry characteristic, in virtue of spherical rotation invariance, we improve the data diversity and optimization objectives in the training process, enabling the model to better learn the spherical geometry characteristic.Furthermore, we enhance the denoising process of the diffusion model, enabling it to effectively use the learned geometric characteristic to ensure the boundary continuity of the generated images.With these specific techniques, experiments on Structured3D dataset show that SphereDiffusion significantly improves the quality of controllable spherical image generation and relatively reduces around 35% FID on average.
Windformer:Bi-Directional Long-Distance Spatio-Temporal Network For Wind Speed Prediction
Nov 24, 2023Wind speed prediction is critical to the management of wind power generation. Due to the large range of wind speed fluctuations and wake effect, there may also be strong correlations between long-distance wind turbines. This difficult-to-extract feature has become a bottleneck for improving accuracy. History and future time information includes the trend of airflow changes, whether this dynamic information can be utilized will also affect the prediction effect. In response to the above problems, this paper proposes Windformer. First, Windformer divides the wind turbine cluster into multiple non-overlapping windows and calculates correlations inside the windows, then shifts the windows partially to provide connectivity between windows, and finally fuses multi-channel features based on detailed and global information. To dynamically model the change process of wind speed, this paper extracts time series in both history and future directions simultaneously. Compared with other current-advanced methods, the Mean Square Error (MSE) of Windformer is reduced by 0.5\% to 15\% on two datasets from NERL.
Ultrasound Image Segmentation of Thyroid Nodule via Latent Semantic Feature Co-Registration
Oct 13, 2023Segmentation of nodules in thyroid ultrasound imaging plays a crucial role in the detection and treatment of thyroid cancer. However, owing to the diversity of scanner vendors and imaging protocols in different hospitals, the automatic segmentation model, which has already demonstrated expert-level accuracy in the field of medical image segmentation, finds its accuracy reduced as the result of its weak generalization performance when being applied in clinically realistic environments. To address this issue, the present paper proposes ASTN, a framework for thyroid nodule segmentation achieved through a new type co-registration network. By extracting latent semantic information from the atlas and target images and utilizing in-depth features to accomplish the co-registration of nodules in thyroid ultrasound images, this framework can ensure the integrity of anatomical structure and reduce the impact on segmentation as the result of overall differences in image caused by different devices. In addition, this paper also provides an atlas selection algorithm to mitigate the difficulty of co-registration. As shown by the evaluation results collected from the datasets of different devices, thanks to the method we proposed, the model generalization has been greatly improved while maintaining a high level of segmentation accuracy.
Bridging Cross-task Protocol Inconsistency for Distillation in Dense Object Detection
Aug 28, 2023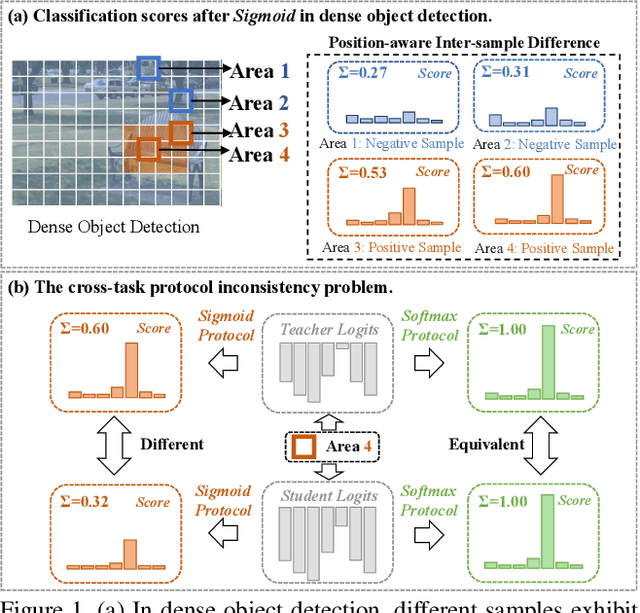
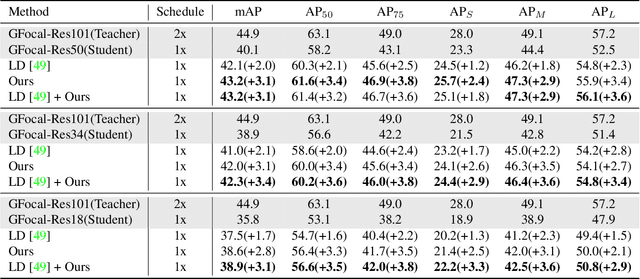
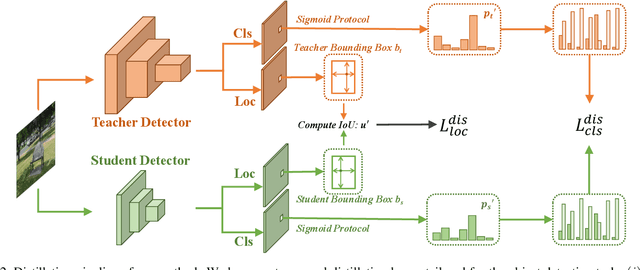
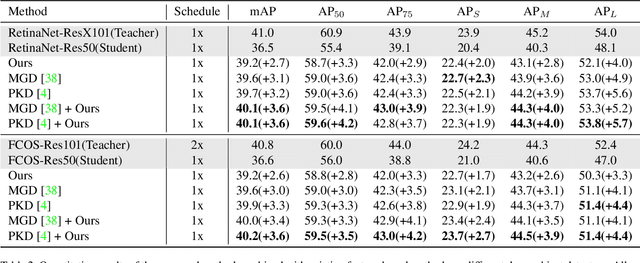
Knowledge distillation (KD) has shown potential for learning compact models in dense object detection. However, the commonly used softmax-based distillation ignores the absolute classification scores for individual categories. Thus, the optimum of the distillation loss does not necessarily lead to the optimal student classification scores for dense object detectors. This cross-task protocol inconsistency is critical, especially for dense object detectors, since the foreground categories are extremely imbalanced. To address the issue of protocol differences between distillation and classification, we propose a novel distillation method with cross-task consistent protocols, tailored for the dense object detection. For classification distillation, we address the cross-task protocol inconsistency problem by formulating the classification logit maps in both teacher and student models as multiple binary-classification maps and applying a binary-classification distillation loss to each map. For localization distillation, we design an IoU-based Localization Distillation Loss that is free from specific network structures and can be compared with existing localization distillation losses. Our proposed method is simple but effective, and experimental results demonstrate its superiority over existing methods. Code is available at https://github.com/TinyTigerPan/BCKD.
SGAT4PASS: Spherical Geometry-Aware Transformer for PAnoramic Semantic Segmentation
Jun 06, 2023As an important and challenging problem in computer vision, PAnoramic Semantic Segmentation (PASS) gives complete scene perception based on an ultra-wide angle of view. Usually, prevalent PASS methods with 2D panoramic image input focus on solving image distortions but lack consideration of the 3D properties of original $360^{\circ}$ data. Therefore, their performance will drop a lot when inputting panoramic images with the 3D disturbance. To be more robust to 3D disturbance, we propose our Spherical Geometry-Aware Transformer for PAnoramic Semantic Segmentation (SGAT4PASS), considering 3D spherical geometry knowledge. Specifically, a spherical geometry-aware framework is proposed for PASS. It includes three modules, i.e., spherical geometry-aware image projection, spherical deformable patch embedding, and a panorama-aware loss, which takes input images with 3D disturbance into account, adds a spherical geometry-aware constraint on the existing deformable patch embedding, and indicates the pixel density of original $360^{\circ}$ data, respectively. Experimental results on Stanford2D3D Panoramic datasets show that SGAT4PASS significantly improves performance and robustness, with approximately a 2% increase in mIoU, and when small 3D disturbances occur in the data, the stability of our performance is improved by an order of magnitude. Our code and supplementary material are available at https://github.com/TencentARC/SGAT4PASS.