 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Context Augmented Multi-Play Multi-Armed Bandit Algorithm for Fast Channel Allocation in Opportunistic Spectrum Access
May 25, 2026We study the restless contextual multi-play multi-armed bandit (MP-MAB) problem for channel allocation in the opportunity spectrum access (OSA) scenario. Most existing MP-MAB methods are impractical for real-world OSA systems as they assume many ideal conditions, incur a heavy computational cost, and most importantly, ignore the impact of channel noise which is directly related to the quality of service. In this study, we embody this impact by modeling channel noise as a perturbation of the arm's reward function in MP-MAB. As there is an implicit correlation between channel state information and channel noise, we take the former as a context for MP-MAB to present the perturbation caused by the latter. We investigate two types of correlation between the context and the perturbation -- linear and nonlinear, and derive two index policies, respectively. These policies learn the correlations through a linear model and a neural network, and use estimated noise value to adjust the upper confidence bound. Numerical experiments demonstrate that the proposed policies can achieve lower regret and select sub-optimal arms in a more reasonable way.
Sharpness-aware Federated Graph Learning
Dec 18, 2025
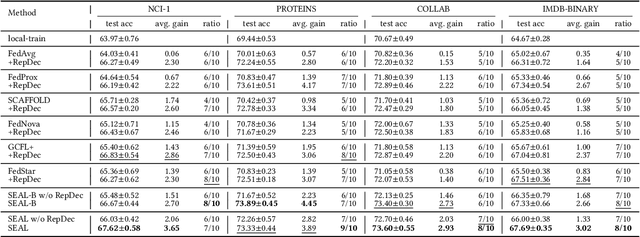
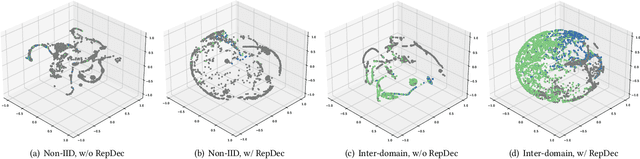
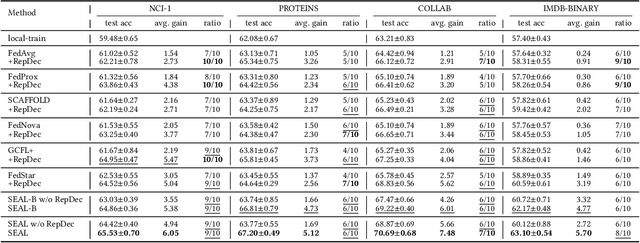
One of many impediments to applying graph neural networks (GNNs) to large-scale real-world graph data is the challenge of centralized training, which requires aggregating data from different organizations, raising privacy concerns. Federated graph learning (FGL) addresses this by enabling collaborative GNN model training without sharing private data. However, a core challenge in FGL systems is the variation in local training data distributions among clients, known as the data heterogeneity problem. Most existing solutions suffer from two problems: (1) The typical optimizer based on empirical risk minimization tends to cause local models to fall into sharp valleys and weakens their generalization to out-of-distribution graph data. (2) The prevalent dimensional collapse in the learned representations of local graph data has an adverse impact on the classification capacity of the GNN model. To this end, we formulate a novel optimization objective that is aware of the sharpness (i.e., the curvature of the loss surface) of local GNN models. By minimizing the loss function and its sharpness simultaneously, we seek out model parameters in a flat region with uniformly low loss values, thus improving the generalization over heterogeneous data. By introducing a regularizer based on the correlation matrix of local representations, we relax the correlations of representations generated by individual local graph samples, so as to alleviate the dimensional collapse of the learned model. The proposed \textbf{S}harpness-aware f\textbf{E}derated gr\textbf{A}ph \textbf{L}earning (SEAL) algorithm can enhance the classification accuracy and generalization ability of local GNN models in federated graph learning. Experimental studies on several graph classification benchmarks show that SEAL consistently outperforms SOTA FGL baselines and provides gains for more participants.
Automatic Image Colorization with Convolutional Neural Networks and Generative Adversarial Networks
Aug 07, 2025



Image colorization, the task of adding colors to grayscale images, has been the focus of significant research efforts in computer vision in recent years for its various application areas such as color restoration and automatic animation colorization [15, 1]. The colorization problem is challenging as it is highly ill-posed with two out of three image dimensions lost, resulting in large degrees of freedom. However, semantics of the scene as well as the surface texture could provide important cues for colors: the sky is typically blue, the clouds are typically white and the grass is typically green, and there are huge amounts of training data available for learning such priors since any colored image could serve as a training data point [20]. Colorization is initially formulated as a regression task[5], which ignores the multi-modal nature of color prediction. In this project, we explore automatic image colorization via classification and adversarial learning. We will build our models on prior works, apply modifications for our specific scenario and make comparisons.
Online Parallel Multi-Task Relationship Learning via Alternating Direction Method of Multipliers
Nov 09, 2024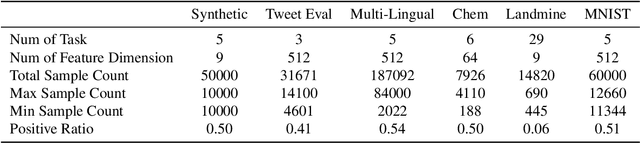
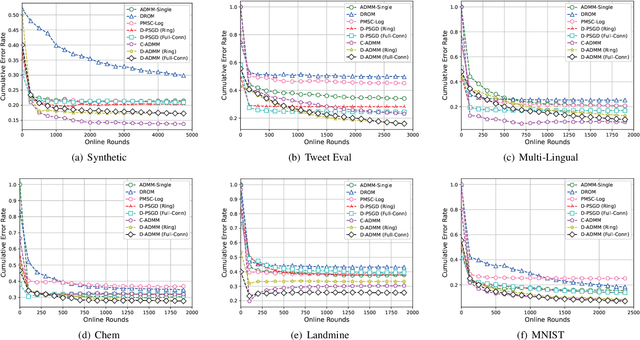
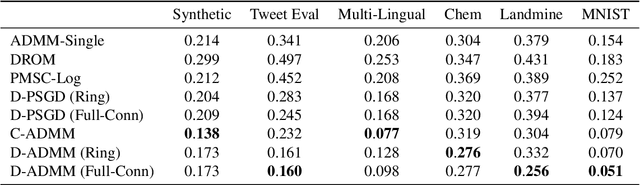
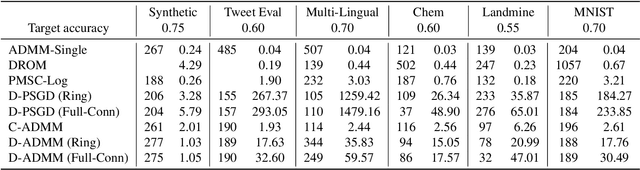
Online multi-task learning (OMTL) enhances streaming data processing by leveraging the inherent relations among multiple tasks. It can be described as an optimization problem in which a single loss function is defined for multiple tasks. Existing gradient-descent-based methods for this problem might suffer from gradient vanishing and poor conditioning issues. Furthermore, the centralized setting hinders their application to online parallel optimization, which is vital to big data analytics. Therefore, this study proposes a novel OMTL framework based on the alternating direction multiplier method (ADMM), a recent breakthrough in optimization suitable for the distributed computing environment because of its decomposable and easy-to-implement nature. The relations among multiple tasks are modeled dynamically to fit the constant changes in an online scenario. In a classical distributed computing architecture with a central server, the proposed OMTL algorithm with the ADMM optimizer outperforms SGD-based approaches in terms of accuracy and efficiency. Because the central server might become a bottleneck when the data scale grows, we further tailor the algorithm to a decentralized setting, so that each node can work by only exchanging information with local neighbors. Experimental results on a synthetic and several real-world datasets demonstrate the efficiency of our methods.
CCUP: A Controllable Synthetic Data Generation Pipeline for Pretraining Cloth-Changing Person Re-Identification Models
Oct 17, 2024
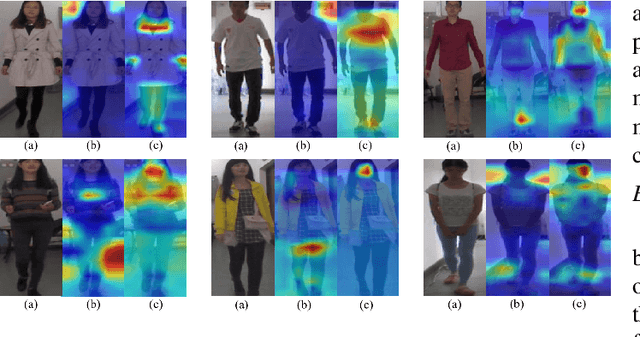
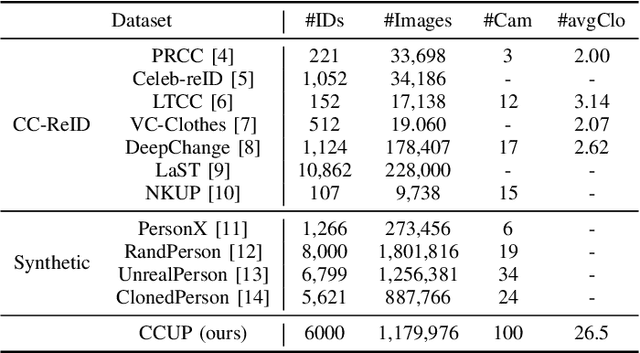
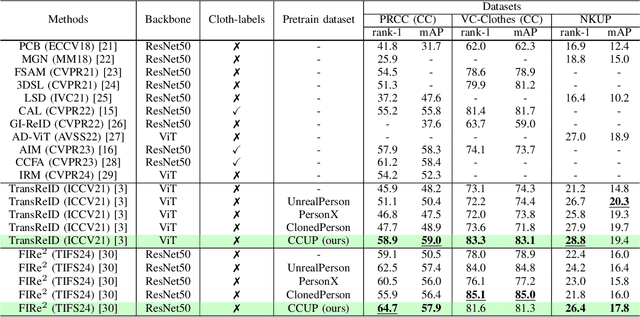
Cloth-changing person re-identification (CC-ReID), also known as Long-Term Person Re-Identification (LT-ReID) is a critical and challenging research topic in computer vision that has recently garnered significant attention. However, due to the high cost of constructing CC-ReID data, the existing data-driven models are hard to train efficiently on limited data, causing overfitting issue. To address this challenge, we propose a low-cost and efficient pipeline for generating controllable and high-quality synthetic data simulating the surveillance of real scenarios specific to the CC-ReID task. Particularly, we construct a new self-annotated CC-ReID dataset named Cloth-Changing Unreal Person (CCUP), containing 6,000 IDs, 1,179,976 images, 100 cameras, and 26.5 outfits per individual. Based on this large-scale dataset, we introduce an effective and scalable pretrain-finetune framework for enhancing the generalization capabilities of the traditional CC-ReID models. The extensive experiments demonstrate that two typical models namely TransReID and FIRe^2, when integrated into our framework, outperform other state-of-the-art models after pretraining on CCUP and finetuning on the benchmarks such as PRCC, VC-Clothes and NKUP. The CCUP is available at: https://github.com/yjzhao1019/CCUP.
Explainable Action Advising for Multi-Agent Reinforcement Learning
Nov 15, 2022



Action advising is a knowledge transfer technique for reinforcement learning based on the teacher-student paradigm. An expert teacher provides advice to a student during training in order to improve the student's sample efficiency and policy performance. Such advice is commonly given in the form of state-action pairs. However, it makes it difficult for the student to reason with and apply to novel states. We introduce Explainable Action Advising, in which the teacher provides action advice as well as associated explanations indicating why the action was chosen. This allows the student to self-reflect on what it has learned, enabling advice generalization and leading to improved sample efficiency and learning performance - even in environments where the teacher is sub-optimal. We empirically show that our framework is effective in both single-agent and multi-agent scenarios, yielding improved policy returns and convergence rates when compared to state-of-the-art methods.
Convolutional Neural Network Dynamics: A Graph Perspective
Nov 09, 2021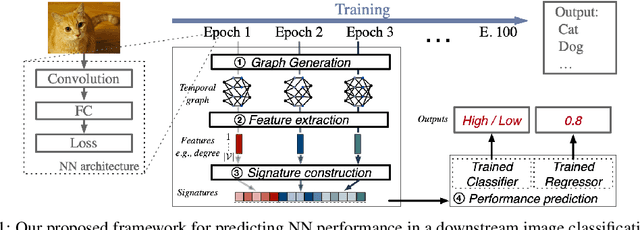

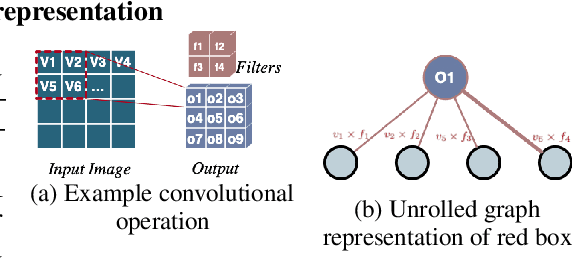
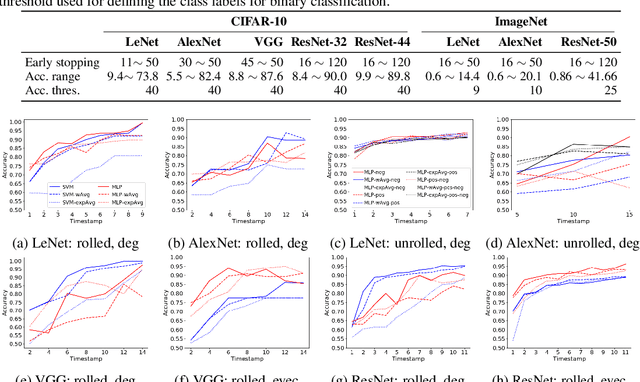
The success of neural networks (NNs) in a wide range of applications has led to increased interest in understanding the underlying learning dynamics of these models. In this paper, we go beyond mere descriptions of the learning dynamics by taking a graph perspective and investigating the relationship between the graph structure of NNs and their performance. Specifically, we propose (1) representing the neural network learning process as a time-evolving graph (i.e., a series of static graph snapshots over epochs), (2) capturing the structural changes of the NN during the training phase in a simple temporal summary, and (3) leveraging the structural summary to predict the accuracy of the underlying NN in a classification or regression task. For the dynamic graph representation of NNs, we explore structural representations for fully-connected and convolutional layers, which are key components of powerful NN models. Our analysis shows that a simple summary of graph statistics, such as weighted degree and eigenvector centrality, over just a few epochs can be used to accurately predict the performance of NNs. For example, a weighted degree-based summary of the time-evolving graph that is constructed based on 5 training epochs of the LeNet architecture achieves classification accuracy of over 93%. Our findings are consistent for different NN architectures, including LeNet, VGG, AlexNet and ResNet.
Prior Guided Feature Enrichment Network for Few-Shot Segmentation
Aug 04, 2020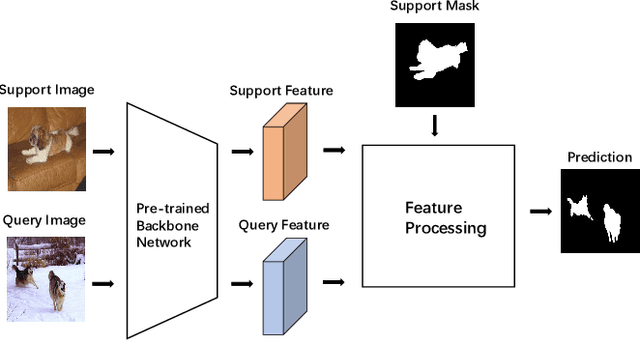
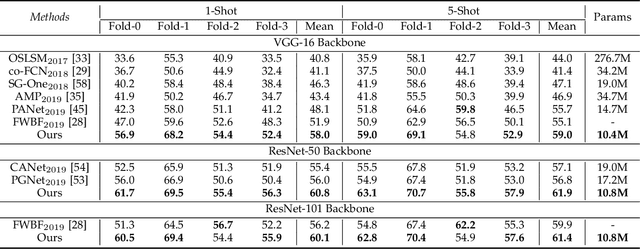

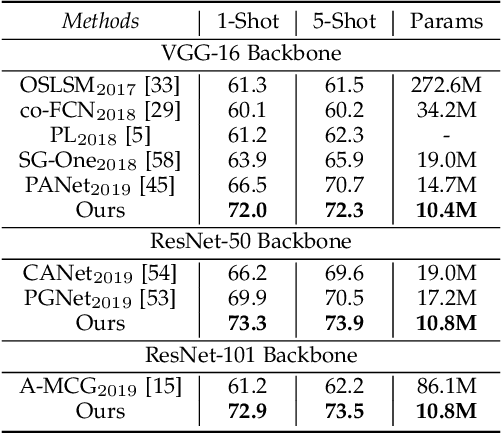
State-of-the-art semantic segmentation methods require sufficient labeled data to achieve good results and hardly work on unseen classes without fine-tuning. Few-shot segmentation is thus proposed to tackle this problem by learning a model that quickly adapts to new classes with a few labeled support samples. Theses frameworks still face the challenge of generalization ability reduction on unseen classes due to inappropriate use of high-level semantic information of training classes and spatial inconsistency between query and support targets. To alleviate these issues, we propose the Prior Guided Feature Enrichment Network (PFENet). It consists of novel designs of (1) a training-free prior mask generation method that not only retains generalization power but also improves model performance and (2) Feature Enrichment Module (FEM) that overcomes spatial inconsistency by adaptively enriching query features with support features and prior masks. Extensive experiments on PASCAL-5$^i$ and COCO prove that the proposed prior generation method and FEM both improve the baseline method significantly. Our PFENet also outperforms state-of-the-art methods by a large margin without efficiency loss. It is surprising that our model even generalizes to cases without labeled support samples. Our code is available at https://github.com/Jia-Research-Lab/PFENet/.
Tensor Low-Rank Reconstruction for Semantic Segmentation
Aug 02, 2020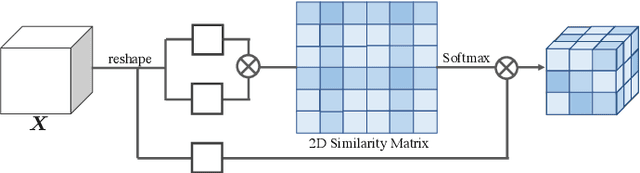
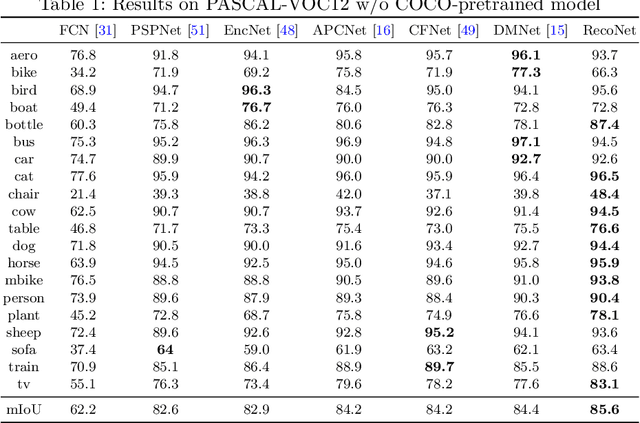
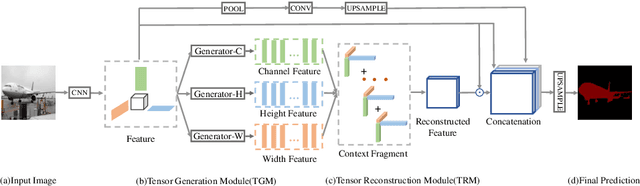
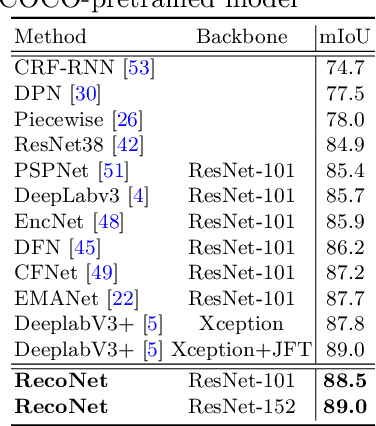
Context information plays an indispensable role in the success of semantic segmentation. Recently, non-local self-attention based methods are proved to be effective for context information collection. Since the desired context consists of spatial-wise and channel-wise attentions, 3D representation is an appropriate formulation. However, these non-local methods describe 3D context information based on a 2D similarity matrix, where space compression may lead to channel-wise attention missing. An alternative is to model the contextual information directly without compression. However, this effort confronts a fundamental difficulty, namely the high-rank property of context information. In this paper, we propose a new approach to model the 3D context representations, which not only avoids the space compression but also tackles the high-rank difficulty. Here, inspired by tensor canonical-polyadic decomposition theory (i.e, a high-rank tensor can be expressed as a combination of rank-1 tensors.), we design a low-rank-to-high-rank context reconstruction framework (i.e, RecoNet). Specifically, we first introduce the tensor generation module (TGM), which generates a number of rank-1 tensors to capture fragments of context feature. Then we use these rank-1 tensors to recover the high-rank context features through our proposed tensor reconstruction module (TRM). Extensive experiments show that our method achieves state-of-the-art on various public datasets. Additionally, our proposed method has more than 100 times less computational cost compared with conventional non-local-based methods.
An Adversarial Perturbation Oriented Domain Adaptation Approach for Semantic Segmentation
Dec 18, 2019
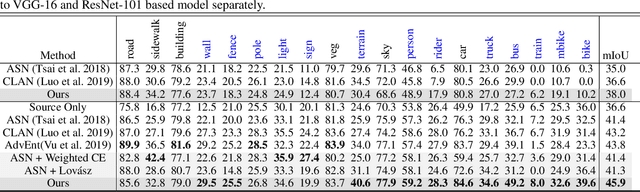
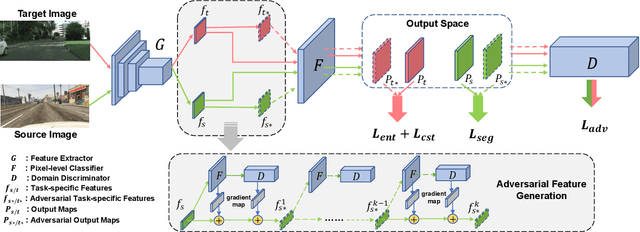
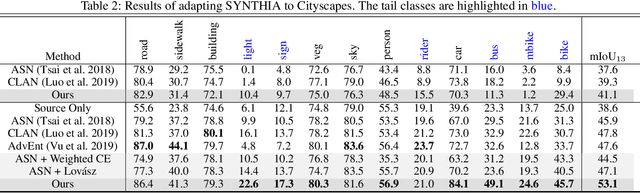
We focus on Unsupervised Domain Adaptation (UDA) for the task of semantic segmentation. Recently, adversarial alignment has been widely adopted to match the marginal distribution of feature representations across two domains globally. However, this strategy fails in adapting the representations of the tail classes or small objects for semantic segmentation since the alignment objective is dominated by head categories or large objects. In contrast to adversarial alignment, we propose to explicitly train a domain-invariant classifier by generating and defensing against pointwise feature space adversarial perturbations. Specifically, we firstly perturb the intermediate feature maps with several attack objectives (i.e., discriminator and classifier) on each individual position for both domains, and then the classifier is trained to be invariant to the perturbations. By perturbing each position individually, our model treats each location evenly regardless of the category or object size and thus circumvents the aforementioned issue. Moreover, the domain gap in feature space is reduced by extrapolating source and target perturbed features towards each other with attack on the domain discriminator. Our approach achieves the state-of-the-art performance on two challenging domain adaptation tasks for semantic segmentation: GTA5 -> Cityscapes and SYNTHIA -> Cityscapes.