 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamWalk: Style Space Exploration using Diffusion Guidance
Apr 04, 2024Text-conditioned diffusion models can generate impressive images, but fall short when it comes to fine-grained control. Unlike direct-editing tools like Photoshop, text conditioned models require the artist to perform "prompt engineering," constructing special text sentences to control the style or amount of a particular subject present in the output image. Our goal is to provide fine-grained control over the style and substance specified by the prompt, for example to adjust the intensity of styles in different regions of the image (Figure 1). Our approach is to decompose the text prompt into conceptual elements, and apply a separate guidance term for each element in a single diffusion process. We introduce guidance scale functions to control when in the diffusion process and \emph{where} in the image to intervene. Since the method is based solely on adjusting diffusion guidance, it does not require fine-tuning or manipulating the internal layers of the diffusion model's neural network, and can be used in conjunction with LoRA- or DreamBooth-trained models (Figure2). Project page: https://mshu1.github.io/dreamwalk.github.io/
Deep survival analysis with longitudinal X-rays for COVID-19
Aug 22, 2021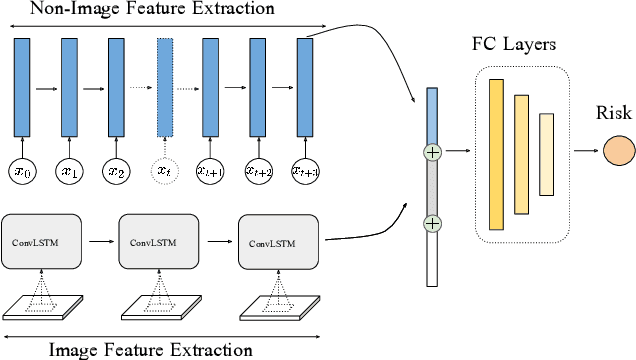
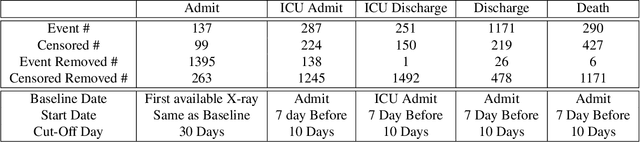
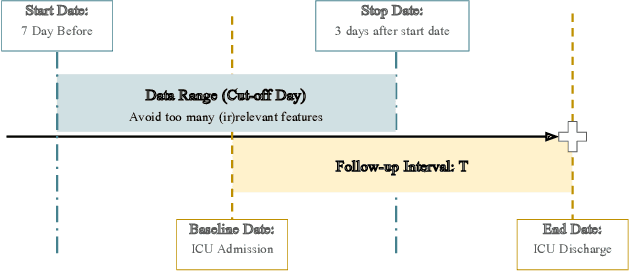
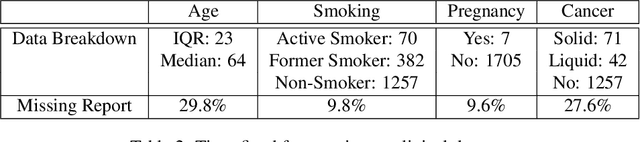
Time-to-event analysis is an important statistical tool for allocating clinical resources such as ICU beds. However, classical techniques like the Cox model cannot directly incorporate images due to their high dimensionality. We propose a deep learning approach that naturally incorporates multiple, time-dependent imaging studies as well as non-imaging data into time-to-event analysis. Our techniques are benchmarked on a clinical dataset of 1,894 COVID-19 patients, and show that image sequences significantly improve predictions. For example, classical time-to-event methods produce a concordance error of around 30-40% for predicting hospital admission, while our error is 25% without images and 20% with multiple X-rays included. Ablation studies suggest that our models are not learning spurious features such as scanner artifacts. While our focus and evaluation is on COVID-19, the methods we develop are broadly applicable.
Generalized Few-Shot Semantic Segmentation
Oct 11, 2020
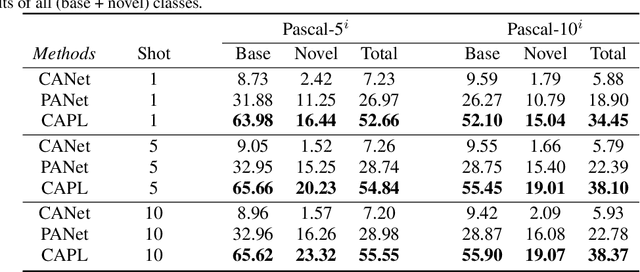
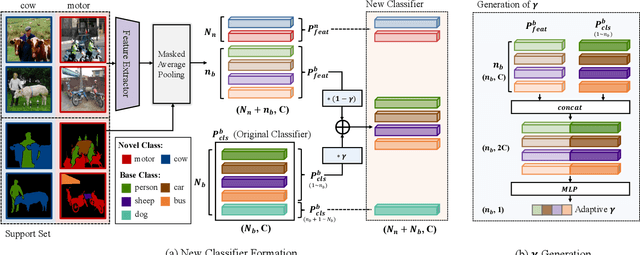

Training semantic segmentation models requires a large amount of finely annotated data, making it hard to quickly adapt to novel classes not satisfying this condition. Few-Shot Segmentation (FS-Seg) tackles this problem with many constraints. In this paper, we introduce a new benchmark, called Generalized Few-Shot Semantic Segmentation (GFS-Seg), to analyze the generalization ability of segmentation models to simultaneously recognize novel categories with very few examples as well as base categories with sufficient examples. Previous state-of-the-art FS-Seg methods fall short in GFS-Seg and the performance discrepancy mainly comes from the constrained training setting of FS-Seg. To make GFS-Seg tractable, we set up a GFS-Seg baseline that achieves decent performance without structural change on the original model. Then, as context is the key for boosting performance on semantic segmentation, we propose the Context-Aware Prototype Learning (CAPL) that significantly improves performance by leveraging the contextual information to update class prototypes with aligned features. Extensive experiments on Pascal-VOC and COCO manifest the effectiveness of CAPL, and CAPL also generalizes well to FS-Seg.
Prior Guided Feature Enrichment Network for Few-Shot Segmentation
Aug 04, 2020
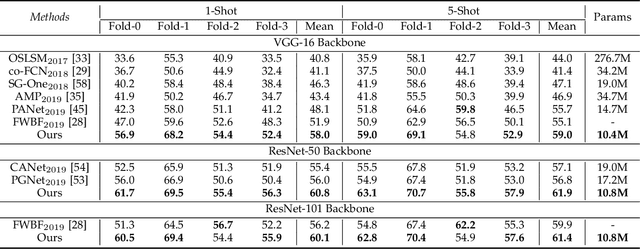

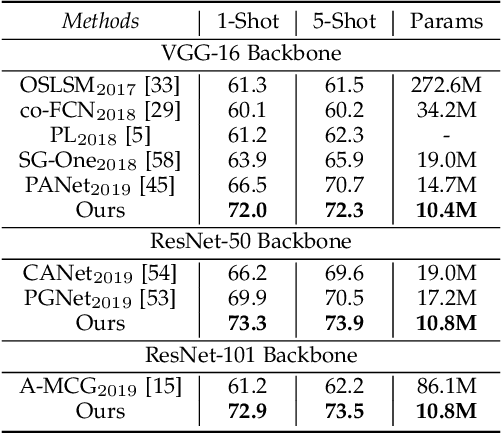
State-of-the-art semantic segmentation methods require sufficient labeled data to achieve good results and hardly work on unseen classes without fine-tuning. Few-shot segmentation is thus proposed to tackle this problem by learning a model that quickly adapts to new classes with a few labeled support samples. Theses frameworks still face the challenge of generalization ability reduction on unseen classes due to inappropriate use of high-level semantic information of training classes and spatial inconsistency between query and support targets. To alleviate these issues, we propose the Prior Guided Feature Enrichment Network (PFENet). It consists of novel designs of (1) a training-free prior mask generation method that not only retains generalization power but also improves model performance and (2) Feature Enrichment Module (FEM) that overcomes spatial inconsistency by adaptively enriching query features with support features and prior masks. Extensive experiments on PASCAL-5$^i$ and COCO prove that the proposed prior generation method and FEM both improve the baseline method significantly. Our PFENet also outperforms state-of-the-art methods by a large margin without efficiency loss. It is surprising that our model even generalizes to cases without labeled support samples. Our code is available at https://github.com/Jia-Research-Lab/PFENet/.
Understanding Human Hands in Contact at Internet Scale
Jun 11, 2020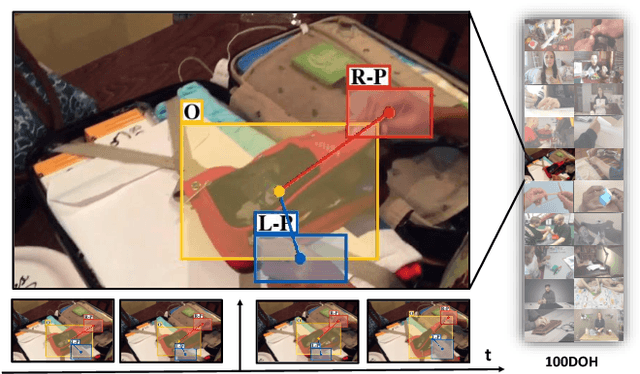
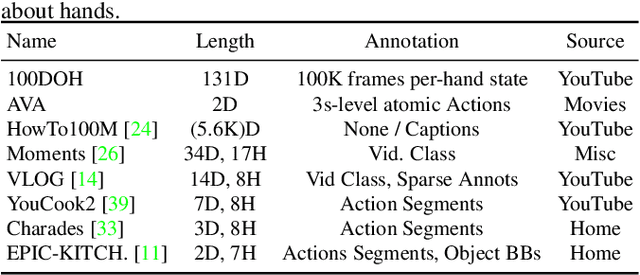
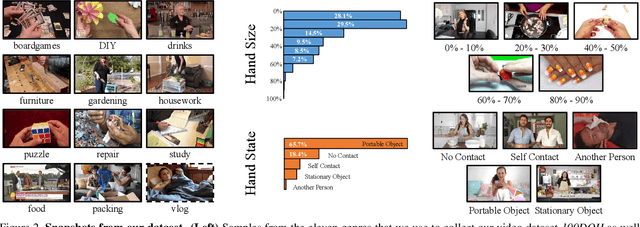
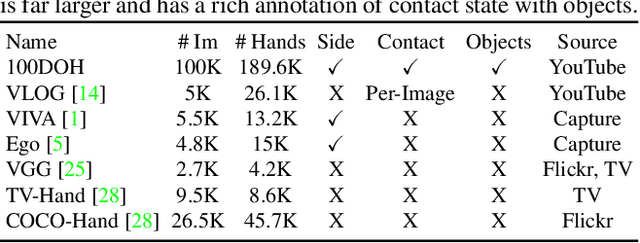
Hands are the central means by which humans manipulate their world and being able to reliably extract hand state information from Internet videos of humans engaged in their hands has the potential to pave the way to systems that can learn from petabytes of video data. This paper proposes steps towards this by inferring a rich representation of hands engaged in interaction method that includes: hand location, side, contact state, and a box around the object in contact. To support this effort, we gather a large-scale dataset of hands in contact with objects consisting of 131 days of footage as well as a 100K annotated hand-contact video frame dataset. The learned model on this dataset can serve as a foundation for hand-contact understanding in videos. We quantitatively evaluate it both on its own and in service of predicting and learning from 3D meshes of human hands.
Identifying Model Weakness with Adversarial Examiner
Nov 25, 2019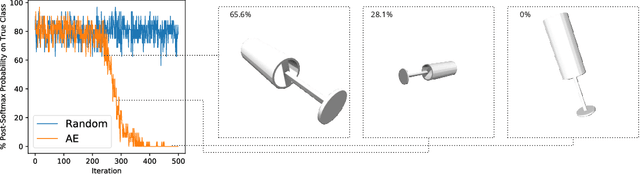

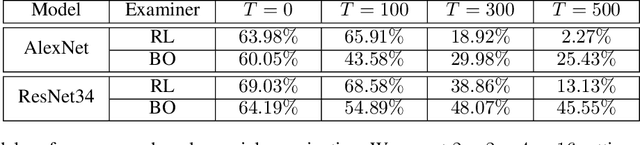
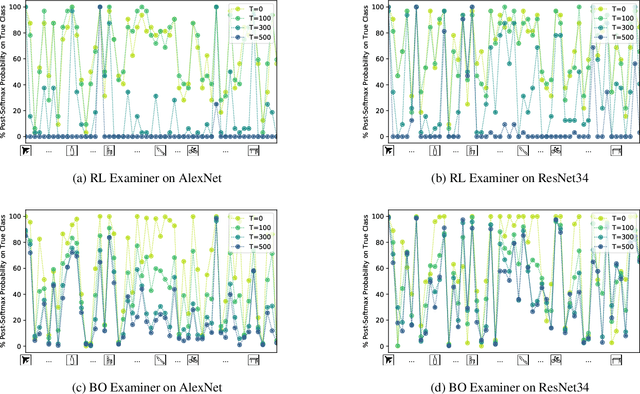
Machine learning models are usually evaluated according to the average case performance on the test set. However, this is not always ideal, because in some sensitive domains (e.g. autonomous driving), it is the worst case performance that matters more. In this paper, we are interested in systematic exploration of the input data space to identify the weakness of the model to be evaluated. We propose to use an adversarial examiner in the testing stage. Different from the existing strategy to always give the same (distribution of) test data, the adversarial examiner will dynamically select the next test data to hand out based on the testing history so far, with the goal being to undermine the model's performance. This sequence of test data not only helps us understand the current model, but also serves as constructive feedback to help improve the model in the next iteration. We conduct experiments on ShapeNet object classification. We show that our adversarial examiner can successfully put more emphasis on the weakness of the model, preventing performance estimates from being overly optimistic.
Region Refinement Network for Salient Object Detection
Jun 27, 2019
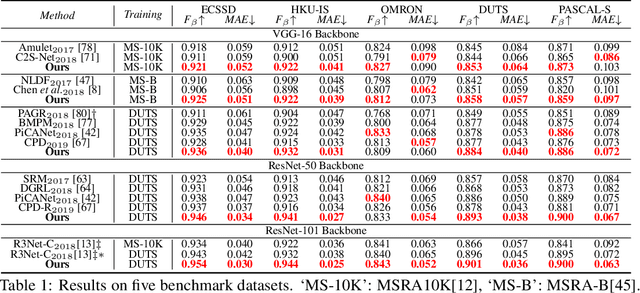


Albeit intensively studied, false prediction and unclear boundaries are still major issues of salient object detection. In this paper, we propose a Region Refinement Network (RRN), which recurrently filters redundant information and explicitly models boundary information for saliency detection. Different from existing refinement methods, we propose a Region Refinement Module (RRM) that optimizes salient region prediction by incorporating supervised attention masks in the intermediate refinement stages. The module only brings a minor increase in model size and yet significantly reduces false predictions from the background. To further refine boundary areas, we propose a Boundary Refinement Loss (BRL) that adds extra supervision for better distinguishing foreground from background. BRL is parameter free and easy to train. We further observe that BRL helps retain the integrity in prediction by refining the boundary. Extensive experiments on saliency detection datasets show that our refinement module and loss bring significant improvement to the baseline and can be easily applied to different frameworks. We also demonstrate that our proposed model generalizes well to portrait segmentation and shadow detection tasks.
Facelet-Bank for Fast Portrait Manipulation
Mar 30, 2018
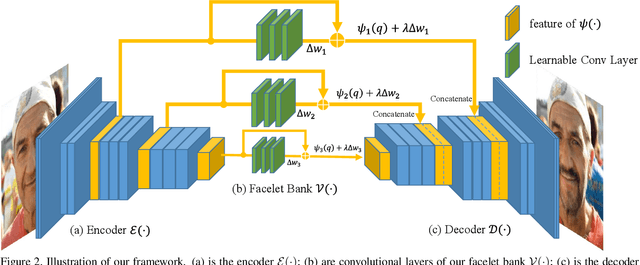


Digital face manipulation has become a popular and fascinating way to touch images with the prevalence of smartphones and social networks. With a wide variety of user preferences, facial expressions, and accessories, a general and flexible model is necessary to accommodate different types of facial editing. In this paper, we propose a model to achieve this goal based on an end-to-end convolutional neural network that supports fast inference, edit-effect control, and quick partial-model update. In addition, this model learns from unpaired image sets with different attributes. Experimental results show that our framework can handle a wide range of expressions, accessories, and makeup effects. It produces high-resolution and high-quality results in fast speed.