 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensor Low-Rank Reconstruction for Semantic Segmentation
Aug 02, 2020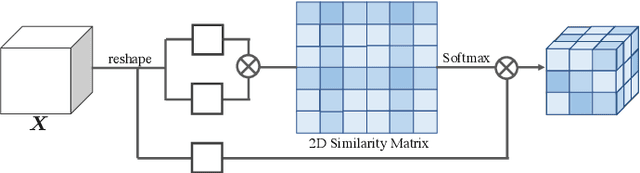
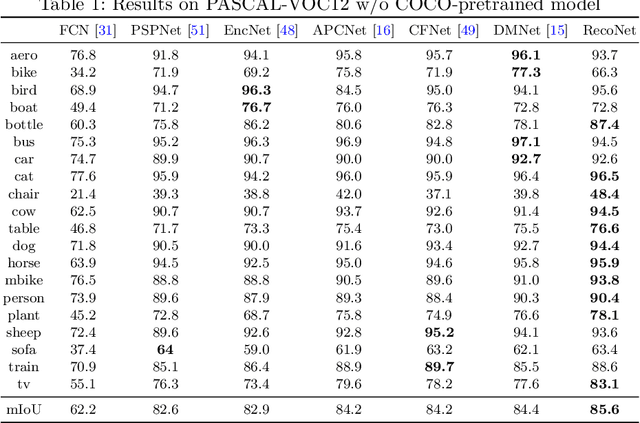
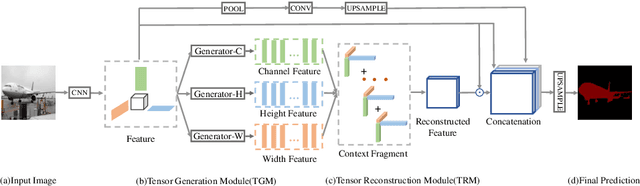
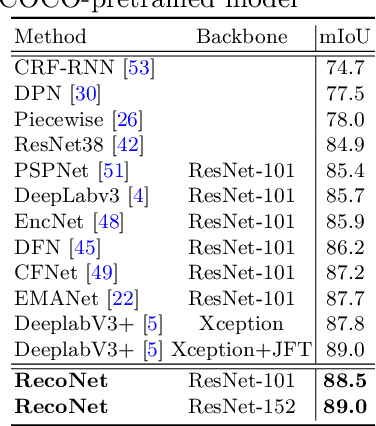
Context information plays an indispensable role in the success of semantic segmentation. Recently, non-local self-attention based methods are proved to be effective for context information collection. Since the desired context consists of spatial-wise and channel-wise attentions, 3D representation is an appropriate formulation. However, these non-local methods describe 3D context information based on a 2D similarity matrix, where space compression may lead to channel-wise attention missing. An alternative is to model the contextual information directly without compression. However, this effort confronts a fundamental difficulty, namely the high-rank property of context information. In this paper, we propose a new approach to model the 3D context representations, which not only avoids the space compression but also tackles the high-rank difficulty. Here, inspired by tensor canonical-polyadic decomposition theory (i.e, a high-rank tensor can be expressed as a combination of rank-1 tensors.), we design a low-rank-to-high-rank context reconstruction framework (i.e, RecoNet). Specifically, we first introduce the tensor generation module (TGM), which generates a number of rank-1 tensors to capture fragments of context feature. Then we use these rank-1 tensors to recover the high-rank context features through our proposed tensor reconstruction module (TRM). Extensive experiments show that our method achieves state-of-the-art on various public datasets. Additionally, our proposed method has more than 100 times less computational cost compared with conventional non-local-based methods.
DSGN: Deep Stereo Geometry Network for 3D Object Detection
Jan 10, 2020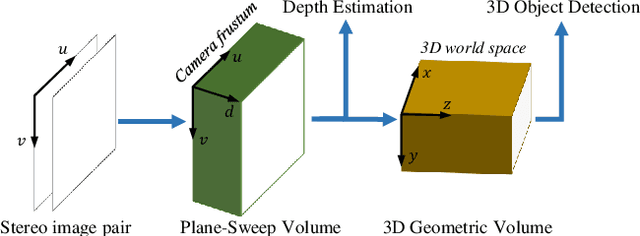
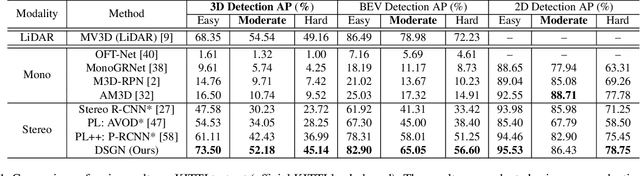
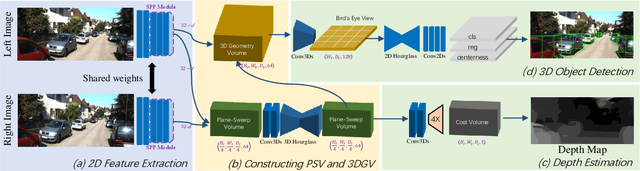
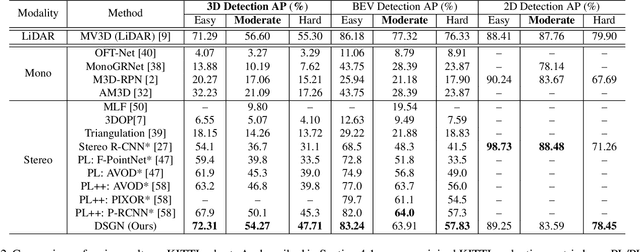
Most state-of-the-art 3D object detectors heavily rely on LiDAR sensors and there remains a large gap in terms of performance between image-based and LiDAR-based methods, caused by inappropriate representation for the prediction in 3D scenarios. Our method, called Deep Stereo Geometry Network (DSGN), reduces this gap significantly by detecting 3D objects on a differentiable volumetric representation -- 3D geometric volume, which effectively encodes 3D geometric structure for 3D regular space. With this representation, we learn depth information and semantic cues simultaneously. For the first time, we provide a simple and effective one-stage stereo-based 3D detection pipeline that jointly estimates the depth and detects 3D objects in an end-to-end learning manner. Our approach outperforms previous stereo-based 3D detectors (about 10 higher in terms of AP) and even achieves comparable performance with a few LiDAR-based methods on the KITTI 3D object detection leaderboard. Code will be made publicly available.
An Adversarial Perturbation Oriented Domain Adaptation Approach for Semantic Segmentation
Dec 18, 2019
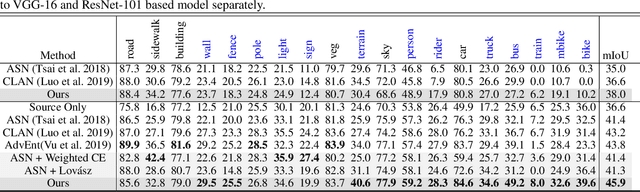
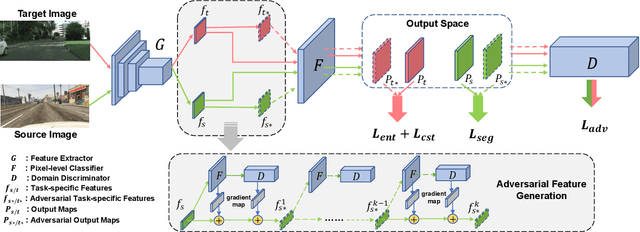
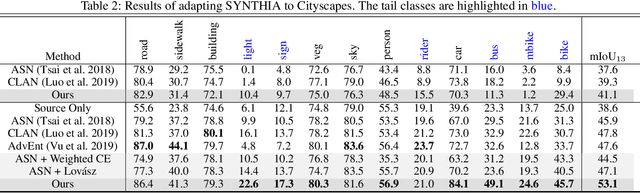
We focus on Unsupervised Domain Adaptation (UDA) for the task of semantic segmentation. Recently, adversarial alignment has been widely adopted to match the marginal distribution of feature representations across two domains globally. However, this strategy fails in adapting the representations of the tail classes or small objects for semantic segmentation since the alignment objective is dominated by head categories or large objects. In contrast to adversarial alignment, we propose to explicitly train a domain-invariant classifier by generating and defensing against pointwise feature space adversarial perturbations. Specifically, we firstly perturb the intermediate feature maps with several attack objectives (i.e., discriminator and classifier) on each individual position for both domains, and then the classifier is trained to be invariant to the perturbations. By perturbing each position individually, our model treats each location evenly regardless of the category or object size and thus circumvents the aforementioned issue. Moreover, the domain gap in feature space is reduced by extrapolating source and target perturbed features towards each other with attack on the domain discriminator. Our approach achieves the state-of-the-art performance on two challenging domain adaptation tasks for semantic segmentation: GTA5 -> Cityscapes and SYNTHIA -> Cityscapes.
Hierarchical Point-Edge Interaction Network for Point Cloud Semantic Segmentation
Sep 23, 2019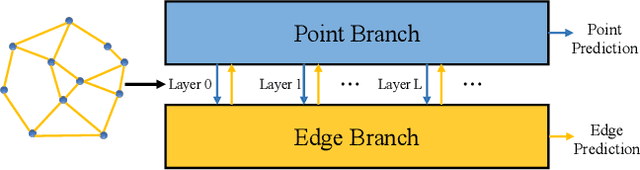

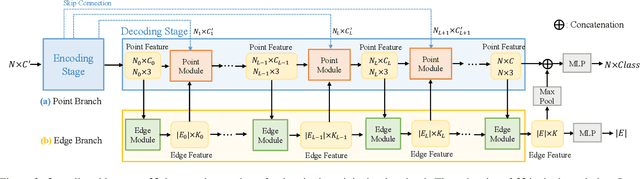
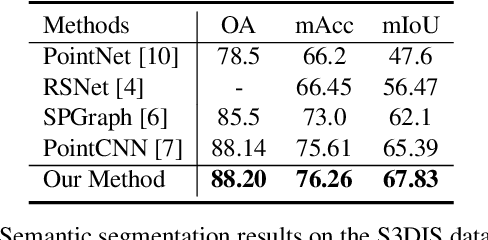
We achieve 3D semantic scene labeling by exploring semantic relation between each point and its contextual neighbors through edges. Besides an encoder-decoder branch for predicting point labels, we construct an edge branch to hierarchically integrate point features and generate edge features. To incorporate point features in the edge branch, we establish a hierarchical graph framework, where the graph is initialized from a coarse layer and gradually enriched along the point decoding process. For each edge in the final graph, we predict a label to indicate the semantic consistency of the two connected points to enhance point prediction. At different layers, edge features are also fed into the corresponding point module to integrate contextual information for message passing enhancement in local regions. The two branches interact with each other and cooperate in segmentation. Decent experimental results on several 3D semantic labeling datasets demonstrate the effectiveness of our work.
Reflective Decoding Network for Image Captioning
Aug 30, 2019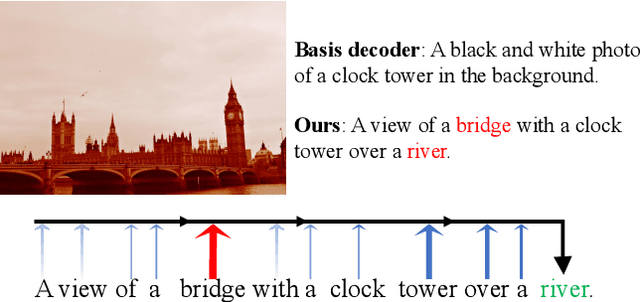

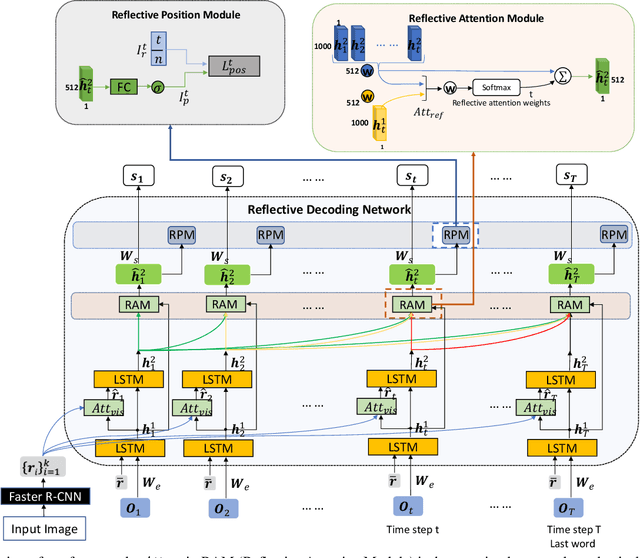
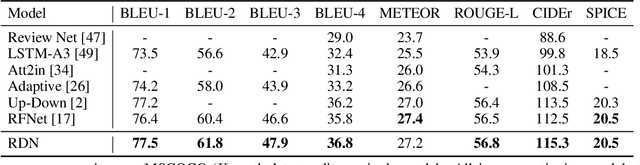
State-of-the-art image captioning methods mostly focus on improving visual features, less attention has been paid to utilizing the inherent properties of language to boost captioning performance. In this paper, we show that vocabulary coherence between words and syntactic paradigm of sentences are also important to generate high-quality image caption. Following the conventional encoder-decoder framework, we propose the Reflective Decoding Network (RDN) for image captioning, which enhances both the long-sequence dependency and position perception of words in a caption decoder. Our model learns to collaboratively attend on both visual and textual features and meanwhile perceive each word's relative position in the sentence to maximize the information delivered in the generated caption. We evaluate the effectiveness of our RDN on the COCO image captioning datasets and achieve superior performance over the previous methods. Further experiments reveal that our approach is particularly advantageous for hard cases with complex scenes to describe by captions.
Orthogonal Center Learning with Subspace Masking for Person Re-Identification
Aug 28, 2019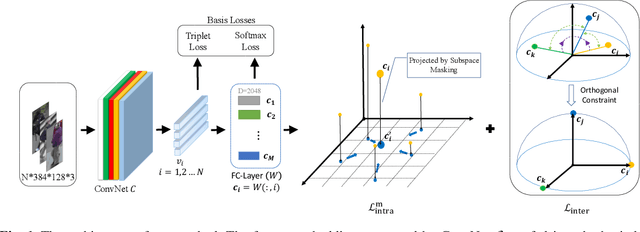
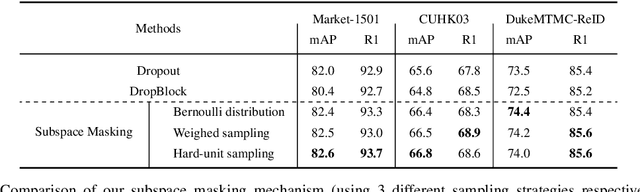
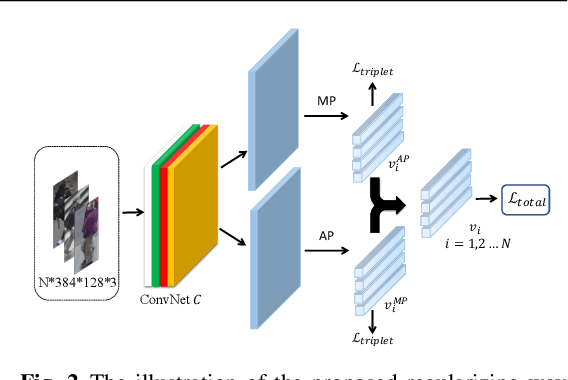
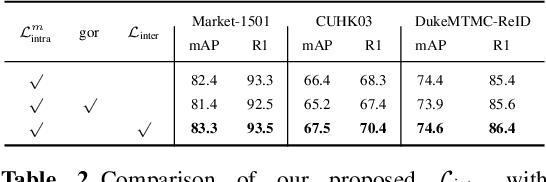
Person re-identification aims to identify whether pairs of images belong to the same person or not. This problem is challenging due to large differences in camera views, lighting and background. One of the mainstream in learning CNN features is to design loss functions which reinforce both the class separation and intra-class compactness. In this paper, we propose a novel Orthogonal Center Learning method with Subspace Masking for person re-identification. We make the following contributions: (i) we develop a center learning module to learn the class centers by simultaneously reducing the intra-class differences and inter-class correlations by orthogonalization; (ii) we introduce a subspace masking mechanism to enhance the generalization of the learned class centers; and (iii) we devise to integrate the average pooling and max pooling in a regularizing manner that fully exploits their powers. Extensive experiments show that our proposed method consistently outperforms the state-of-the-art methods on the large-scale ReID datasets including Market-1501, DukeMTMC-ReID, CUHK03 and MSMT17.
Non-local Recurrent Neural Memory for Supervised Sequence Modeling
Aug 26, 2019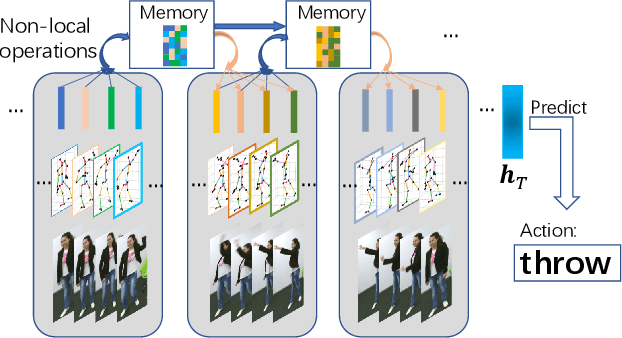
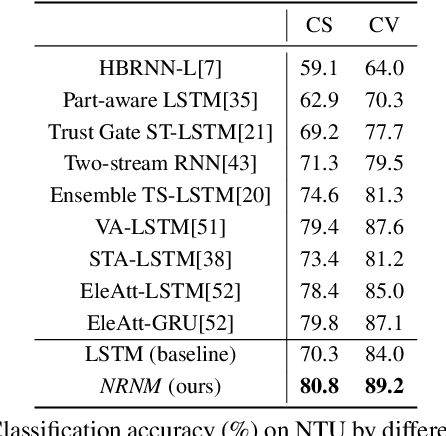
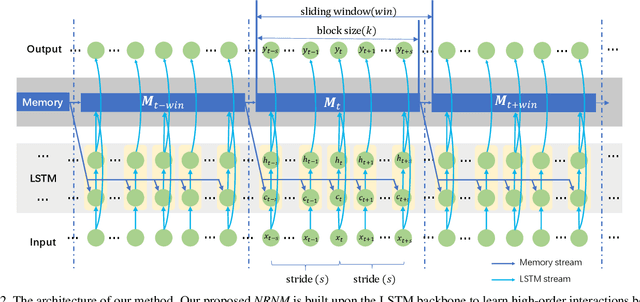
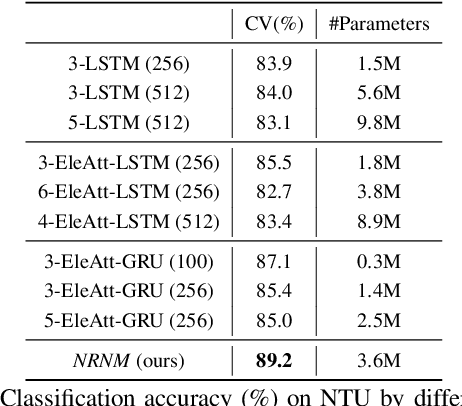
Typical methods for supervised sequence modeling are built upon the recurrent neural networks to capture temporal dependencies. One potential limitation of these methods is that they only model explicitly information interactions between adjacent time steps in a sequence, hence the high-order interactions between nonadjacent time steps are not fully exploited. It greatly limits the capability of modeling the long-range temporal dependencies since one-order interactions cannot be maintained for a long term due to information dilution and gradient vanishing. To tackle this limitation, we propose the Non-local Recurrent Neural Memory (NRNM) for supervised sequence modeling, which performs non-local operations to learn full-order interactions within a sliding temporal block and models global interactions between blocks in a gated recurrent manner. Consequently, our model is able to capture the long-range dependencies. Besides, the latent high-level features contained in high-order interactions can be distilled by our model. We demonstrate the merits of our NRNM on two different tasks: action recognition and sentiment analysis.
Cross-Domain Adaptation for Animal Pose Estimation
Aug 19, 2019
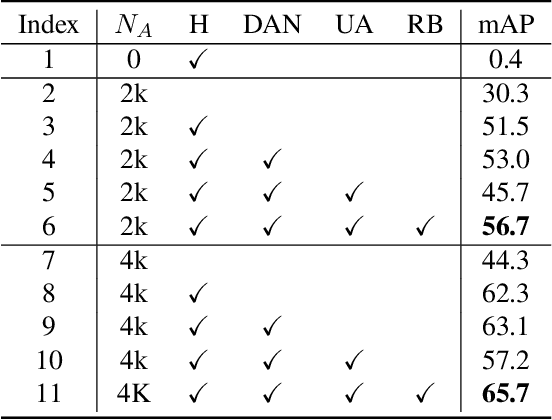
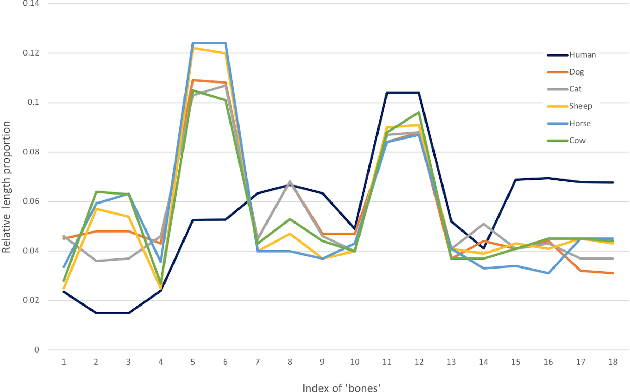
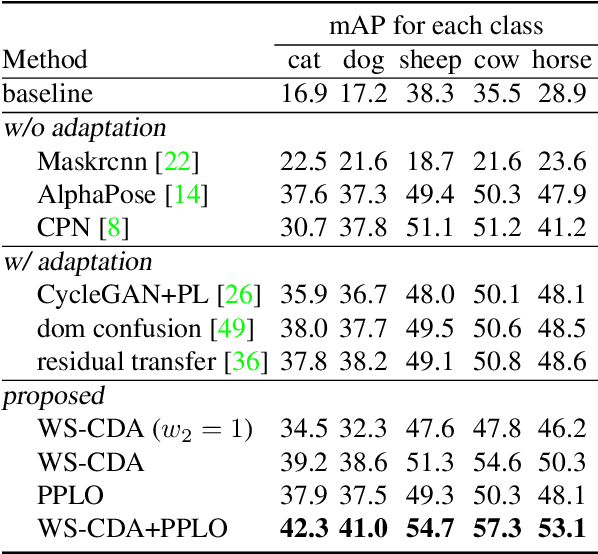
In this paper, we are interested in pose estimation of animals. Animals usually exhibit a wide range of variations on poses and there is no available animal pose dataset for training and testing. To address this problem, we build an animal pose dataset to facilitate training and evaluation. Considering the heavy labor needed to label dataset and it is impossible to label data for all concerned animal species, we, therefore, proposed a novel cross-domain adaptation method to transform the animal pose knowledge from labeled animal classes to unlabeled animal classes. We use the modest animal pose dataset to adapt learned knowledge to multiple animals species. Moreover, humans also share skeleton similarities with some animals (especially four-footed mammals). Therefore, the easily available human pose dataset, which is of a much larger scale than our labeled animal dataset, provides important prior knowledge to boost up the performance on animal pose estimation. Experiments show that our proposed method leverages these pieces of prior knowledge well and achieves convincing results on animal pose estimation.
Fast Point R-CNN
Aug 16, 2019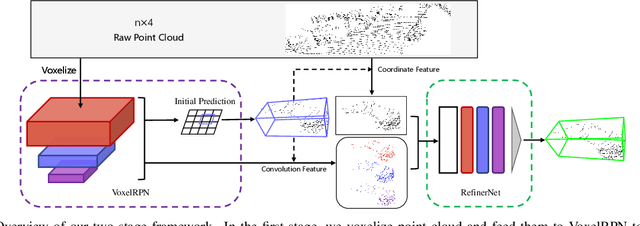
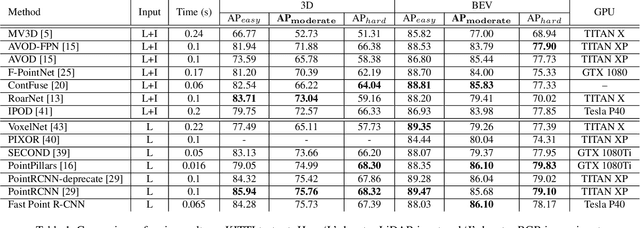
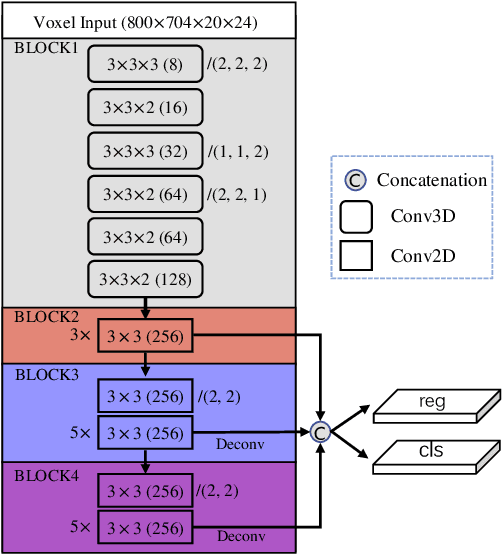

We present a unified, efficient and effective framework for point-cloud based 3D object detection. Our two-stage approach utilizes both voxel representation and raw point cloud data to exploit respective advantages. The first stage network, with voxel representation as input, only consists of light convolutional operations, producing a small number of high-quality initial predictions. Coordinate and indexed convolutional feature of each point in initial prediction are effectively fused with the attention mechanism, preserving both accurate localization and context information. The second stage works on interior points with their fused feature for further refining the prediction. Our method is evaluated on KITTI dataset, in terms of both 3D and Bird's Eye View (BEV) detection, and achieves state-of-the-arts with a 15FPS detection rate.
SF-Net: Structured Feature Network for Continuous Sign Language Recognition
Aug 04, 2019
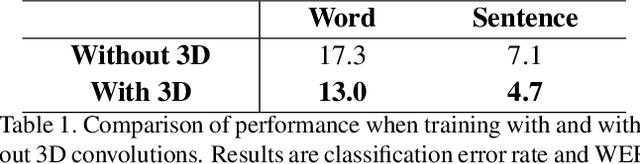

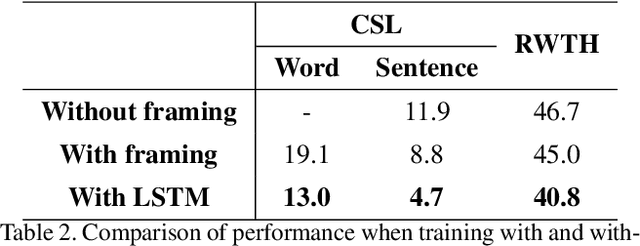
Continuous sign language recognition (SLR) aims to translate a signing sequence into a sentence. It is very challenging as sign language is rich in vocabulary, while many among them contain similar gestures and motions. Moreover, it is weakly supervised as the alignment of signing glosses is not available. In this paper, we propose Structured Feature Network (SF-Net) to address these challenges by effectively learn multiple levels of semantic information in the data. The proposed SF-Net extracts features in a structured manner and gradually encodes information at the frame level, the gloss level and the sentence level into the feature representation. The proposed SF-Net can be trained end-to-end without the help of other models or pre-training. We tested the proposed SF-Net on two large scale public SLR datasets collected from different continuous SLR scenarios. Results show that the proposed SF-Net clearly outperforms previous sequence level supervision based methods in terms of both accuracy and adaptability.