 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSF-Net: Structured Feature Network for Continuous Sign Language Recognition
Paper and Code
Aug 04, 2019
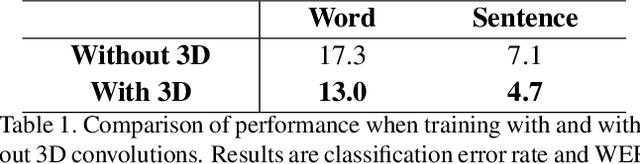

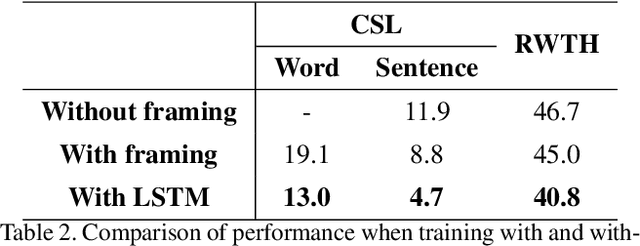
Continuous sign language recognition (SLR) aims to translate a signing sequence into a sentence. It is very challenging as sign language is rich in vocabulary, while many among them contain similar gestures and motions. Moreover, it is weakly supervised as the alignment of signing glosses is not available. In this paper, we propose Structured Feature Network (SF-Net) to address these challenges by effectively learn multiple levels of semantic information in the data. The proposed SF-Net extracts features in a structured manner and gradually encodes information at the frame level, the gloss level and the sentence level into the feature representation. The proposed SF-Net can be trained end-to-end without the help of other models or pre-training. We tested the proposed SF-Net on two large scale public SLR datasets collected from different continuous SLR scenarios. Results show that the proposed SF-Net clearly outperforms previous sequence level supervision based methods in terms of both accuracy and adaptability.