 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing Context Information in Lifelong Sequential Modeling using Temporal Convolutional Networks
Feb 18, 2025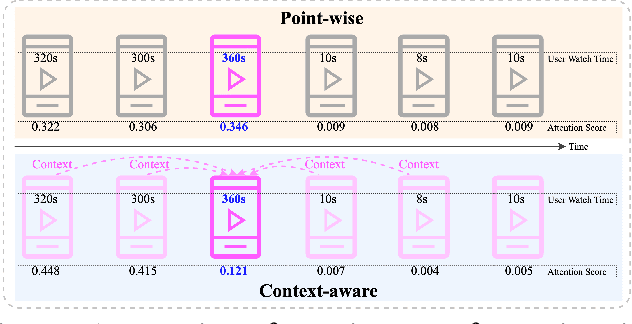
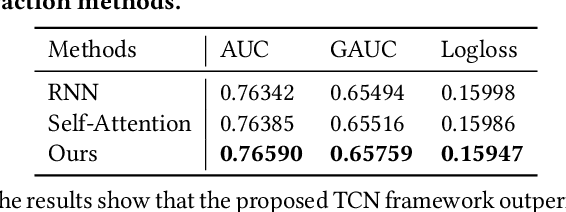
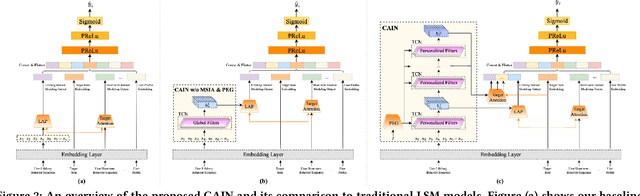
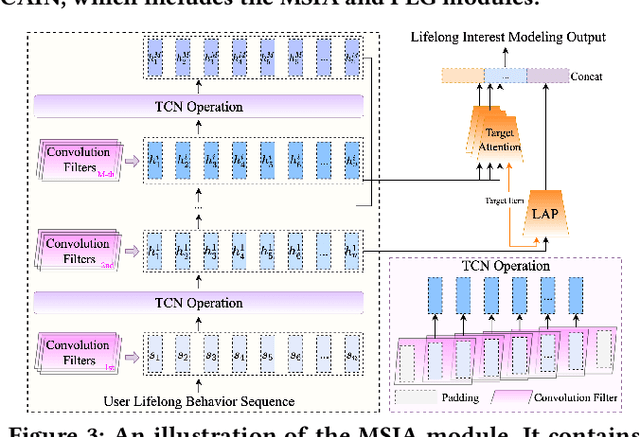
The importance of lifelong sequential modeling (LSM) is growing in the realm of social media recommendation systems. A key component in this process is the attention module, which derives interest representations with respect to candidate items from the sequence. Typically, attention modules function in a point-wise fashion, concentrating only on the relevance of individual items in the sequence to the candidate item. However, the context information in the neighboring items that is useful for more accurately evaluating the significance of each item has not been taken into account. In this study, we introduce a novel network which employs the Temporal Convolutional Network (TCN) to generate context-aware representations for each item throughout the lifelong sequence. These improved representations are then utilized in the attention module to produce context-aware interest representations. Expanding on this TCN framework, we present a enhancement module which includes multiple TCN layers and their respective attention modules to capture interest representations across different context scopes. Additionally, we also incorporate a lightweight sub-network to create convolution filters based on users' basic profile features. These personalized filters are then applied in the TCN layers instead of the original global filters to produce more user-specific representations. We performed experiments on both a public dataset and a proprietary dataset. The findings indicate that the proposed network surpasses existing methods in terms of prediction accuracy and online performance metrics.
Cross Domain LifeLong Sequential Modeling for Online Click-Through Rate Prediction
Dec 11, 2023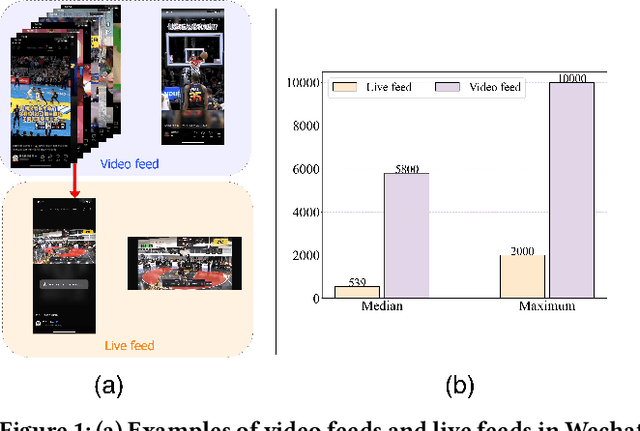

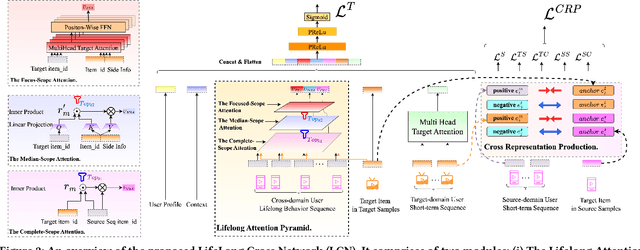
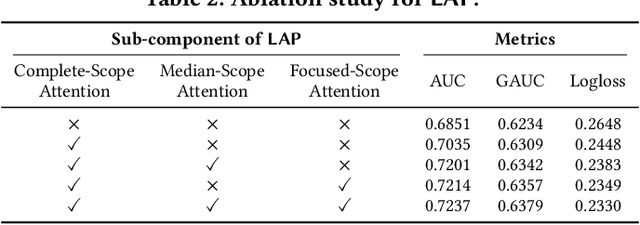
Deep neural networks (DNNs) that incorporated lifelong sequential modeling (LSM) have brought great success to recommendation systems in various social media platforms. While continuous improvements have been made in domain-specific LSM, limited work has been done in cross-domain LSM, which considers modeling of lifelong sequences of both target domain and source domain. In this paper, we propose Lifelong Cross Network (LCN) to incorporate cross-domain LSM to improve the click-through rate (CTR) prediction in the target domain. The proposed LCN contains a LifeLong Attention Pyramid (LAP) module that comprises of three levels of cascaded attentions to effectively extract interest representations with respect to the candidate item from lifelong sequences. We also propose Cross Representation Production (CRP) module to enforce additional supervision on the learning and alignment of cross-domain representations so that they can be better reused on learning of the CTR prediction in the target domain. We conducted extensive experiments on WeChat Channels industrial dataset as well as on benchmark dataset. Results have revealed that the proposed LCN outperforms existing work in terms of both prediction accuracy and online performance.
Fully Convolutional Networks for Continuous Sign Language Recognition
Jul 24, 2020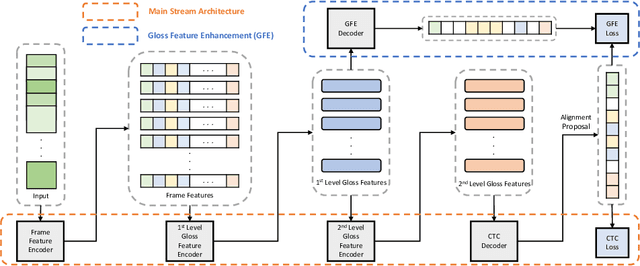
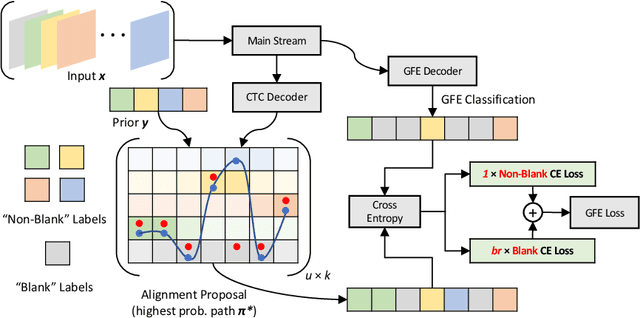
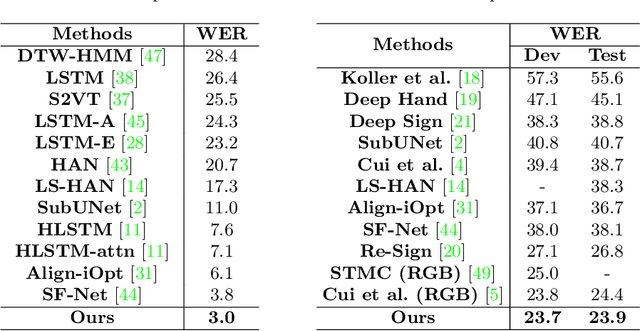
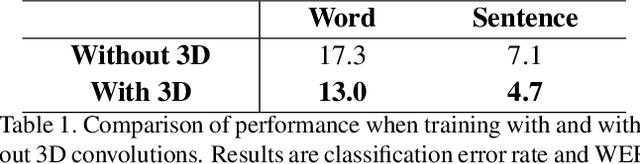
Continuous sign language recognition (SLR) is a challenging task that requires learning on both spatial and temporal dimensions of signing frame sequences. Most recent work accomplishes this by using CNN and RNN hybrid networks. However, training these networks is generally non-trivial, and most of them fail in learning unseen sequence patterns, causing an unsatisfactory performance for online recognition. In this paper, we propose a fully convolutional network (FCN) for online SLR to concurrently learn spatial and temporal features from weakly annotated video sequences with only sentence-level annotations given. A gloss feature enhancement (GFE) module is introduced in the proposed network to enforce better sequence alignment learning. The proposed network is end-to-end trainable without any pre-training. We conduct experiments on two large scale SLR datasets. Experiments show that our method for continuous SLR is effective and performs well in online recognition.
SF-Net: Structured Feature Network for Continuous Sign Language Recognition
Aug 04, 2019

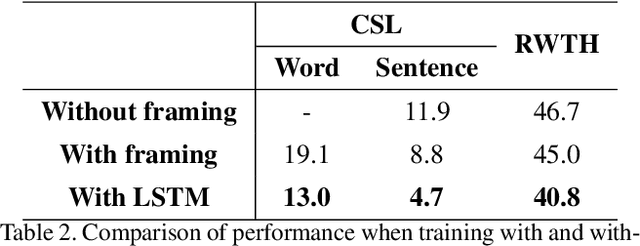
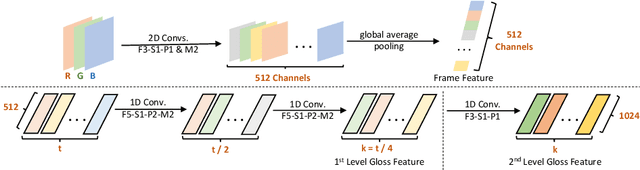
Continuous sign language recognition (SLR) aims to translate a signing sequence into a sentence. It is very challenging as sign language is rich in vocabulary, while many among them contain similar gestures and motions. Moreover, it is weakly supervised as the alignment of signing glosses is not available. In this paper, we propose Structured Feature Network (SF-Net) to address these challenges by effectively learn multiple levels of semantic information in the data. The proposed SF-Net extracts features in a structured manner and gradually encodes information at the frame level, the gloss level and the sentence level into the feature representation. The proposed SF-Net can be trained end-to-end without the help of other models or pre-training. We tested the proposed SF-Net on two large scale public SLR datasets collected from different continuous SLR scenarios. Results show that the proposed SF-Net clearly outperforms previous sequence level supervision based methods in terms of both accuracy and adaptability.