 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Open-source World Models
Jan 28, 2026We present LingBot-World, an open-sourced world simulator stemming from video generation. Positioned as a top-tier world model, LingBot-World offers the following features. (1) It maintains high fidelity and robust dynamics in a broad spectrum of environments, including realism, scientific contexts, cartoon styles, and beyond. (2) It enables a minute-level horizon while preserving contextual consistency over time, which is also known as "long-term memory". (3) It supports real-time interactivity, achieving a latency of under 1 second when producing 16 frames per second. We provide public access to the code and model in an effort to narrow the divide between open-source and closed-source technologies. We believe our release will empower the community with practical applications across areas like content creation, gaming, and robot learning.
The World is Your Canvas: Painting Promptable Events with Reference Images, Trajectories, and Text
Dec 18, 2025



We present WorldCanvas, a framework for promptable world events that enables rich, user-directed simulation by combining text, trajectories, and reference images. Unlike text-only approaches and existing trajectory-controlled image-to-video methods, our multimodal approach combines trajectories -- encoding motion, timing, and visibility -- with natural language for semantic intent and reference images for visual grounding of object identity, enabling the generation of coherent, controllable events that include multi-agent interactions, object entry/exit, reference-guided appearance and counterintuitive events. The resulting videos demonstrate not only temporal coherence but also emergent consistency, preserving object identity and scene despite temporary disappearance. By supporting expressive world events generation, WorldCanvas advances world models from passive predictors to interactive, user-shaped simulators. Our project page is available at: https://worldcanvas.github.io/.
HoloCine: Holistic Generation of Cinematic Multi-Shot Long Video Narratives
Oct 23, 2025State-of-the-art text-to-video models excel at generating isolated clips but fall short of creating the coherent, multi-shot narratives, which are the essence of storytelling. We bridge this "narrative gap" with HoloCine, a model that generates entire scenes holistically to ensure global consistency from the first shot to the last. Our architecture achieves precise directorial control through a Window Cross-Attention mechanism that localizes text prompts to specific shots, while a Sparse Inter-Shot Self-Attention pattern (dense within shots but sparse between them) ensures the efficiency required for minute-scale generation. Beyond setting a new state-of-the-art in narrative coherence, HoloCine develops remarkable emergent abilities: a persistent memory for characters and scenes, and an intuitive grasp of cinematic techniques. Our work marks a pivotal shift from clip synthesis towards automated filmmaking, making end-to-end cinematic creation a tangible future. Our code is available at: https://holo-cine.github.io/.
VanGogh: A Unified Multimodal Diffusion-based Framework for Video Colorization
Jan 16, 2025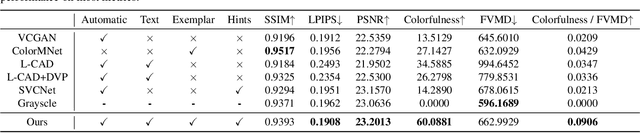
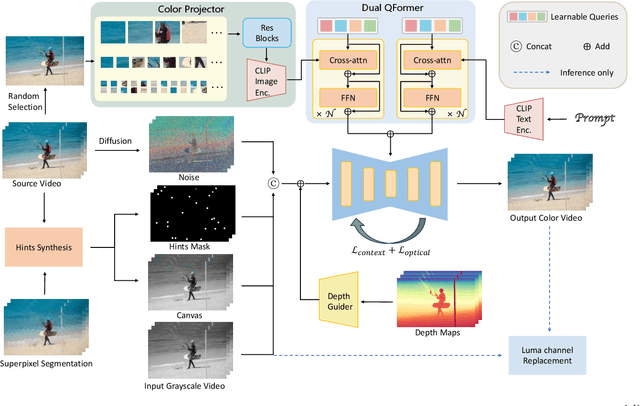


Video colorization aims to transform grayscale videos into vivid color representations while maintaining temporal consistency and structural integrity. Existing video colorization methods often suffer from color bleeding and lack comprehensive control, particularly under complex motion or diverse semantic cues. To this end, we introduce VanGogh, a unified multimodal diffusion-based framework for video colorization. VanGogh tackles these challenges using a Dual Qformer to align and fuse features from multiple modalities, complemented by a depth-guided generation process and an optical flow loss, which help reduce color overflow. Additionally, a color injection strategy and luma channel replacement are implemented to improve generalization and mitigate flickering artifacts. Thanks to this design, users can exercise both global and local control over the generation process, resulting in higher-quality colorized videos. Extensive qualitative and quantitative evaluations, and user studies, demonstrate that VanGogh achieves superior temporal consistency and color fidelity.Project page: https://becauseimbatman0.github.io/VanGogh.
MangaNinja: Line Art Colorization with Precise Reference Following
Jan 14, 2025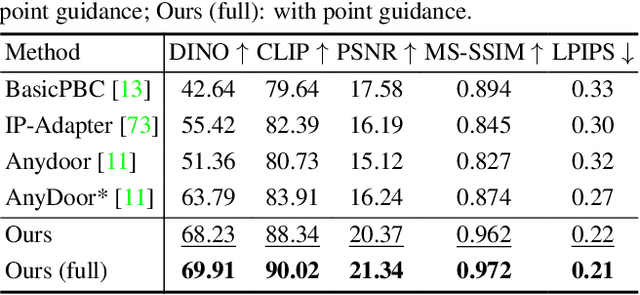
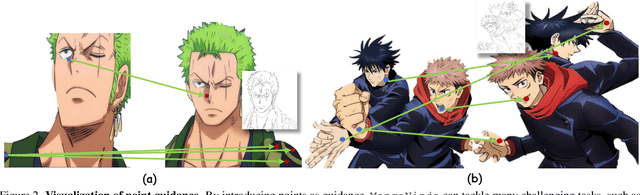
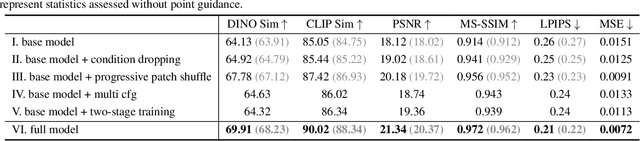
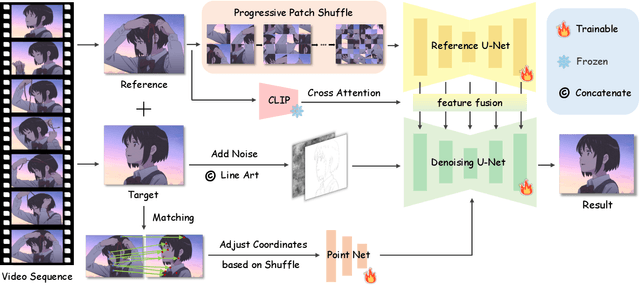
Derived from diffusion models, MangaNinjia specializes in the task of reference-guided line art colorization. We incorporate two thoughtful designs to ensure precise character detail transcription, including a patch shuffling module to facilitate correspondence learning between the reference color image and the target line art, and a point-driven control scheme to enable fine-grained color matching. Experiments on a self-collected benchmark demonstrate the superiority of our model over current solutions in terms of precise colorization. We further showcase the potential of the proposed interactive point control in handling challenging cases, cross-character colorization, multi-reference harmonization, beyond the reach of existing algorithms.
Edicho: Consistent Image Editing in the Wild
Dec 30, 2024As a verified need, consistent editing across in-the-wild images remains a technical challenge arising from various unmanageable factors, like object poses, lighting conditions, and photography environments. Edicho steps in with a training-free solution based on diffusion models, featuring a fundamental design principle of using explicit image correspondence to direct editing. Specifically, the key components include an attention manipulation module and a carefully refined classifier-free guidance (CFG) denoising strategy, both of which take into account the pre-estimated correspondence. Such an inference-time algorithm enjoys a plug-and-play nature and is compatible to most diffusion-based editing methods, such as ControlNet and BrushNet. Extensive results demonstrate the efficacy of Edicho in consistent cross-image editing under diverse settings. We will release the code to facilitate future studies.
DepthLab: From Partial to Complete
Dec 24, 2024



Missing values remain a common challenge for depth data across its wide range of applications, stemming from various causes like incomplete data acquisition and perspective alteration. This work bridges this gap with DepthLab, a foundation depth inpainting model powered by image diffusion priors. Our model features two notable strengths: (1) it demonstrates resilience to depth-deficient regions, providing reliable completion for both continuous areas and isolated points, and (2) it faithfully preserves scale consistency with the conditioned known depth when filling in missing values. Drawing on these advantages, our approach proves its worth in various downstream tasks, including 3D scene inpainting, text-to-3D scene generation, sparse-view reconstruction with DUST3R, and LiDAR depth completion, exceeding current solutions in both numerical performance and visual quality. Our project page with source code is available at https://johanan528.github.io/depthlab_web/.
LeviTor: 3D Trajectory Oriented Image-to-Video Synthesis
Dec 19, 2024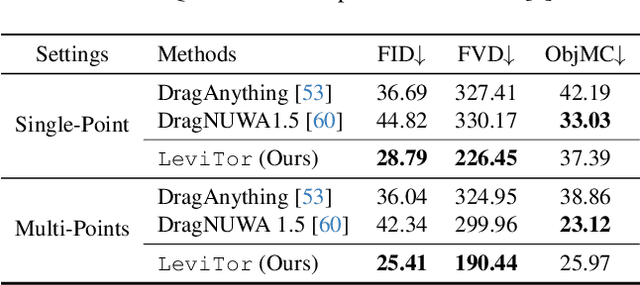
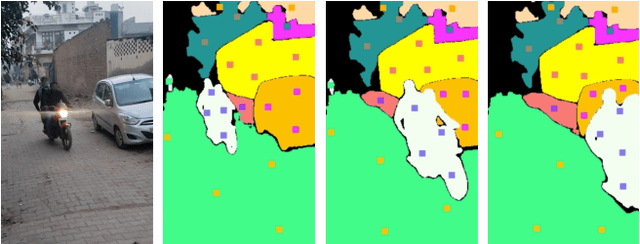
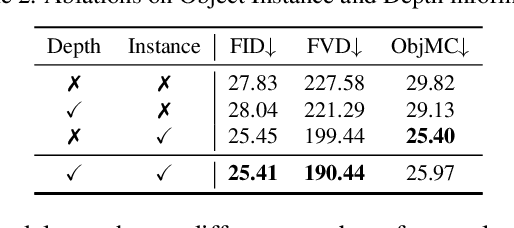
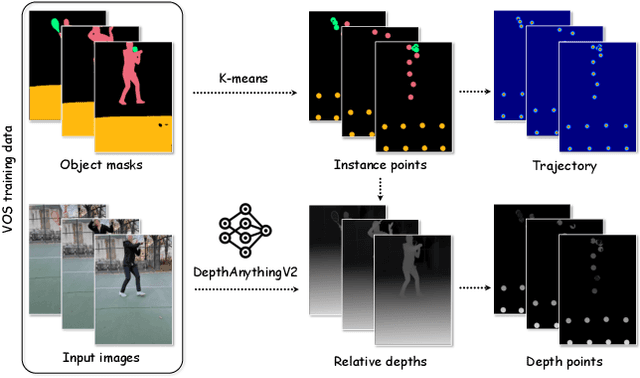
The intuitive nature of drag-based interaction has led to its growing adoption for controlling object trajectories in image-to-video synthesis. Still, existing methods that perform dragging in the 2D space usually face ambiguity when handling out-of-plane movements. In this work, we augment the interaction with a new dimension, i.e., the depth dimension, such that users are allowed to assign a relative depth for each point on the trajectory. That way, our new interaction paradigm not only inherits the convenience from 2D dragging, but facilitates trajectory control in the 3D space, broadening the scope of creativity. We propose a pioneering method for 3D trajectory control in image-to-video synthesis by abstracting object masks into a few cluster points. These points, accompanied by the depth information and the instance information, are finally fed into a video diffusion model as the control signal. Extensive experiments validate the effectiveness of our approach, dubbed LeviTor, in precisely manipulating the object movements when producing photo-realistic videos from static images. Project page: https://ppetrichor.github.io/levitor.github.io/
AniDoc: Animation Creation Made Easier
Dec 18, 2024The production of 2D animation follows an industry-standard workflow, encompassing four essential stages: character design, keyframe animation, in-betweening, and coloring. Our research focuses on reducing the labor costs in the above process by harnessing the potential of increasingly powerful generative AI. Using video diffusion models as the foundation, AniDoc emerges as a video line art colorization tool, which automatically converts sketch sequences into colored animations following the reference character specification. Our model exploits correspondence matching as an explicit guidance, yielding strong robustness to the variations (e.g., posture) between the reference character and each line art frame. In addition, our model could even automate the in-betweening process, such that users can easily create a temporally consistent animation by simply providing a character image as well as the start and end sketches. Our code is available at: https://yihao-meng.github.io/AniDoc_demo.
Towards Degradation-Robust Reconstruction in Generalizable NeRF
Nov 18, 2024Generalizable Neural Radiance Field (GNeRF) across scenes has been proven to be an effective way to avoid per-scene optimization by representing a scene with deep image features of source images. However, despite its potential for real-world applications, there has been limited research on the robustness of GNeRFs to different types of degradation present in the source images. The lack of such research is primarily attributed to the absence of a large-scale dataset fit for training a degradation-robust generalizable NeRF model. To address this gap and facilitate investigations into the degradation robustness of 3D reconstruction tasks, we construct the Objaverse Blur Dataset, comprising 50,000 images from over 1000 settings featuring multiple levels of blur degradation. In addition, we design a simple and model-agnostic module for enhancing the degradation robustness of GNeRFs. Specifically, by extracting 3D-aware features through a lightweight depth estimator and denoiser, the proposed module shows improvement on different popular methods in GNeRFs in terms of both quantitative and visual quality over varying degradation types and levels. Our dataset and code will be made publicly available.