 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiStream: Efficient High-Resolution Video Generation via Redundancy-Eliminated Streaming
Dec 24, 2025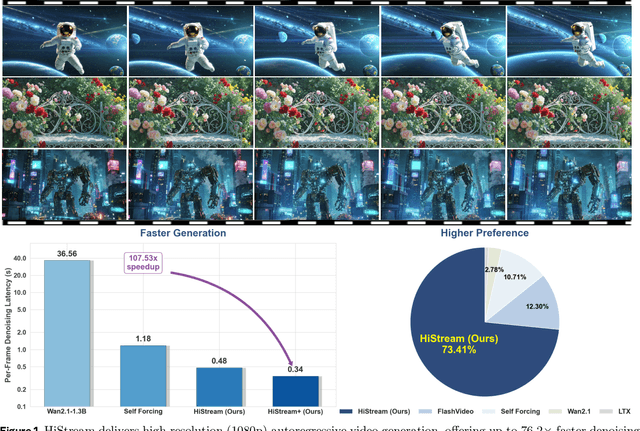
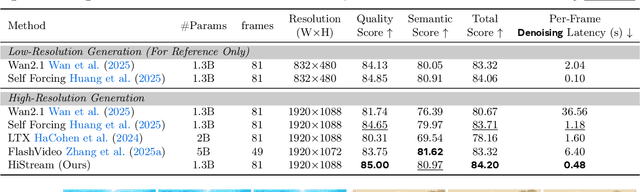
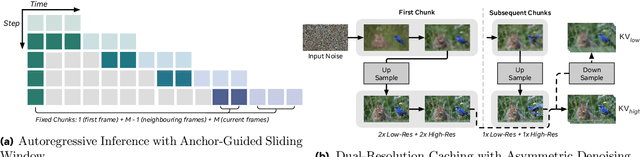
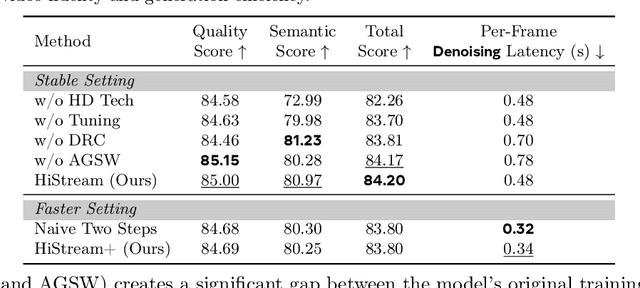
High-resolution video generation, while crucial for digital media and film, is computationally bottlenecked by the quadratic complexity of diffusion models, making practical inference infeasible. To address this, we introduce HiStream, an efficient autoregressive framework that systematically reduces redundancy across three axes: i) Spatial Compression: denoising at low resolution before refining at high resolution with cached features; ii) Temporal Compression: a chunk-by-chunk strategy with a fixed-size anchor cache, ensuring stable inference speed; and iii) Timestep Compression: applying fewer denoising steps to subsequent, cache-conditioned chunks. On 1080p benchmarks, our primary HiStream model (i+ii) achieves state-of-the-art visual quality while demonstrating up to 76.2x faster denoising compared to the Wan2.1 baseline and negligible quality loss. Our faster variant, HiStream+, applies all three optimizations (i+ii+iii), achieving a 107.5x acceleration over the baseline, offering a compelling trade-off between speed and quality, thereby making high-resolution video generation both practical and scalable.
OneStory: Coherent Multi-Shot Video Generation with Adaptive Memory
Dec 08, 2025
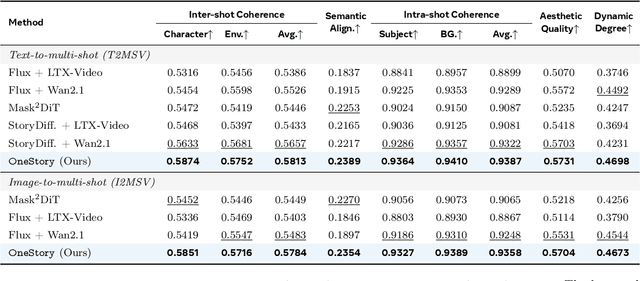
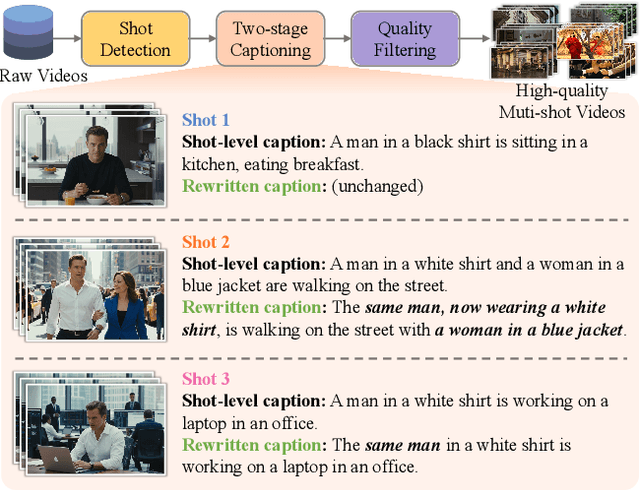

Storytelling in real-world videos often unfolds through multiple shots -- discontinuous yet semantically connected clips that together convey a coherent narrative. However, existing multi-shot video generation (MSV) methods struggle to effectively model long-range cross-shot context, as they rely on limited temporal windows or single keyframe conditioning, leading to degraded performance under complex narratives. In this work, we propose OneStory, enabling global yet compact cross-shot context modeling for consistent and scalable narrative generation. OneStory reformulates MSV as a next-shot generation task, enabling autoregressive shot synthesis while leveraging pretrained image-to-video (I2V) models for strong visual conditioning. We introduce two key modules: a Frame Selection module that constructs a semantically-relevant global memory based on informative frames from prior shots, and an Adaptive Conditioner that performs importance-guided patchification to generate compact context for direct conditioning. We further curate a high-quality multi-shot dataset with referential captions to mirror real-world storytelling patterns, and design effective training strategies under the next-shot paradigm. Finetuned from a pretrained I2V model on our curated 60K dataset, OneStory achieves state-of-the-art narrative coherence across diverse and complex scenes in both text- and image-conditioned settings, enabling controllable and immersive long-form video storytelling.
ShizhenGPT: Towards Multimodal LLMs for Traditional Chinese Medicine
Aug 20, 2025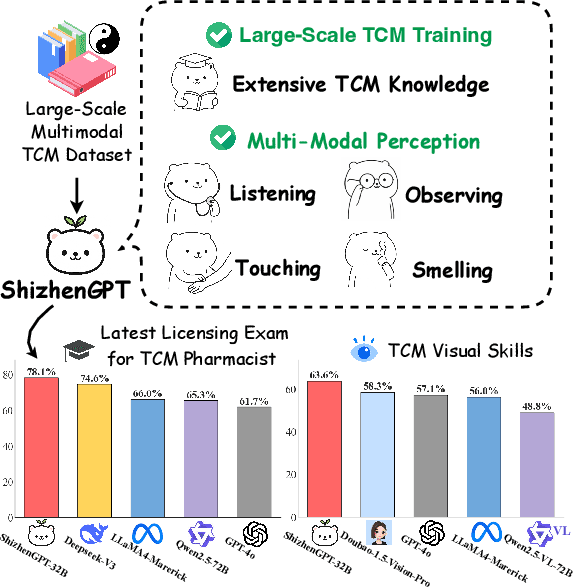
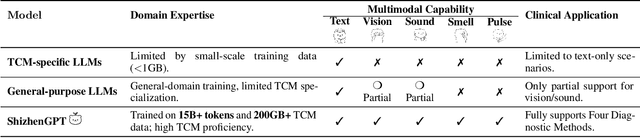
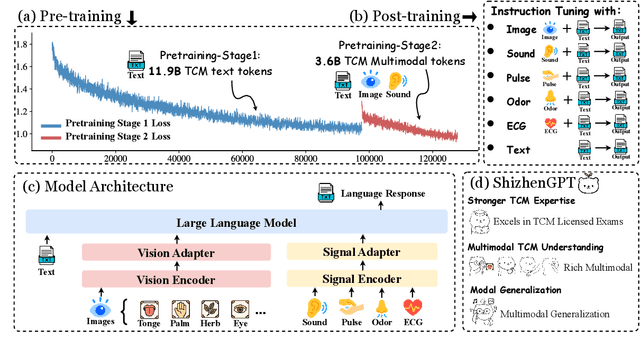
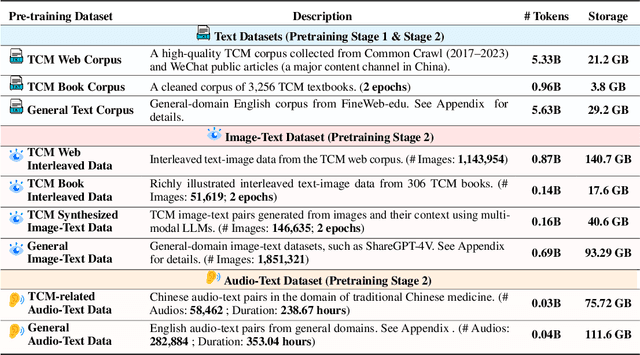
Despite the success of large language models (LLMs) in various domains, their potential in Traditional Chinese Medicine (TCM) remains largely underexplored due to two critical barriers: (1) the scarcity of high-quality TCM data and (2) the inherently multimodal nature of TCM diagnostics, which involve looking, listening, smelling, and pulse-taking. These sensory-rich modalities are beyond the scope of conventional LLMs. To address these challenges, we present ShizhenGPT, the first multimodal LLM tailored for TCM. To overcome data scarcity, we curate the largest TCM dataset to date, comprising 100GB+ of text and 200GB+ of multimodal data, including 1.2M images, 200 hours of audio, and physiological signals. ShizhenGPT is pretrained and instruction-tuned to achieve deep TCM knowledge and multimodal reasoning. For evaluation, we collect recent national TCM qualification exams and build a visual benchmark for Medicinal Recognition and Visual Diagnosis. Experiments demonstrate that ShizhenGPT outperforms comparable-scale LLMs and competes with larger proprietary models. Moreover, it leads in TCM visual understanding among existing multimodal LLMs and demonstrates unified perception across modalities like sound, pulse, smell, and vision, paving the way toward holistic multimodal perception and diagnosis in TCM. Datasets, models, and code are publicly available. We hope this work will inspire further exploration in this field.
Scaling Law for Quantization-Aware Training
May 20, 2025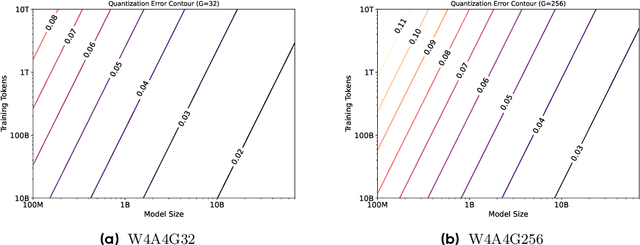
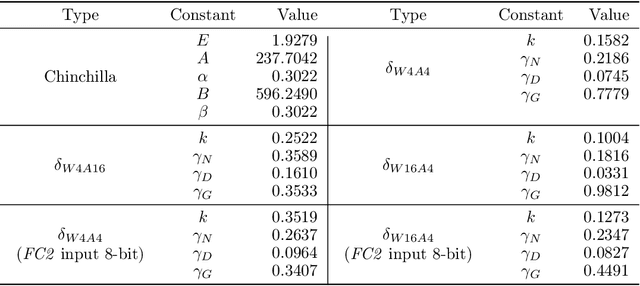
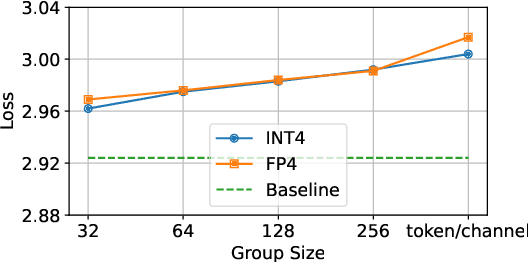
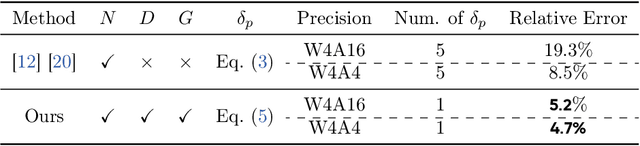
Large language models (LLMs) demand substantial computational and memory resources, creating deployment challenges. Quantization-aware training (QAT) addresses these challenges by reducing model precision while maintaining performance. However, the scaling behavior of QAT, especially at 4-bit precision (W4A4), is not well understood. Existing QAT scaling laws often ignore key factors such as the number of training tokens and quantization granularity, which limits their applicability. This paper proposes a unified scaling law for QAT that models quantization error as a function of model size, training data volume, and quantization group size. Through 268 QAT experiments, we show that quantization error decreases as model size increases, but rises with more training tokens and coarser quantization granularity. To identify the sources of W4A4 quantization error, we decompose it into weight and activation components. Both components follow the overall trend of W4A4 quantization error, but with different sensitivities. Specifically, weight quantization error increases more rapidly with more training tokens. Further analysis shows that the activation quantization error in the FC2 layer, caused by outliers, is the primary bottleneck of W4A4 QAT quantization error. By applying mixed-precision quantization to address this bottleneck, we demonstrate that weight and activation quantization errors can converge to similar levels. Additionally, with more training data, weight quantization error eventually exceeds activation quantization error, suggesting that reducing weight quantization error is also important in such scenarios. These findings offer key insights for improving QAT research and development.
DanceGRPO: Unleashing GRPO on Visual Generation
May 12, 2025
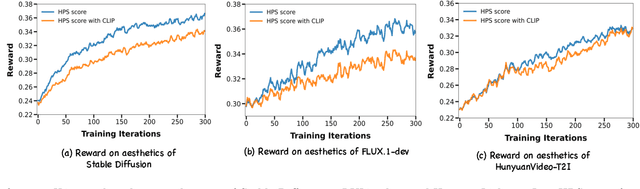
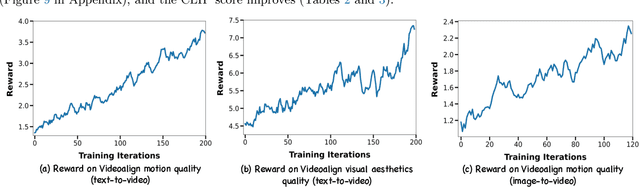

Recent breakthroughs in generative models-particularly diffusion models and rectified flows-have revolutionized visual content creation, yet aligning model outputs with human preferences remains a critical challenge. Existing reinforcement learning (RL)-based methods for visual generation face critical limitations: incompatibility with modern Ordinary Differential Equations (ODEs)-based sampling paradigms, instability in large-scale training, and lack of validation for video generation. This paper introduces DanceGRPO, the first unified framework to adapt Group Relative Policy Optimization (GRPO) to visual generation paradigms, unleashing one unified RL algorithm across two generative paradigms (diffusion models and rectified flows), three tasks (text-to-image, text-to-video, image-to-video), four foundation models (Stable Diffusion, HunyuanVideo, FLUX, SkyReel-I2V), and five reward models (image/video aesthetics, text-image alignment, video motion quality, and binary reward). To our knowledge, DanceGRPO is the first RL-based unified framework capable of seamless adaptation across diverse generative paradigms, tasks, foundational models, and reward models. DanceGRPO demonstrates consistent and substantial improvements, which outperform baselines by up to 181% on benchmarks such as HPS-v2.1, CLIP Score, VideoAlign, and GenEval. Notably, DanceGRPO not only can stabilize policy optimization for complex video generation, but also enables generative policy to better capture denoising trajectories for Best-of-N inference scaling and learn from sparse binary feedback. Our results establish DanceGRPO as a robust and versatile solution for scaling Reinforcement Learning from Human Feedback (RLHF) tasks in visual generation, offering new insights into harmonizing reinforcement learning and visual synthesis. The code will be released.
Fuzzy Clustering for Low-Complexity Time Domain Chromatic Dispersion Compensation Scheme in Coherent Optical Fiber Communication Systems
Mar 16, 2025Chromatic dispersion compensation (CDC), implemented in either the time-domain or frequency-domain, is crucial for enhancing power efficiency in the digital signal processing of modern optical fiber communication systems. Developing low-complexity CDC schemes is essential for hardware implemention, particularly for high-speed and long-haul optical fiber communication systems. In this work, we propose a novel two-stage fuzzy clustered time-domain chromatic dispersion compensation scheme. Unlike hard decisions of CDC filter coefficients after determining the cluster centroids, our approach applies a soft fuzzy decision, allowing the coefficients to belong to multiple clusters. Experiments on a single-channel, single-polarization 20Gbaud 16-QAM 1800 km standard single-mode fiber communication system demonstrate that our approach has a complexity reduction of 53.8% and 40% compared with clustered TD-CDC and FD-CDC at a target Q-factor of 20% HD-FEC, respectively. Furthermore, the proposed method achieves the same optimal Q-factor as FD-CDC with a 27% complexity reduction.
Soundwave: Less is More for Speech-Text Alignment in LLMs
Feb 18, 2025Existing end-to-end speech large language models (LLMs) usually rely on large-scale annotated data for training, while data-efficient training has not been discussed in depth. We focus on two fundamental problems between speech and text: the representation space gap and sequence length inconsistency. We propose Soundwave, which utilizes an efficient training strategy and a novel architecture to address these issues. Results show that Soundwave outperforms the advanced Qwen2-Audio in speech translation and AIR-Bench speech tasks, using only one-fiftieth of the training data. Further analysis shows that Soundwave still retains its intelligence during conversation. The project is available at https://github.com/FreedomIntelligence/Soundwave.
VanGogh: A Unified Multimodal Diffusion-based Framework for Video Colorization
Jan 16, 2025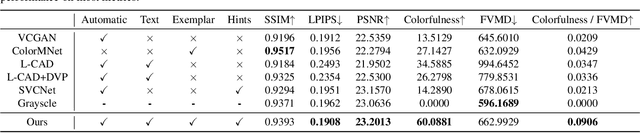
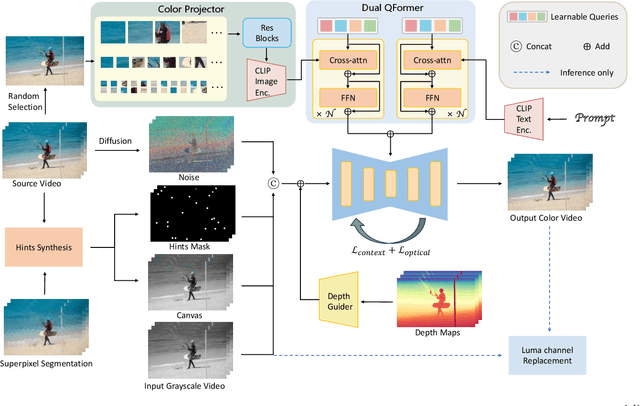


Video colorization aims to transform grayscale videos into vivid color representations while maintaining temporal consistency and structural integrity. Existing video colorization methods often suffer from color bleeding and lack comprehensive control, particularly under complex motion or diverse semantic cues. To this end, we introduce VanGogh, a unified multimodal diffusion-based framework for video colorization. VanGogh tackles these challenges using a Dual Qformer to align and fuse features from multiple modalities, complemented by a depth-guided generation process and an optical flow loss, which help reduce color overflow. Additionally, a color injection strategy and luma channel replacement are implemented to improve generalization and mitigate flickering artifacts. Thanks to this design, users can exercise both global and local control over the generation process, resulting in higher-quality colorized videos. Extensive qualitative and quantitative evaluations, and user studies, demonstrate that VanGogh achieves superior temporal consistency and color fidelity.Project page: https://becauseimbatman0.github.io/VanGogh.
MangaNinja: Line Art Colorization with Precise Reference Following
Jan 14, 2025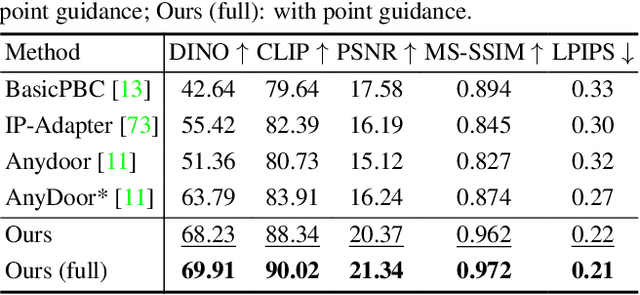
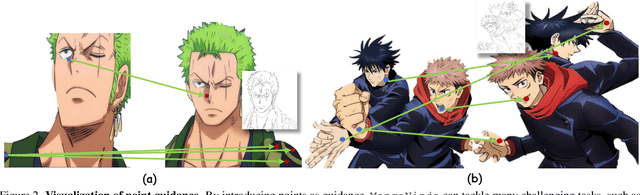
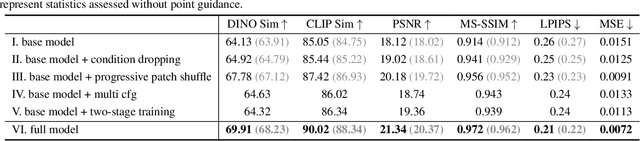
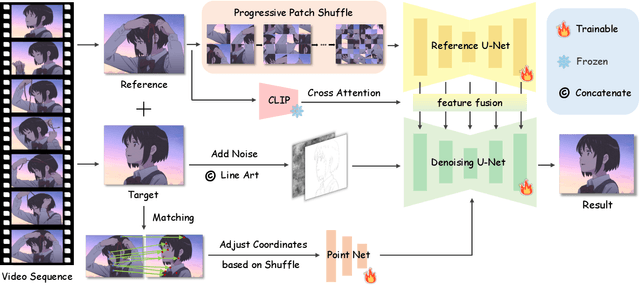
Derived from diffusion models, MangaNinjia specializes in the task of reference-guided line art colorization. We incorporate two thoughtful designs to ensure precise character detail transcription, including a patch shuffling module to facilitate correspondence learning between the reference color image and the target line art, and a point-driven control scheme to enable fine-grained color matching. Experiments on a self-collected benchmark demonstrate the superiority of our model over current solutions in terms of precise colorization. We further showcase the potential of the proposed interactive point control in handling challenging cases, cross-character colorization, multi-reference harmonization, beyond the reach of existing algorithms.
DepthLab: From Partial to Complete
Dec 24, 2024



Missing values remain a common challenge for depth data across its wide range of applications, stemming from various causes like incomplete data acquisition and perspective alteration. This work bridges this gap with DepthLab, a foundation depth inpainting model powered by image diffusion priors. Our model features two notable strengths: (1) it demonstrates resilience to depth-deficient regions, providing reliable completion for both continuous areas and isolated points, and (2) it faithfully preserves scale consistency with the conditioned known depth when filling in missing values. Drawing on these advantages, our approach proves its worth in various downstream tasks, including 3D scene inpainting, text-to-3D scene generation, sparse-view reconstruction with DUST3R, and LiDAR depth completion, exceeding current solutions in both numerical performance and visual quality. Our project page with source code is available at https://johanan528.github.io/depthlab_web/.