 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAAD-1: Asymmetric Adversarial Distillation for One-Step Autoregressive Video Generation
Jun 03, 2026We present AAD-1, an Asymmetric Adversarial Distillation framework for One-step autoregressive image-to-video generation. State-of-the-art methods adopt adversarial distillation but suffer from motion collapse and training instability, resulting in static videos. AAD-1 addresses these challenges through two key designs in architecture and training strategy. Our key architectural insight is to break the symmetry between generator and discriminator. While the generator remains causal to preserve autoregressive sampling capability, the discriminator attends bidirectionally over the full spatiotemporal context and produces a single holistic realism score for the entire video sequence. This asymmetric design enables the discriminator to effectively detect global temporal failures and long-range drift that cause motion collapse in autoregressive generation. To stabilize training, we introduce a phased strategy that first uses distribution matching to bootstrap a stable one-step generator, providing a warm-up phase that brings the student distribution closer to the teacher before adversarial distillation begins. Extensive experiments on VBench demonstrate that AAD-1 achieves state-of-the-art performance in one-step autoregressive video generation.
CausalCine: Real-Time Autoregressive Generation for Multi-Shot Video Narratives
May 12, 2026Autoregressive video generation aims at real-time, open-ended synthesis. Yet, cinematic storytelling is not merely the endless extension of a single scene; it requires progressing through evolving events, viewpoint shifts, and discrete shot boundaries. Existing autoregressive models often struggle in this setting. Trained primarily for short-horizon continuation, they treat long sequences as extended single shots, inevitably suffering from motion stagnation and semantic drift during long rollouts. To bridge this gap, we introduce CausalCine, an interactive autoregressive framework that transforms multi-shot video generation into an online directing process. CausalCine generates causally across shot changes, accepts dynamic prompts on the fly, and reuses context without regenerating previous shots. To achieve this, we first train a causal base model on native multi-shot sequences to learn complex shot transitions prior to acceleration. We then propose Content-Aware Memory Routing (CAMR), which dynamically retrieves historical KV entries according to attention-based relevance scores rather than temporal proximity, preserving cross-shot coherence under bounded active memory. Finally, we distill the causal base model into a few-step generator for real-time interactive generation. Extensive experiments demonstrate that CausalCine significantly outperforms autoregressive baselines and approaches the capability of bidirectional models while unlocking the streaming interactivity of causal generation. Demo available at https://yihao-meng.github.io/CausalCine/
Advancing Open-source World Models
Jan 28, 2026We present LingBot-World, an open-sourced world simulator stemming from video generation. Positioned as a top-tier world model, LingBot-World offers the following features. (1) It maintains high fidelity and robust dynamics in a broad spectrum of environments, including realism, scientific contexts, cartoon styles, and beyond. (2) It enables a minute-level horizon while preserving contextual consistency over time, which is also known as "long-term memory". (3) It supports real-time interactivity, achieving a latency of under 1 second when producing 16 frames per second. We provide public access to the code and model in an effort to narrow the divide between open-source and closed-source technologies. We believe our release will empower the community with practical applications across areas like content creation, gaming, and robot learning.
The World is Your Canvas: Painting Promptable Events with Reference Images, Trajectories, and Text
Dec 18, 2025



We present WorldCanvas, a framework for promptable world events that enables rich, user-directed simulation by combining text, trajectories, and reference images. Unlike text-only approaches and existing trajectory-controlled image-to-video methods, our multimodal approach combines trajectories -- encoding motion, timing, and visibility -- with natural language for semantic intent and reference images for visual grounding of object identity, enabling the generation of coherent, controllable events that include multi-agent interactions, object entry/exit, reference-guided appearance and counterintuitive events. The resulting videos demonstrate not only temporal coherence but also emergent consistency, preserving object identity and scene despite temporary disappearance. By supporting expressive world events generation, WorldCanvas advances world models from passive predictors to interactive, user-shaped simulators. Our project page is available at: https://worldcanvas.github.io/.
HoloCine: Holistic Generation of Cinematic Multi-Shot Long Video Narratives
Oct 23, 2025State-of-the-art text-to-video models excel at generating isolated clips but fall short of creating the coherent, multi-shot narratives, which are the essence of storytelling. We bridge this "narrative gap" with HoloCine, a model that generates entire scenes holistically to ensure global consistency from the first shot to the last. Our architecture achieves precise directorial control through a Window Cross-Attention mechanism that localizes text prompts to specific shots, while a Sparse Inter-Shot Self-Attention pattern (dense within shots but sparse between them) ensures the efficiency required for minute-scale generation. Beyond setting a new state-of-the-art in narrative coherence, HoloCine develops remarkable emergent abilities: a persistent memory for characters and scenes, and an intuitive grasp of cinematic techniques. Our work marks a pivotal shift from clip synthesis towards automated filmmaking, making end-to-end cinematic creation a tangible future. Our code is available at: https://holo-cine.github.io/.
Time Is a Feature: Exploiting Temporal Dynamics in Diffusion Language Models
Aug 12, 2025Diffusion large language models (dLLMs) generate text through iterative denoising, yet current decoding strategies discard rich intermediate predictions in favor of the final output. Our work here reveals a critical phenomenon, temporal oscillation, where correct answers often emerge in the middle process, but are overwritten in later denoising steps. To address this issue, we introduce two complementary methods that exploit temporal consistency: 1) Temporal Self-Consistency Voting, a training-free, test-time decoding strategy that aggregates predictions across denoising steps to select the most consistent output; and 2) a post-training method termed Temporal Consistency Reinforcement, which uses Temporal Semantic Entropy (TSE), a measure of semantic stability across intermediate predictions, as a reward signal to encourage stable generations. Empirical results across multiple benchmarks demonstrate the effectiveness of our approach. Using the negative TSE reward alone, we observe a remarkable average improvement of 24.7% on the Countdown dataset over an existing dLLM. Combined with the accuracy reward, we achieve absolute gains of 2.0% on GSM8K, 4.3% on MATH500, 6.6% on SVAMP, and 25.3% on Countdown, respectively. Our findings underscore the untapped potential of temporal dynamics in dLLMs and offer two simple yet effective tools to harness them.
Orientation Matters: Making 3D Generative Models Orientation-Aligned
Jun 10, 2025Humans intuitively perceive object shape and orientation from a single image, guided by strong priors about canonical poses. However, existing 3D generative models often produce misaligned results due to inconsistent training data, limiting their usability in downstream tasks. To address this gap, we introduce the task of orientation-aligned 3D object generation: producing 3D objects from single images with consistent orientations across categories. To facilitate this, we construct Objaverse-OA, a dataset of 14,832 orientation-aligned 3D models spanning 1,008 categories. Leveraging Objaverse-OA, we fine-tune two representative 3D generative models based on multi-view diffusion and 3D variational autoencoder frameworks to produce aligned objects that generalize well to unseen objects across various categories. Experimental results demonstrate the superiority of our method over post-hoc alignment approaches. Furthermore, we showcase downstream applications enabled by our aligned object generation, including zero-shot object orientation estimation via analysis-by-synthesis and efficient arrow-based object rotation manipulation.
MangaNinja: Line Art Colorization with Precise Reference Following
Jan 14, 2025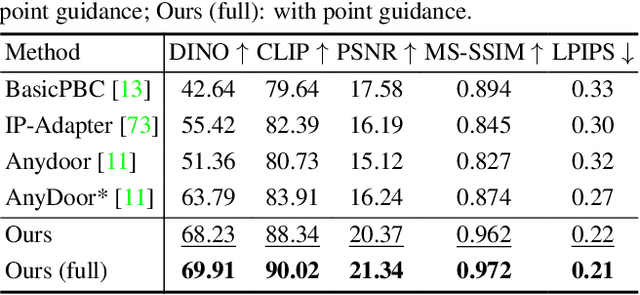
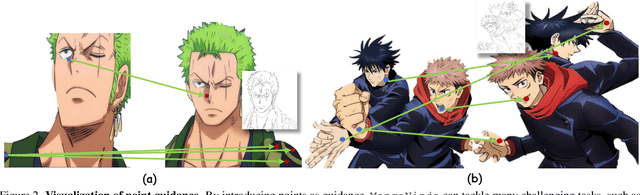
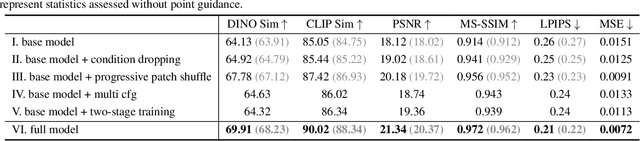
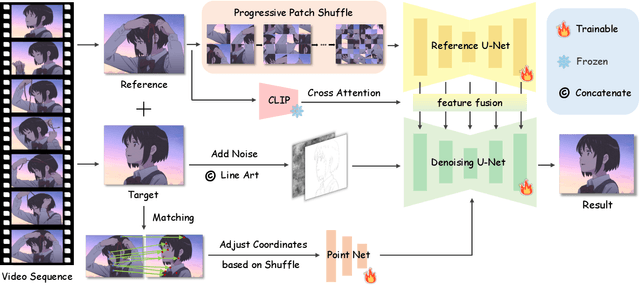
Derived from diffusion models, MangaNinjia specializes in the task of reference-guided line art colorization. We incorporate two thoughtful designs to ensure precise character detail transcription, including a patch shuffling module to facilitate correspondence learning between the reference color image and the target line art, and a point-driven control scheme to enable fine-grained color matching. Experiments on a self-collected benchmark demonstrate the superiority of our model over current solutions in terms of precise colorization. We further showcase the potential of the proposed interactive point control in handling challenging cases, cross-character colorization, multi-reference harmonization, beyond the reach of existing algorithms.
Edicho: Consistent Image Editing in the Wild
Dec 30, 2024As a verified need, consistent editing across in-the-wild images remains a technical challenge arising from various unmanageable factors, like object poses, lighting conditions, and photography environments. Edicho steps in with a training-free solution based on diffusion models, featuring a fundamental design principle of using explicit image correspondence to direct editing. Specifically, the key components include an attention manipulation module and a carefully refined classifier-free guidance (CFG) denoising strategy, both of which take into account the pre-estimated correspondence. Such an inference-time algorithm enjoys a plug-and-play nature and is compatible to most diffusion-based editing methods, such as ControlNet and BrushNet. Extensive results demonstrate the efficacy of Edicho in consistent cross-image editing under diverse settings. We will release the code to facilitate future studies.
DepthLab: From Partial to Complete
Dec 24, 2024



Missing values remain a common challenge for depth data across its wide range of applications, stemming from various causes like incomplete data acquisition and perspective alteration. This work bridges this gap with DepthLab, a foundation depth inpainting model powered by image diffusion priors. Our model features two notable strengths: (1) it demonstrates resilience to depth-deficient regions, providing reliable completion for both continuous areas and isolated points, and (2) it faithfully preserves scale consistency with the conditioned known depth when filling in missing values. Drawing on these advantages, our approach proves its worth in various downstream tasks, including 3D scene inpainting, text-to-3D scene generation, sparse-view reconstruction with DUST3R, and LiDAR depth completion, exceeding current solutions in both numerical performance and visual quality. Our project page with source code is available at https://johanan528.github.io/depthlab_web/.