 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWan-Move: Motion-controllable Video Generation via Latent Trajectory Guidance
Dec 09, 2025We present Wan-Move, a simple and scalable framework that brings motion control to video generative models. Existing motion-controllable methods typically suffer from coarse control granularity and limited scalability, leaving their outputs insufficient for practical use. We narrow this gap by achieving precise and high-quality motion control. Our core idea is to directly make the original condition features motion-aware for guiding video synthesis. To this end, we first represent object motions with dense point trajectories, allowing fine-grained control over the scene. We then project these trajectories into latent space and propagate the first frame's features along each trajectory, producing an aligned spatiotemporal feature map that tells how each scene element should move. This feature map serves as the updated latent condition, which is naturally integrated into the off-the-shelf image-to-video model, e.g., Wan-I2V-14B, as motion guidance without any architecture change. It removes the need for auxiliary motion encoders and makes fine-tuning base models easily scalable. Through scaled training, Wan-Move generates 5-second, 480p videos whose motion controllability rivals Kling 1.5 Pro's commercial Motion Brush, as indicated by user studies. To support comprehensive evaluation, we further design MoveBench, a rigorously curated benchmark featuring diverse content categories and hybrid-verified annotations. It is distinguished by larger data volume, longer video durations, and high-quality motion annotations. Extensive experiments on MoveBench and the public dataset consistently show Wan-Move's superior motion quality. Code, models, and benchmark data are made publicly available.
Towards a Unified View of Large Language Model Post-Training
Sep 04, 2025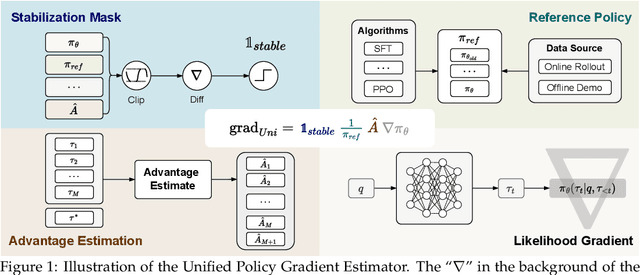

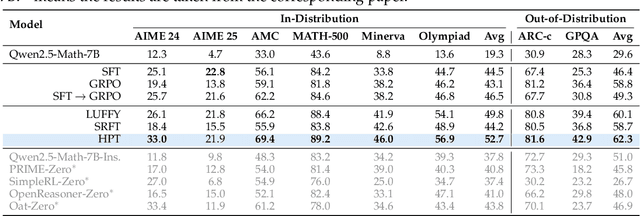
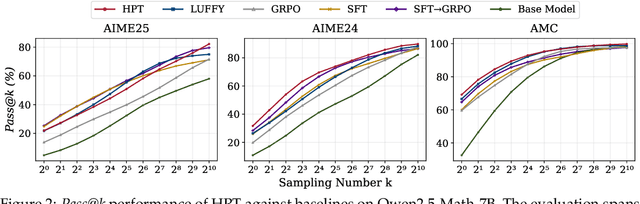
Two major sources of training data exist for post-training modern language models: online (model-generated rollouts) data, and offline (human or other-model demonstrations) data. These two types of data are typically used by approaches like Reinforcement Learning (RL) and Supervised Fine-Tuning (SFT), respectively. In this paper, we show that these approaches are not in contradiction, but are instances of a single optimization process. We derive a Unified Policy Gradient Estimator, and present the calculations of a wide spectrum of post-training approaches as the gradient of a common objective under different data distribution assumptions and various bias-variance tradeoffs. The gradient estimator is constructed with four interchangeable parts: stabilization mask, reference policy denominator, advantage estimate, and likelihood gradient. Motivated by our theoretical findings, we propose Hybrid Post-Training (HPT), an algorithm that dynamically selects different training signals. HPT is designed to yield both effective exploitation of demonstration and stable exploration without sacrificing learned reasoning patterns. We provide extensive experiments and ablation studies to verify the effectiveness of our unified theoretical framework and HPT. Across six mathematical reasoning benchmarks and two out-of-distribution suites, HPT consistently surpasses strong baselines across models of varying scales and families.
Framer: Interactive Frame Interpolation
Oct 24, 2024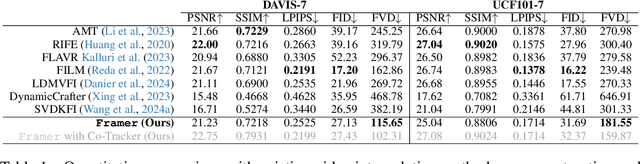
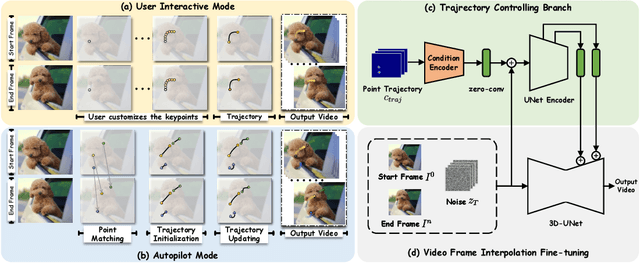
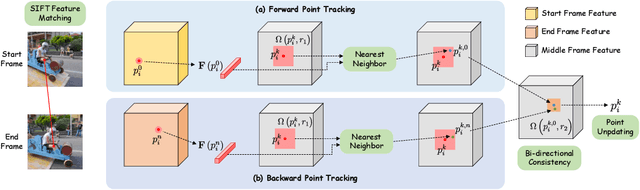

We propose Framer for interactive frame interpolation, which targets producing smoothly transitioning frames between two images as per user creativity. Concretely, besides taking the start and end frames as inputs, our approach supports customizing the transition process by tailoring the trajectory of some selected keypoints. Such a design enjoys two clear benefits. First, incorporating human interaction mitigates the issue arising from numerous possibilities of transforming one image to another, and in turn enables finer control of local motions. Second, as the most basic form of interaction, keypoints help establish the correspondence across frames, enhancing the model to handle challenging cases (e.g., objects on the start and end frames are of different shapes and styles). It is noteworthy that our system also offers an "autopilot" mode, where we introduce a module to estimate the keypoints and refine the trajectory automatically, to simplify the usage in practice. Extensive experimental results demonstrate the appealing performance of Framer on various applications, such as image morphing, time-lapse video generation, cartoon interpolation, etc. The code, the model, and the interface will be released to facilitate further research.
FreeCompose: Generic Zero-Shot Image Composition with Diffusion Prior
Jul 06, 2024We offer a novel approach to image composition, which integrates multiple input images into a single, coherent image. Rather than concentrating on specific use cases such as appearance editing (image harmonization) or semantic editing (semantic image composition), we showcase the potential of utilizing the powerful generative prior inherent in large-scale pre-trained diffusion models to accomplish generic image composition applicable to both scenarios. We observe that the pre-trained diffusion models automatically identify simple copy-paste boundary areas as low-density regions during denoising. Building on this insight, we propose to optimize the composed image towards high-density regions guided by the diffusion prior. In addition, we introduce a novel maskguided loss to further enable flexible semantic image composition. Extensive experiments validate the superiority of our approach in achieving generic zero-shot image composition. Additionally, our approach shows promising potential in various tasks, such as object removal and multiconcept customization.
Image Textualization: An Automatic Framework for Creating Accurate and Detailed Image Descriptions
Jun 11, 2024Image description datasets play a crucial role in the advancement of various applications such as image understanding, text-to-image generation, and text-image retrieval. Currently, image description datasets primarily originate from two sources. One source is the scraping of image-text pairs from the web. Despite their abundance, these descriptions are often of low quality and noisy. Another is through human labeling. Datasets such as COCO are generally very short and lack details. Although detailed image descriptions can be annotated by humans, the high annotation cost limits the feasibility. These limitations underscore the need for more efficient and scalable methods to generate accurate and detailed image descriptions. In this paper, we propose an innovative framework termed Image Textualization (IT), which automatically produces high-quality image descriptions by leveraging existing multi-modal large language models (MLLMs) and multiple vision expert models in a collaborative manner, which maximally convert the visual information into text. To address the current lack of benchmarks for detailed descriptions, we propose several benchmarks for comprehensive evaluation, which verifies the quality of image descriptions created by our framework. Furthermore, we show that LLaVA-7B, benefiting from training on IT-curated descriptions, acquire improved capability to generate richer image descriptions, substantially increasing the length and detail of their output with less hallucination.
AutoStory: Generating Diverse Storytelling Images with Minimal Human Effort
Nov 19, 2023



Story visualization aims to generate a series of images that match the story described in texts, and it requires the generated images to satisfy high quality, alignment with the text description, and consistency in character identities. Given the complexity of story visualization, existing methods drastically simplify the problem by considering only a few specific characters and scenarios, or requiring the users to provide per-image control conditions such as sketches. However, these simplifications render these methods incompetent for real applications. To this end, we propose an automated story visualization system that can effectively generate diverse, high-quality, and consistent sets of story images, with minimal human interactions. Specifically, we utilize the comprehension and planning capabilities of large language models for layout planning, and then leverage large-scale text-to-image models to generate sophisticated story images based on the layout. We empirically find that sparse control conditions, such as bounding boxes, are suitable for layout planning, while dense control conditions, e.g., sketches and keypoints, are suitable for generating high-quality image content. To obtain the best of both worlds, we devise a dense condition generation module to transform simple bounding box layouts into sketch or keypoint control conditions for final image generation, which not only improves the image quality but also allows easy and intuitive user interactions. In addition, we propose a simple yet effective method to generate multi-view consistent character images, eliminating the reliance on human labor to collect or draw character images.