 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
Nemotron-Cascade 2: Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation
Mar 19, 2026We introduce Nemotron-Cascade 2, an open 30B MoE model with 3B activated parameters that delivers best-in-class reasoning and strong agentic capabilities. Despite its compact size, its mathematical and coding reasoning performance approaches that of frontier open models. It is the second open-weight LLM, after DeepSeekV3.2-Speciale-671B-A37B, to achieve Gold Medal-level performance in the 2025 International Mathematical Olympiad (IMO), the International Olympiad in Informatics (IOI), and the ICPC World Finals, demonstrating remarkably high intelligence density with 20x fewer parameters. In contrast to Nemotron-Cascade 1, the key technical advancements are as follows. After SFT on a meticulously curated dataset, we substantially expand Cascade RL to cover a much broader spectrum of reasoning and agentic domains. Furthermore, we introduce multi-domain on-policy distillation from the strongest intermediate teacher models for each domain throughout the Cascade RL process, allowing us to efficiently recover benchmark regressions and sustain strong performance gains along the way. We release the collection of model checkpoint and training data.
On Data Engineering for Scaling LLM Terminal Capabilities
Feb 24, 2026Despite rapid recent progress in the terminal capabilities of large language models, the training data strategies behind state-of-the-art terminal agents remain largely undisclosed. We address this gap through a systematic study of data engineering practices for terminal agents, making two key contributions: (1) Terminal-Task-Gen, a lightweight synthetic task generation pipeline that supports seed-based and skill-based task construction, and (2) a comprehensive analysis of data and training strategies, including filtering, curriculum learning, long context training, and scaling behavior. Our pipeline yields Terminal-Corpus, a large-scale open-source dataset for terminal tasks. Using this dataset, we train Nemotron-Terminal, a family of models initialized from Qwen3(8B, 14B, 32B) that achieve substantial gains on Terminal-Bench 2.0: Nemotron-Terminal-8B improves from 2.5% to 13.0% Nemotron-Terminal-14B improves from 4.0% to 20.2%, and Nemotron-Terminal-32B improves from 3.4% to 27.4%, matching the performance of significantly larger models. To accelerate research in this domain, we open-source our model checkpoints and most of our synthetic datasets at https://huggingface.co/collections/nvidia/nemotron-terminal.
Beyond Accuracy: Evaluating Grounded Visual Evidence in Thinking with Images
Jan 14, 2026Despite the remarkable progress of Vision-Language Models (VLMs) in adopting "Thinking-with-Images" capabilities, accurately evaluating the authenticity of their reasoning process remains a critical challenge. Existing benchmarks mainly rely on outcome-oriented accuracy, lacking the capability to assess whether models can accurately leverage fine-grained visual cues for multi-step reasoning. To address these limitations, we propose ViEBench, a process-verifiable benchmark designed to evaluate faithful visual reasoning. Comprising 200 multi-scenario high-resolution images with expert-annotated visual evidence, ViEBench uniquely categorizes tasks by difficulty into perception and reasoning dimensions, where reasoning tasks require utilizing localized visual details with prior knowledge. To establish comprehensive evaluation criteria, we introduce a dual-axis matrix that provides fine-grained metrics through four diagnostic quadrants, enabling transparent diagnosis of model behavior across varying task complexities. Our experiments yield several interesting observations: (1) VLMs can sometimes produce correct final answers despite grounding on irrelevant regions, and (2) they may successfully locate the correct evidence but still fail to utilize it to reach accurate conclusions. Our findings demonstrate that ViEBench can serve as a more explainable and practical benchmark for comprehensively evaluating the effectiveness agentic VLMs. The codes will be released at: https://github.com/Xuchen-Li/ViEBench.
LongVideoAgent: Multi-Agent Reasoning with Long Videos
Dec 23, 2025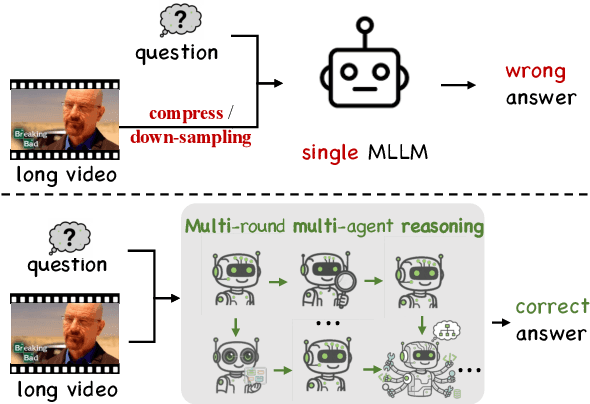


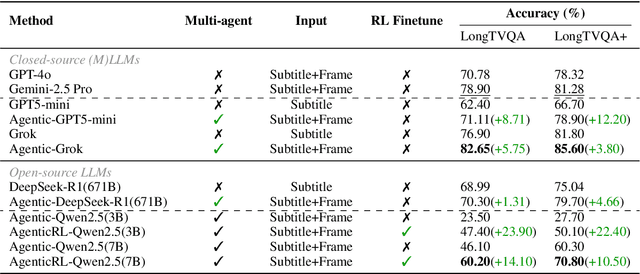
Recent advances in multimodal LLMs and systems that use tools for long-video QA point to the promise of reasoning over hour-long episodes. However, many methods still compress content into lossy summaries or rely on limited toolsets, weakening temporal grounding and missing fine-grained cues. We propose a multi-agent framework in which a master LLM coordinates a grounding agent to localize question-relevant segments and a vision agent to extract targeted textual observations. The master agent plans with a step limit, and is trained with reinforcement learning to encourage concise, correct, and efficient multi-agent cooperation. This design helps the master agent focus on relevant clips via grounding, complements subtitles with visual detail, and yields interpretable trajectories. On our proposed LongTVQA and LongTVQA+ which are episode-level datasets aggregated from TVQA/TVQA+, our multi-agent system significantly outperforms strong non-agent baselines. Experiments also show reinforcement learning further strengthens reasoning and planning for the trained agent. Code and data will be shared at https://longvideoagent.github.io/.
Look Less, Reason More: Rollout-Guided Adaptive Pixel-Space Reasoning
Oct 02, 2025Vision-Language Models (VLMs) excel at many multimodal tasks, yet they frequently struggle with tasks requiring precise understanding and handling of fine-grained visual elements. This is mainly due to information loss during image encoding or insufficient attention to critical regions. Recent work has shown promise by incorporating pixel-level visual information into the reasoning process, enabling VLMs to access high-resolution visual details during their thought process. However, this pixel-level information is often overused, leading to inefficiency and distraction from irrelevant visual details. To address these challenges, we propose the first framework for adaptive pixel reasoning that dynamically determines necessary pixel-level operations based on the input query. Specifically, we first apply operation-aware supervised fine-tuning to establish baseline competence in textual reasoning and visual operations, then design a novel rollout-guided reinforcement learning framework relying on feedback of the model's own responses, which enables the VLM to determine when pixel operations should be invoked based on query difficulty. Experiments on extensive multimodal reasoning benchmarks show that our model achieves superior performance while significantly reducing unnecessary visual operations. Impressively, our model achieves 73.4\% accuracy on HR-Bench 4K while maintaining a tool usage ratio of only 20.1\%, improving accuracy and simultaneously reducing tool usage by 66.5\% compared to the previous methods.
Pointing to a Llama and Call it a Camel: On the Sycophancy of Multimodal Large Language Models
Sep 19, 2025



Multimodal large language models (MLLMs) have demonstrated extraordinary capabilities in conducting conversations based on image inputs. However, we observe that MLLMs exhibit a pronounced form of visual sycophantic behavior. While similar behavior has also been noted in text-based large language models (LLMs), it becomes significantly more prominent when MLLMs process image inputs. We refer to this phenomenon as the "sycophantic modality gap." To better understand this issue, we further analyze the factors that contribute to the exacerbation of this gap. To mitigate the visual sycophantic behavior, we first experiment with naive supervised fine-tuning to help the MLLM resist misleading instructions from the user. However, we find that this approach also makes the MLLM overly resistant to corrective instructions (i.e., stubborn even if it is wrong). To alleviate this trade-off, we propose Sycophantic Reflective Tuning (SRT), which enables the MLLM to engage in reflective reasoning, allowing it to determine whether a user's instruction is misleading or corrective before drawing a conclusion. After applying SRT, we observe a significant reduction in sycophantic behavior toward misleading instructions, without resulting in excessive stubbornness when receiving corrective instructions.
Generalizable Geometric Image Caption Synthesis
Sep 18, 2025Multimodal large language models have various practical applications that demand strong reasoning abilities. Despite recent advancements, these models still struggle to solve complex geometric problems. A key challenge stems from the lack of high-quality image-text pair datasets for understanding geometric images. Furthermore, most template-based data synthesis pipelines typically fail to generalize to questions beyond their predefined templates. In this paper, we bridge this gap by introducing a complementary process of Reinforcement Learning with Verifiable Rewards (RLVR) into the data generation pipeline. By adopting RLVR to refine captions for geometric images synthesized from 50 basic geometric relations and using reward signals derived from mathematical problem-solving tasks, our pipeline successfully captures the key features of geometry problem-solving. This enables better task generalization and yields non-trivial improvements. Furthermore, even in out-of-distribution scenarios, the generated dataset enhances the general reasoning capabilities of multimodal large language models, yielding accuracy improvements of $2.8\%\text{-}4.8\%$ in statistics, arithmetic, algebraic, and numerical tasks with non-geometric input images of MathVista and MathVerse, along with $2.4\%\text{-}3.9\%$ improvements in Art, Design, Tech, and Engineering tasks in MMMU.
ExeSQL: Self-Taught Text-to-SQL Models with Execution-Driven Bootstrapping for SQL Dialects
May 22, 2025Recent text-to-SQL models have achieved strong performance, but their effectiveness remains largely confined to SQLite due to dataset limitations. However, real-world applications require SQL generation across multiple dialects with varying syntax and specialized features, which remains a challenge for current models. The main obstacle in building a dialect-aware model lies in acquiring high-quality dialect-specific data. Data generated purely through static prompting - without validating SQLs via execution - tends to be noisy and unreliable. Moreover, the lack of real execution environments in the training loop prevents models from grounding their predictions in executable semantics, limiting generalization despite surface-level improvements from data filtering. This work introduces ExeSQL, a text-to-SQL framework with execution-driven, agentic bootstrapping. The method consists of iterative query generation, execution-based filtering (e.g., rejection sampling), and preference-based training, enabling the model to adapt to new SQL dialects through verifiable, feedback-guided learning. Experiments show that ExeSQL bridges the dialect gap in text-to-SQL, achieving average improvements of 15.2%, 10.38%, and 4.49% over GPT-4o on PostgreSQL, MySQL, and Oracle, respectively, across multiple datasets of varying difficulty.
MR. Judge: Multimodal Reasoner as a Judge
May 19, 2025The paradigm of using Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) as evaluative judges has emerged as an effective approach in RLHF and inference-time scaling. In this work, we propose Multimodal Reasoner as a Judge (MR. Judge), a paradigm for empowering general-purpose MLLMs judges with strong reasoning capabilities. Instead of directly assigning scores for each response, we formulate the judgement process as a reasoning-inspired multiple-choice problem. Specifically, the judge model first conducts deliberate reasoning covering different aspects of the responses and eventually selects the best response from them. This reasoning process not only improves the interpretibility of the judgement, but also greatly enhances the performance of MLLM judges. To cope with the lack of questions with scored responses, we propose the following strategy to achieve automatic annotation: 1) Reverse Response Candidates Synthesis: starting from a supervised fine-tuning (SFT) dataset, we treat the original response as the best candidate and prompt the MLLM to generate plausible but flawed negative candidates. 2) Text-based reasoning extraction: we carefully design a data synthesis pipeline for distilling the reasoning capability from a text-based reasoning model, which is adopted to enable the MLLM judges to regain complex reasoning ability via warm up supervised fine-tuning. Experiments demonstrate that our MR. Judge is effective across a wide range of tasks. Specifically, our MR. Judge-7B surpasses GPT-4o by 9.9% on VL-RewardBench, and improves performance on MM-Vet during inference-time scaling by up to 7.7%.