 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Synthetic Layered Design Data Benefit Layered Design Decomposition?
May 14, 2026Recent advances in image generation have made it easy to produce high-quality images. However, these outputs are inherently flattened, entangling foreground elements, background, and text within a fixed canvas. As a result, flexible post-generation editing remains challenging, revealing a clear last-mile gap toward practical usability. Existing approaches either rely on scarce proprietary layered assets or construct partially synthetic data from limited structural priors. However, both strategies face fundamental challenges in scalability. In this work, we investigate whether pure synthetic layered data can improve graphic design decomposition. We make the assumption that, in graphic design, effective decomposition does not require modeling inter-layer dependencies as precisely as in natural-image composition, since design elements are often intentionally arranged as modular and semantically separable components. Concretely, we conduct a data-centric study based on CLD baseline, which is a state-of-the-art layer decomposition framework. Based on the baseline, we construct our own synthetic dataset, SynLayers, generate textual supervision using vision language models, and automate inference inputs with VLM-predicted bounding boxes. Our study reveals three key findings: (1) even training with purely synthetic data can outperform non-scalable alternatives such as the widely used PrismLayersPro dataset, demonstrating its viability as a scalable and effective substitute; (2) performance consistently improves with increased training data scale, while gains begin to saturate at around 50K samples; and (3) synthetic data enables balanced control over layer-count distributions, avoiding the layer-count imbalance commonly observed in real-world datasets. We hope this data-centric study encourages broader adoption of synthetic data as a practical foundation for layered design editing systems.
Task Vector Geometry Underlies Dual Modes of Task Inference in Transformers
May 05, 2026Transformers are effective at inferring the latent task from context via two inference modes: recognizing a task seen during training, and adapting to a novel one. Recent interpretability studies have identified from middle-layer representations task-specific directions, or task vectors, that steer model behavior. However, a lack of rigorous foundations hinders connecting internal representations to external model behavior: existing work fails to explain how task-vector geometry is shaped by the training distribution, and what geometry enables out-of-distribution (OOD) generalization. In this paper, we study these questions in a controlled synthetic setting by training small transformers from scratch on latent-task sequence distributions, which allows a principled mathematical characterization. We show that two inference modes can coexist within a single model. In-distribution behavior is governed by Bayesian task retrieval, implemented internally through convex combinations of learned task vectors. OOD behavior, by contrast, arises through extrapolative task learning, whose representations occupy a subspace nearly orthogonal to the task-vector subspace. Taken together, our results suggest that task-vector geometry, training distributions, and generalization behaviors are closely related.
Project Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
ClinCoT: Clinical-Aware Visual Chain-of-Thought for Medical Vision Language Models
Mar 01, 2026Medical Vision-Language Models have shown promising potential in clinical decision support, yet they remain prone to factual hallucinations due to insufficient grounding in localized pathological evidence. Existing medical alignment methods primarily operate at the response level through preference optimization, improving output correctness but leaving intermediate reasoning weakly connected to visual regions. Although chain-of-thought (CoT) enhances multimodal reasoning, it remains largely text-centric, limiting effective integration of clinical visual cues. To address this gap, we propose ClinCoT, a clinical-aware visual chain-of-thought framework that transforms preference optimization from response-level correction to visual-driven reasoning. We introduce an automatic data generation pipeline that constructs clinically grounded preference pairs through reasoning with hypotheses-driven region proposals. Multiple Med-LLMs evaluators rank and assign scores to each response, and these rankings serve as supervision to train the target model. We further introduce a scoring-based margin-aware optimization strategy that incorporates both preference ranking and score difference to refine region-level reasoning trajectories. To maintain alignment as the model's policy evolves during training, we adopt an iterative learning scheme that dynamically regenerates preference data. Extensive experiments on three medical VQA and report generation benchmarks demonstrate that ClinCoT consistently improves factual grounding and achieves superior performance compared with existing preference-based alignment methods.
Neuro-Symbolic Synergy for Interactive World Modeling
Feb 12, 2026Large language models (LLMs) exhibit strong general-purpose reasoning capabilities, yet they frequently hallucinate when used as world models (WMs), where strict compliance with deterministic transition rules--particularly in corner cases--is essential. In contrast, Symbolic WMs provide logical consistency but lack semantic expressivity. To bridge this gap, we propose Neuro-Symbolic Synergy (NeSyS), a framework that integrates the probabilistic semantic priors of LLMs with executable symbolic rules to achieve both expressivity and robustness. NeSyS alternates training between the two models using trajectories inadequately explained by the other. Unlike rule-based prompting, the symbolic WM directly constrains the LLM by modifying its output probability distribution. The neural WM is fine-tuned only on trajectories not covered by symbolic rules, reducing training data by 50% without loss of accuracy. Extensive experiments on three distinct interactive environments, i.e., ScienceWorld, Webshop, and Plancraft, demonstrate NeSyS's consistent advantages over baselines in both WM prediction accuracy and data efficiency.
APEX: Learning Adaptive Priorities for Multi-Objective Alignment in Vision-Language Generation
Jan 10, 2026Multi-objective alignment for text-to-image generation is commonly implemented via static linear scalarization, but fixed weights often fail under heterogeneous rewards, leading to optimization imbalance where models overfit high-variance, high-responsiveness objectives (e.g., OCR) while under-optimizing perceptual goals. We identify two mechanistic causes: variance hijacking, where reward dispersion induces implicit reweighting that dominates the normalized training signal, and gradient conflicts, where competing objectives produce opposing update directions and trigger seesaw-like oscillations. We propose APEX (Adaptive Priority-based Efficient X-objective Alignment), which stabilizes heterogeneous rewards with Dual-Stage Adaptive Normalization and dynamically schedules objectives via P^3 Adaptive Priorities that combine learning potential, conflict penalty, and progress need. On Stable Diffusion 3.5, APEX achieves improved Pareto trade-offs across four heterogeneous objectives, with balanced gains of +1.31 PickScore, +0.35 DeQA, and +0.53 Aesthetics while maintaining competitive OCR accuracy, mitigating the instability of multi-objective alignment.
SoccerMaster: A Vision Foundation Model for Soccer Understanding
Dec 11, 2025Soccer understanding has recently garnered growing research interest due to its domain-specific complexity and unique challenges. Unlike prior works that typically rely on isolated, task-specific expert models, this work aims to propose a unified model to handle diverse soccer visual understanding tasks, ranging from fine-grained perception (e.g., athlete detection) to semantic reasoning (e.g., event classification). Specifically, our contributions are threefold: (i) we present SoccerMaster, the first soccer-specific vision foundation model that unifies diverse understanding tasks within a single framework via supervised multi-task pretraining; (ii) we develop an automated data curation pipeline to generate scalable spatial annotations, and integrate them with various existing soccer video datasets to construct SoccerFactory, a comprehensive pretraining data resource; and (iii) we conduct extensive evaluations demonstrating that SoccerMaster consistently outperforms task-specific expert models across diverse downstream tasks, highlighting its breadth and superiority. The data, code, and model will be publicly available.
Towards Robust Visual Continual Learning with Multi-Prototype Supervision
Sep 19, 2025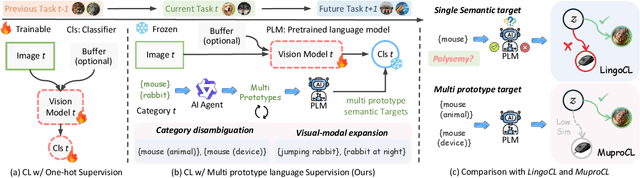
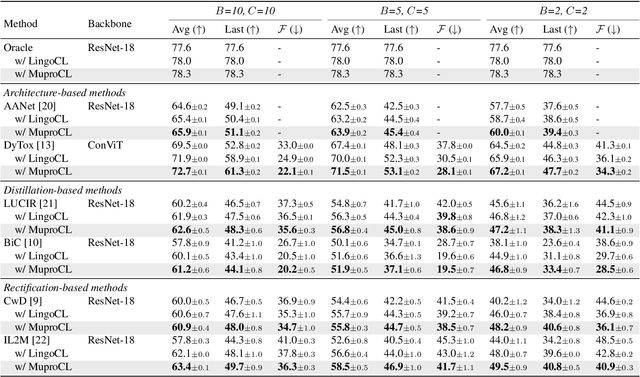
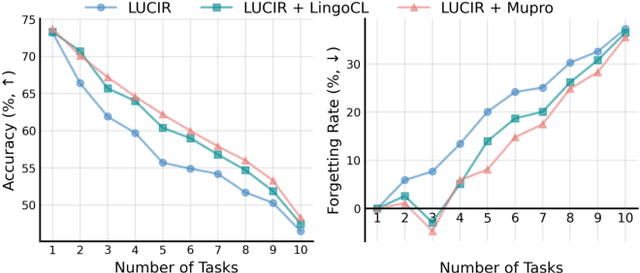
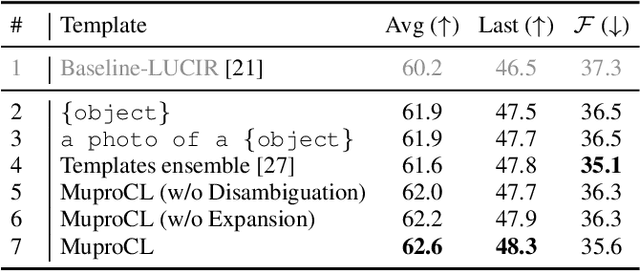
Language-guided supervision, which utilizes a frozen semantic target from a Pretrained Language Model (PLM), has emerged as a promising paradigm for visual Continual Learning (CL). However, relying on a single target introduces two critical limitations: 1) semantic ambiguity, where a polysemous category name results in conflicting visual representations, and 2) intra-class visual diversity, where a single prototype fails to capture the rich variety of visual appearances within a class. To this end, we propose MuproCL, a novel framework that replaces the single target with multiple, context-aware prototypes. Specifically, we employ a lightweight LLM agent to perform category disambiguation and visual-modal expansion to generate a robust set of semantic prototypes. A LogSumExp aggregation mechanism allows the vision model to adaptively align with the most relevant prototype for a given image. Extensive experiments across various CL baselines demonstrate that MuproCL consistently enhances performance and robustness, establishing a more effective path for language-guided continual learning.
Unifying Attention Heads and Task Vectors via Hidden State Geometry in In-Context Learning
May 24, 2025The unusual properties of in-context learning (ICL) have prompted investigations into the internal mechanisms of large language models. Prior work typically focuses on either special attention heads or task vectors at specific layers, but lacks a unified framework linking these components to the evolution of hidden states across layers that ultimately produce the model's output. In this paper, we propose such a framework for ICL in classification tasks by analyzing two geometric factors that govern performance: the separability and alignment of query hidden states. A fine-grained analysis of layer-wise dynamics reveals a striking two-stage mechanism: separability emerges in early layers, while alignment develops in later layers. Ablation studies further show that Previous Token Heads drive separability, while Induction Heads and task vectors enhance alignment. Our findings thus bridge the gap between attention heads and task vectors, offering a unified account of ICL's underlying mechanisms.
ExeSQL: Self-Taught Text-to-SQL Models with Execution-Driven Bootstrapping for SQL Dialects
May 22, 2025Recent text-to-SQL models have achieved strong performance, but their effectiveness remains largely confined to SQLite due to dataset limitations. However, real-world applications require SQL generation across multiple dialects with varying syntax and specialized features, which remains a challenge for current models. The main obstacle in building a dialect-aware model lies in acquiring high-quality dialect-specific data. Data generated purely through static prompting - without validating SQLs via execution - tends to be noisy and unreliable. Moreover, the lack of real execution environments in the training loop prevents models from grounding their predictions in executable semantics, limiting generalization despite surface-level improvements from data filtering. This work introduces ExeSQL, a text-to-SQL framework with execution-driven, agentic bootstrapping. The method consists of iterative query generation, execution-based filtering (e.g., rejection sampling), and preference-based training, enabling the model to adapt to new SQL dialects through verifiable, feedback-guided learning. Experiments show that ExeSQL bridges the dialect gap in text-to-SQL, achieving average improvements of 15.2%, 10.38%, and 4.49% over GPT-4o on PostgreSQL, MySQL, and Oracle, respectively, across multiple datasets of varying difficulty.