 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeLo: Dual Decomposed Low-Rank Experts Collaboration for Continual Missing Modality Learning
Mar 02, 2026Adapting Large Multimodal Models (LMMs) to real-world scenarios poses the dual challenges of learning from sequential data streams while handling frequent modality incompleteness, a task known as Continual Missing Modality Learning (CMML). However, existing works on CMML have predominantly relied on prompt tuning, a technique that struggles with this task due to cross-task interference between its learnable prompts in their shared embedding space. A naive application of Low-Rank Adaptation (LoRA) with modality-shared module will also suffer modality interference from competing gradients. To this end, we propose DeLo, the first framework to leverage a novel dual-decomposed low-rank expert architecture for CMML. Specifically, this architecture resolves modality interference through decomposed LoRA expert, dynamically composing LoRA update matrix with rank-one factors from disentangled modality-specific factor pools. Embedded within a task-partitioned framework that structurally prevents catastrophic forgetting, this expert system is supported by two key mechanisms: a Cross-Modal Guided Routing strategy to handle incomplete data and a Task-Key Memory for efficient, task-agnostic inference. Extensive experiments on established CMML benchmarks demonstrate that our method significantly outperforms state-of-the-art approaches. This highlights the value of a principled, architecturally-aware LoRA design for real-world multimodal challenges.
ClinCoT: Clinical-Aware Visual Chain-of-Thought for Medical Vision Language Models
Mar 01, 2026Medical Vision-Language Models have shown promising potential in clinical decision support, yet they remain prone to factual hallucinations due to insufficient grounding in localized pathological evidence. Existing medical alignment methods primarily operate at the response level through preference optimization, improving output correctness but leaving intermediate reasoning weakly connected to visual regions. Although chain-of-thought (CoT) enhances multimodal reasoning, it remains largely text-centric, limiting effective integration of clinical visual cues. To address this gap, we propose ClinCoT, a clinical-aware visual chain-of-thought framework that transforms preference optimization from response-level correction to visual-driven reasoning. We introduce an automatic data generation pipeline that constructs clinically grounded preference pairs through reasoning with hypotheses-driven region proposals. Multiple Med-LLMs evaluators rank and assign scores to each response, and these rankings serve as supervision to train the target model. We further introduce a scoring-based margin-aware optimization strategy that incorporates both preference ranking and score difference to refine region-level reasoning trajectories. To maintain alignment as the model's policy evolves during training, we adopt an iterative learning scheme that dynamically regenerates preference data. Extensive experiments on three medical VQA and report generation benchmarks demonstrate that ClinCoT consistently improves factual grounding and achieves superior performance compared with existing preference-based alignment methods.
DoAtlas-1: A Causal Compilation Paradigm for Clinical AI
Feb 22, 2026Medical foundation models generate narrative explanations but cannot quantify intervention effects, detect evidence conflicts, or validate literature claims, limiting clinical auditability. We propose causal compilation, a paradigm that transforms medical evidence from narrative text into executable code. The paradigm standardizes heterogeneous research evidence into structured estimand objects, each explicitly specifying intervention contrast, effect scale, time horizon, and target population, supporting six executable causal queries: do-calculus, counterfactual reasoning, temporal trajectories, heterogeneous effects, mechanistic decomposition, and joint interventions. We instantiate this paradigm in DoAtlas-1, compiling 1,445 effect kernels from 754 studies through effect standardization, conflict-aware graph construction, and real-world validation (Human Phenotype Project, 10,000 participants). The system achieves 98.5% canonicalization accuracy and 80.5% query executability. This paradigm shifts medical AI from text generation to executable, auditable, and verifiable causal reasoning.
Path-Guided Flow Matching for Dataset Distillation
Feb 05, 2026Dataset distillation compresses large datasets into compact synthetic sets with comparable performance in training models. Despite recent progress on diffusion-based distillation, this type of method typically depends on heuristic guidance or prototype assignment, which comes with time-consuming sampling and trajectory instability and thus hurts downstream generalization especially under strong control or low IPC. We propose \emph{Path-Guided Flow Matching (PGFM)}, the first flow matching-based framework for generative distillation, which enables fast deterministic synthesis by solving an ODE in a few steps. PGFM conducts flow matching in the latent space of a frozen VAE to learn class-conditional transport from Gaussian noise to data distribution. Particularly, we develop a continuous path-to-prototype guidance algorithm for ODE-consistent path control, which allows trajectories to reliably land on assigned prototypes while preserving diversity and efficiency. Extensive experiments across high-resolution benchmarks demonstrate that PGFM matches or surpasses prior diffusion-based distillation approaches with fewer steps of sampling while delivering competitive performance with remarkably improved efficiency, e.g., 7.6$\times$ more efficient than the diffusion-based counterparts with 78\% mode coverage.
Towards Robust Visual Continual Learning with Multi-Prototype Supervision
Sep 19, 2025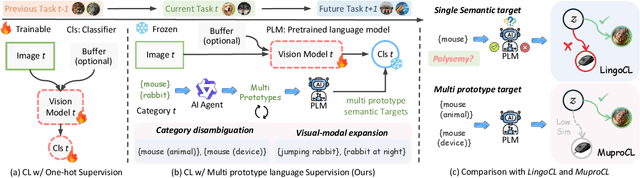
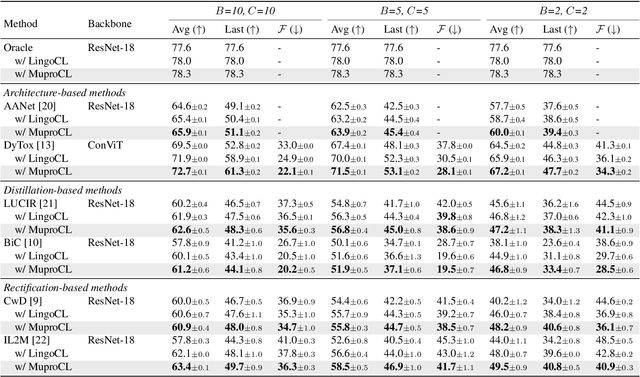
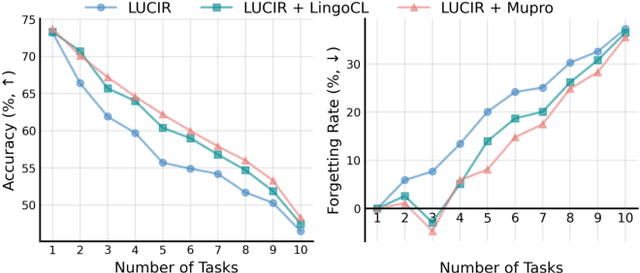
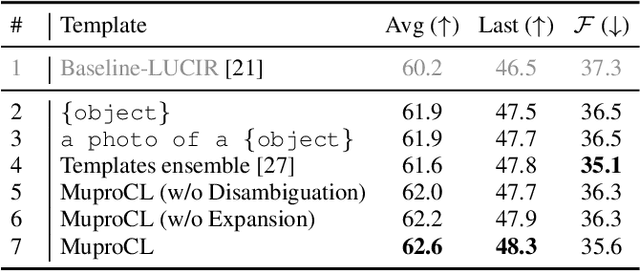
Language-guided supervision, which utilizes a frozen semantic target from a Pretrained Language Model (PLM), has emerged as a promising paradigm for visual Continual Learning (CL). However, relying on a single target introduces two critical limitations: 1) semantic ambiguity, where a polysemous category name results in conflicting visual representations, and 2) intra-class visual diversity, where a single prototype fails to capture the rich variety of visual appearances within a class. To this end, we propose MuproCL, a novel framework that replaces the single target with multiple, context-aware prototypes. Specifically, we employ a lightweight LLM agent to perform category disambiguation and visual-modal expansion to generate a robust set of semantic prototypes. A LogSumExp aggregation mechanism allows the vision model to adaptively align with the most relevant prototype for a given image. Extensive experiments across various CL baselines demonstrate that MuproCL consistently enhances performance and robustness, establishing a more effective path for language-guided continual learning.
SSS: Semi-Supervised SAM-2 with Efficient Prompting for Medical Imaging Segmentation
Jun 10, 2025In the era of information explosion, efficiently leveraging large-scale unlabeled data while minimizing the reliance on high-quality pixel-level annotations remains a critical challenge in the field of medical imaging. Semi-supervised learning (SSL) enhances the utilization of unlabeled data by facilitating knowledge transfer, significantly improving the performance of fully supervised models and emerging as a highly promising research direction in medical image analysis. Inspired by the ability of Vision Foundation Models (e.g., SAM-2) to provide rich prior knowledge, we propose SSS (Semi-Supervised SAM-2), a novel approach that leverages SAM-2's robust feature extraction capabilities to uncover latent knowledge in unlabeled medical images, thus effectively enhancing feature support for fully supervised medical image segmentation. Specifically, building upon the single-stream "weak-to-strong" consistency regularization framework, this paper introduces a Discriminative Feature Enhancement (DFE) mechanism to further explore the feature discrepancies introduced by various data augmentation strategies across multiple views. By leveraging feature similarity and dissimilarity across multi-scale augmentation techniques, the method reconstructs and models the features, thereby effectively optimizing the salient regions. Furthermore, a prompt generator is developed that integrates Physical Constraints with a Sliding Window (PCSW) mechanism to generate input prompts for unlabeled data, fulfilling SAM-2's requirement for additional prompts. Extensive experiments demonstrate the superiority of the proposed method for semi-supervised medical image segmentation on two multi-label datasets, i.e., ACDC and BHSD. Notably, SSS achieves an average Dice score of 53.15 on BHSD, surpassing the previous state-of-the-art method by +3.65 Dice. Code will be available at https://github.com/AIGeeksGroup/SSS.
J-Invariant Volume Shuffle for Self-Supervised Cryo-Electron Tomogram Denoising on Single Noisy Volume
Nov 22, 2024
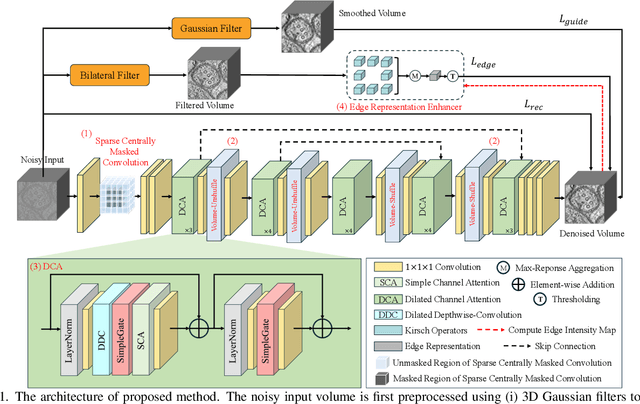


Cryo-Electron Tomography (Cryo-ET) enables detailed 3D visualization of cellular structures in near-native states but suffers from low signal-to-noise ratio due to imaging constraints. Traditional denoising methods and supervised learning approaches often struggle with complex noise patterns and the lack of paired datasets. Self-supervised methods, which utilize noisy input itself as a target, have been studied; however, existing Cryo-ET self-supervised denoising methods face significant challenges due to losing information during training and the learned incomplete noise patterns. In this paper, we propose a novel self-supervised learning model that denoises Cryo-ET volumetric images using a single noisy volume. Our method features a U-shape J-invariant blind spot network with sparse centrally masked convolutions, dilated channel attention blocks, and volume unshuffle/shuffle technique. The volume-unshuffle/shuffle technique expands receptive fields and utilizes multi-scale representations, significantly improving noise reduction and structural preservation. Experimental results demonstrate that our approach achieves superior performance compared to existing methods, advancing Cryo-ET data processing for structural biology research
FIAS: Feature Imbalance-Aware Medical Image Segmentation with Dynamic Fusion and Mixing Attention
Nov 16, 2024
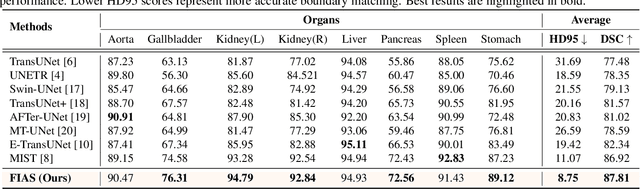

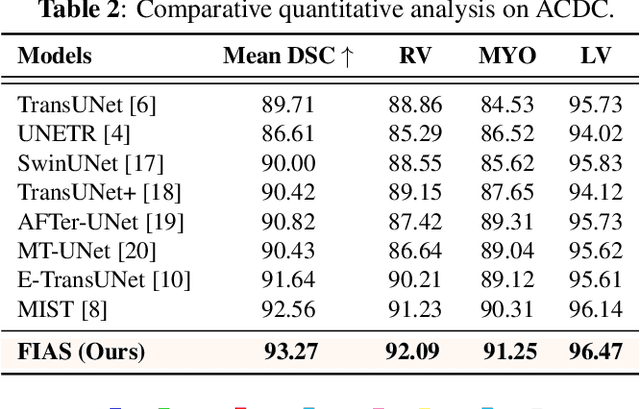
With the growing application of transformer in computer vision, hybrid architecture that combine convolutional neural networks (CNNs) and transformers demonstrates competitive ability in medical image segmentation. However, direct fusion of features from CNNs and transformers often leads to feature imbalance and redundant information. To address these issues, we propose a Feaure Imbalance-Aware Segmentation (FIAS) network, which incorporates a dual-path encoder and a novel Mixing Attention (MixAtt) decoder. The dual-branches encoder integrates a DilateFormer for long-range global feature extraction and a Depthwise Multi-Kernel (DMK) convolution for capturing fine-grained local details. A Context-Aware Fusion (CAF) block dynamically balances the contribution of these global and local features, preventing feature imbalance. The MixAtt decoder further enhances segmentation accuracy by combining self-attention and Monte Carlo attention, enabling the model to capture both small details and large-scale dependencies. Experimental results on the Synapse multi-organ and ACDC datasets demonstrate the strong competitiveness of our approach in medical image segmentation tasks.