 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Does Unfaithful Reasoning Emerge from Autoregressive Training? A Study of Synthetic Experiments
Feb 01, 2026Chain-of-thought (CoT) reasoning generated by large language models (LLMs) is often unfaithful: intermediate steps can be logically inconsistent or fail to reflect the causal relationship leading to the final answer. Despite extensive empirical observations, a fundamental understanding of CoT is lacking--what constitutes faithful CoT reasoning, and how unfaithfulness emerges from autoregressive training. We study these questions using well-controlled synthetic experiments, training small transformers on noisy data to solve modular arithmetic expressions step by step, a task we term Arithmetic Expression Reasoning. We find that models can learn faithful reasoning that causally follows the underlying arithmetic rules, but only when the training noise is below a critical threshold, a phenomenon attributable to simplicity bias. At higher noise levels, training dynamics exhibit a transition from faithful stepwise reasoning to unfaithful skip-step reasoning via an intermediate mixed mode characterized by a transient increase in prediction entropy. Mechanistic analysis reveals that models learn to encode internal uncertainty by resolving inconsistent reasoning steps, which suggests the emergence of implicit self-verification from autoregressive training.
Shattered Compositionality: Counterintuitive Learning Dynamics of Transformers for Arithmetic
Jan 30, 2026Large language models (LLMs) often exhibit unexpected errors or unintended behavior, even at scale. While recent work reveals the discrepancy between LLMs and humans in skill compositions, the learning dynamics of skill compositions and the underlying cause of non-human behavior remain elusive. In this study, we investigate the mechanism of learning dynamics by training transformers on synthetic arithmetic tasks. Through extensive ablations and fine-grained diagnostic metrics, we discover that transformers do not reliably build skill compositions according to human-like sequential rules. Instead, they often acquire skills in reverse order or in parallel, which leads to unexpected mixing errors especially under distribution shifts--a phenomenon we refer to as shattered compositionality. To explain these behaviors, we provide evidence that correlational matching to the training data, rather than causal or procedural composition, shapes learning dynamics. We further show that shattered compositionality persists in modern LLMs and is not mitigated by pure model scaling or scratchpad-based reasoning. Our results reveal a fundamental mismatch between a model's learning behavior and desired skill compositions, with implications for reasoning reliability, out-of-distribution robustness, and alignment.
Unifying Attention Heads and Task Vectors via Hidden State Geometry in In-Context Learning
May 24, 2025The unusual properties of in-context learning (ICL) have prompted investigations into the internal mechanisms of large language models. Prior work typically focuses on either special attention heads or task vectors at specific layers, but lacks a unified framework linking these components to the evolution of hidden states across layers that ultimately produce the model's output. In this paper, we propose such a framework for ICL in classification tasks by analyzing two geometric factors that govern performance: the separability and alignment of query hidden states. A fine-grained analysis of layer-wise dynamics reveals a striking two-stage mechanism: separability emerges in early layers, while alignment develops in later layers. Ablation studies further show that Previous Token Heads drive separability, while Induction Heads and task vectors enhance alignment. Our findings thus bridge the gap between attention heads and task vectors, offering a unified account of ICL's underlying mechanisms.
Assessing and improving reliability of neighbor embedding methods: a map-continuity perspective
Oct 22, 2024



Visualizing high-dimensional data is an important routine for understanding biomedical data and interpreting deep learning models. Neighbor embedding methods, such as t-SNE, UMAP, and LargeVis, among others, are a family of popular visualization methods which reduce high-dimensional data to two dimensions. However, recent studies suggest that these methods often produce visual artifacts, potentially leading to incorrect scientific conclusions. Recognizing that the current limitation stems from a lack of data-independent notions of embedding maps, we introduce a novel conceptual and computational framework, LOO-map, that learns the embedding maps based on a classical statistical idea known as the leave-one-out. LOO-map extends the embedding over a discrete set of input points to the entire input space, enabling a systematic assessment of map continuity, and thus the reliability of the visualizations. We find for many neighbor embedding methods, their embedding maps can be intrinsically discontinuous. The discontinuity induces two types of observed map distortion: ``overconfidence-inducing discontinuity," which exaggerates cluster separation, and ``fracture-inducing discontinuity," which creates spurious local structures. Building upon LOO-map, we propose two diagnostic point-wise scores -- perturbation score and singularity score -- to address these limitations. These scores can help identify unreliable embedding points, detect out-of-distribution data, and guide hyperparameter selection. Our approach is flexible and works as a wrapper around many neighbor embedding algorithms. We test our methods across multiple real-world datasets from computer vision and single-cell omics to demonstrate their effectiveness in enhancing the interpretability and accuracy of visualizations.
How does Multi-Task Training Affect Transformer In-Context Capabilities? Investigations with Function Classes
Apr 04, 2024Large language models (LLM) have recently shown the extraordinary ability to perform unseen tasks based on few-shot examples provided as text, also known as in-context learning (ICL). While recent works have attempted to understand the mechanisms driving ICL, few have explored training strategies that incentivize these models to generalize to multiple tasks. Multi-task learning (MTL) for generalist models is a promising direction that offers transfer learning potential, enabling large parameterized models to be trained from simpler, related tasks. In this work, we investigate the combination of MTL with ICL to build models that efficiently learn tasks while being robust to out-of-distribution examples. We propose several effective curriculum learning strategies that allow ICL models to achieve higher data efficiency and more stable convergence. Our experiments reveal that ICL models can effectively learn difficult tasks by training on progressively harder tasks while mixing in prior tasks, denoted as mixed curriculum in this work. Our code and models are available at https://github.com/harmonbhasin/curriculum_learning_icl .
Uncovering hidden geometry in Transformers via disentangling position and context
Oct 07, 2023



Transformers are widely used to extract complex semantic meanings from input tokens, yet they usually operate as black-box models. In this paper, we present a simple yet informative decomposition of hidden states (or embeddings) of trained transformers into interpretable components. For any layer, embedding vectors of input sequence samples are represented by a tensor $\boldsymbol{h} \in \mathbb{R}^{C \times T \times d}$. Given embedding vector $\boldsymbol{h}_{c,t} \in \mathbb{R}^d$ at sequence position $t \le T$ in a sequence (or context) $c \le C$, extracting the mean effects yields the decomposition \[ \boldsymbol{h}_{c,t} = \boldsymbol{\mu} + \mathbf{pos}_t + \mathbf{ctx}_c + \mathbf{resid}_{c,t} \] where $\boldsymbol{\mu}$ is the global mean vector, $\mathbf{pos}_t$ and $\mathbf{ctx}_c$ are the mean vectors across contexts and across positions respectively, and $\mathbf{resid}_{c,t}$ is the residual vector. For popular transformer architectures and diverse text datasets, empirically we find pervasive mathematical structure: (1) $(\mathbf{pos}_t)_{t}$ forms a low-dimensional, continuous, and often spiral shape across layers, (2) $(\mathbf{ctx}_c)_c$ shows clear cluster structure that falls into context topics, and (3) $(\mathbf{pos}_t)_{t}$ and $(\mathbf{ctx}_c)_c$ are mutually incoherent -- namely $\mathbf{pos}_t$ is almost orthogonal to $\mathbf{ctx}_c$ -- which is canonical in compressed sensing and dictionary learning. This decomposition offers structural insights about input formats in in-context learning (especially for induction heads) and in arithmetic tasks.
Unraveling Projection Heads in Contrastive Learning: Insights from Expansion and Shrinkage
Jun 06, 2023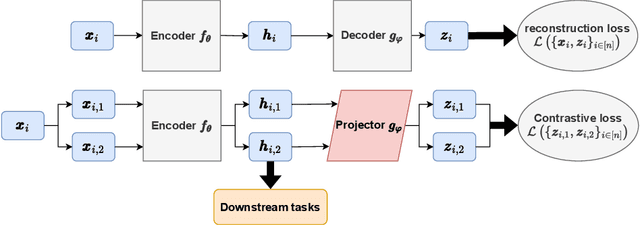

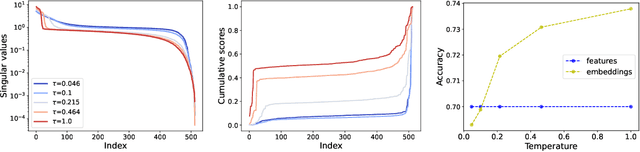
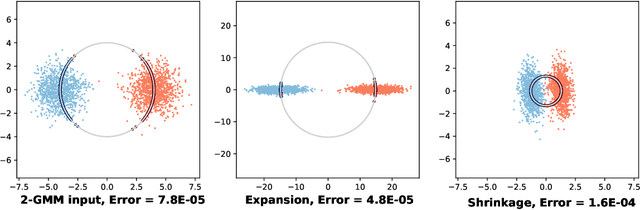
We investigate the role of projection heads, also known as projectors, within the encoder-projector framework (e.g., SimCLR) used in contrastive learning. We aim to demystify the observed phenomenon where representations learned before projectors outperform those learned after -- measured using the downstream linear classification accuracy, even when the projectors themselves are linear. In this paper, we make two significant contributions towards this aim. Firstly, through empirical and theoretical analysis, we identify two crucial effects -- expansion and shrinkage -- induced by the contrastive loss on the projectors. In essence, contrastive loss either expands or shrinks the signal direction in the representations learned by an encoder, depending on factors such as the augmentation strength, the temperature used in contrastive loss, etc. Secondly, drawing inspiration from the expansion and shrinkage phenomenon, we propose a family of linear transformations to accurately model the projector's behavior. This enables us to precisely characterize the downstream linear classification accuracy in the high-dimensional asymptotic limit. Our findings reveal that linear projectors operating in the shrinkage (or expansion) regime hinder (or improve) the downstream classification accuracy. This provides the first theoretical explanation as to why (linear) projectors impact the downstream performance of learned representations. Our theoretical findings are further corroborated by extensive experiments on both synthetic data and real image data.
Tractability from overparametrization: The example of the negative perceptron
Oct 28, 2021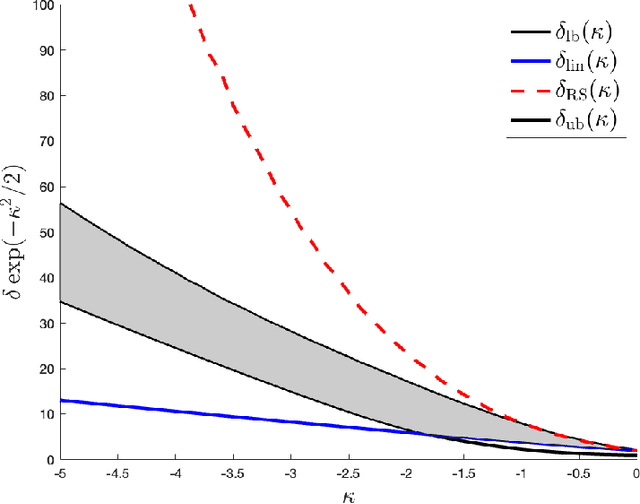
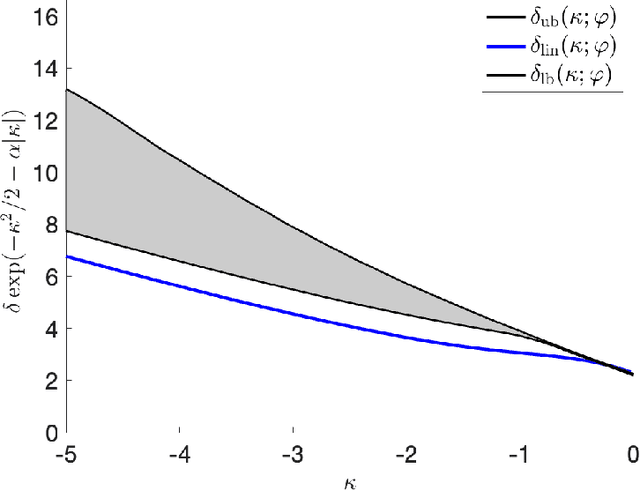
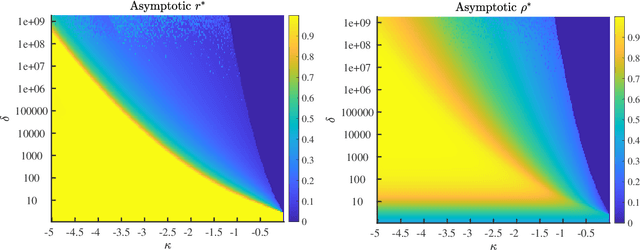
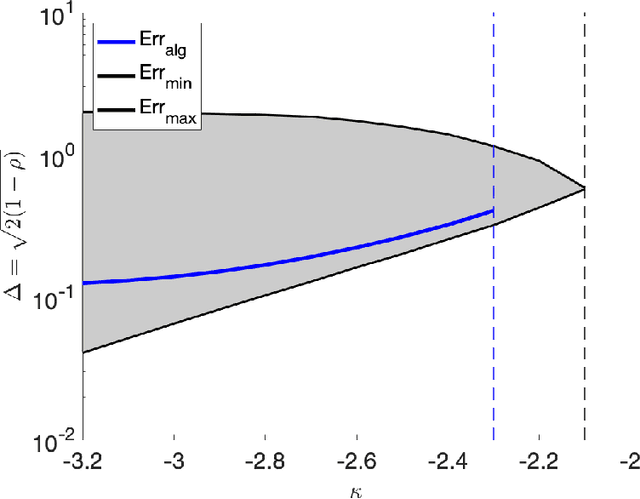
In the negative perceptron problem we are given $n$ data points $({\boldsymbol x}_i,y_i)$, where ${\boldsymbol x}_i$ is a $d$-dimensional vector and $y_i\in\{+1,-1\}$ is a binary label. The data are not linearly separable and hence we content ourselves to find a linear classifier with the largest possible \emph{negative} margin. In other words, we want to find a unit norm vector ${\boldsymbol \theta}$ that maximizes $\min_{i\le n}y_i\langle {\boldsymbol \theta},{\boldsymbol x}_i\rangle$. This is a non-convex optimization problem (it is equivalent to finding a maximum norm vector in a polytope), and we study its typical properties under two random models for the data. We consider the proportional asymptotics in which $n,d\to \infty$ with $n/d\to\delta$, and prove upper and lower bounds on the maximum margin $\kappa_{\text{s}}(\delta)$ or -- equivalently -- on its inverse function $\delta_{\text{s}}(\kappa)$. In other words, $\delta_{\text{s}}(\kappa)$ is the overparametrization threshold: for $n/d\le \delta_{\text{s}}(\kappa)-\varepsilon$ a classifier achieving vanishing training error exists with high probability, while for $n/d\ge \delta_{\text{s}}(\kappa)+\varepsilon$ it does not. Our bounds on $\delta_{\text{s}}(\kappa)$ match to the leading order as $\kappa\to -\infty$. We then analyze a linear programming algorithm to find a solution, and characterize the corresponding threshold $\delta_{\text{lin}}(\kappa)$. We observe a gap between the interpolation threshold $\delta_{\text{s}}(\kappa)$ and the linear programming threshold $\delta_{\text{lin}}(\kappa)$, raising the question of the behavior of other algorithms.
The Interpolation Phase Transition in Neural Networks: Memorization and Generalization under Lazy Training
Jul 25, 2020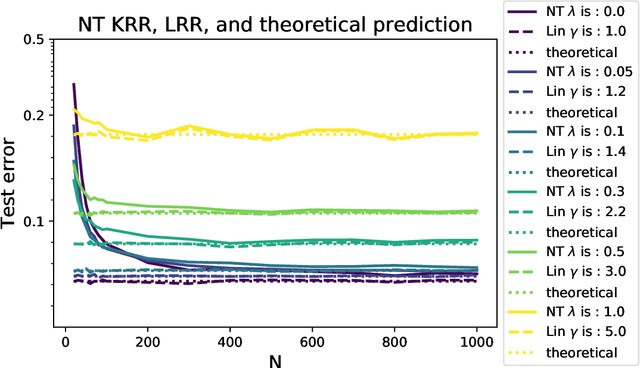
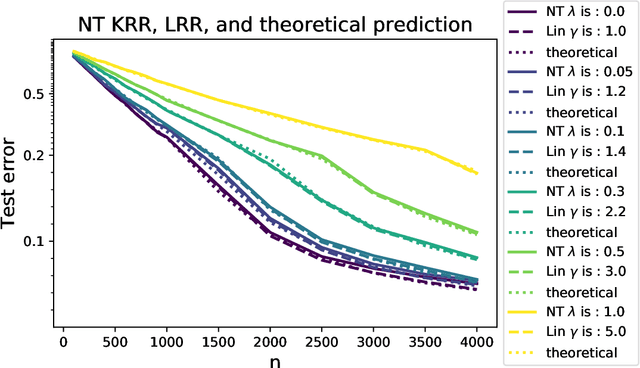
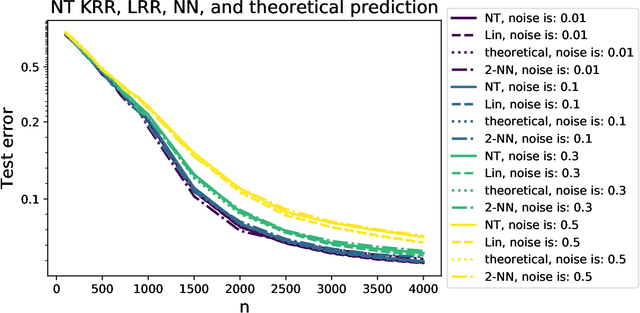

Modern neural networks are often operated in a strongly overparametrized regime: they comprise so many parameters that they can interpolate the training set, even if actual labels are replaced by purely random ones. Despite this, they achieve good prediction error on unseen data: interpolating the training set does not induce overfitting. Further, overparametrization appears to be beneficial in that it simplifies the optimization landscape. Here we study these phenomena in the context of two-layers neural networks in the neural tangent (NT) regime. We consider a simple data model, with isotropic feature vectors in $d$ dimensions, and $N$ hidden neurons. Under the assumption $N \le Cd$ (for $C$ a constant), we show that the network can exactly interpolate the data as soon as the number of parameters is significantly larger than the number of samples: $Nd\gg n$. Under these assumptions, we show that the empirical NT kernel has minimum eigenvalue bounded away from zero, and characterize the generalization error of min-$\ell_2$ norm interpolants, when the target function is linear. In particular, we show that the network approximately performs ridge regression in the raw features, with a strictly positive `self-induced' regularization.
A Selective Overview of Deep Learning
Apr 15, 2019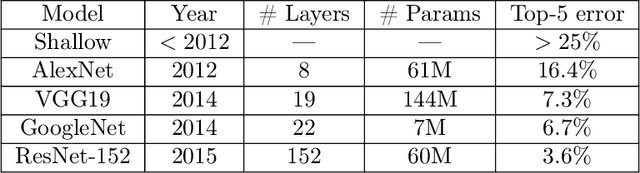

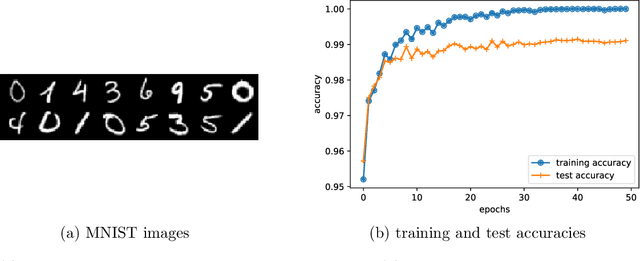
Deep learning has arguably achieved tremendous success in recent years. In simple words, deep learning uses the composition of many nonlinear functions to model the complex dependency between input features and labels. While neural networks have a long history, recent advances have greatly improved their performance in computer vision, natural language processing, etc. From the statistical and scientific perspective, it is natural to ask: What is deep learning? What are the new characteristics of deep learning, compared with classical methods? What are the theoretical foundations of deep learning? To answer these questions, we introduce common neural network models (e.g., convolutional neural nets, recurrent neural nets, generative adversarial nets) and training techniques (e.g., stochastic gradient descent, dropout, batch normalization) from a statistical point of view. Along the way, we highlight new characteristics of deep learning (including depth and over-parametrization) and explain their practical and theoretical benefits. We also sample recent results on theories of deep learning, many of which are only suggestive. While a complete understanding of deep learning remains elusive, we hope that our perspectives and discussions serve as a stimulus for new statistical research.