 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTractability from overparametrization: The example of the negative perceptron
Paper and Code
Oct 28, 2021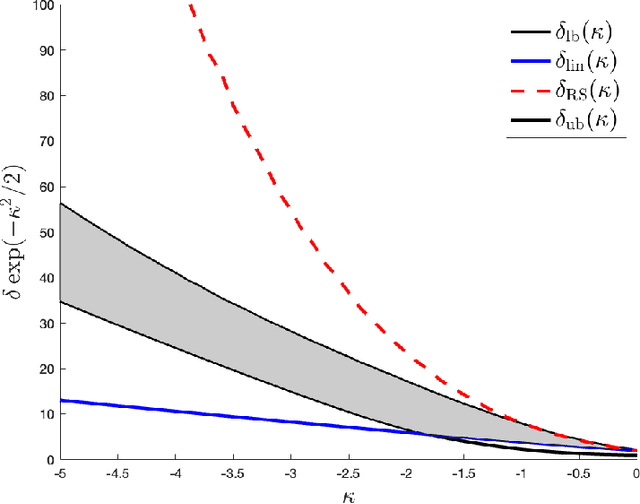
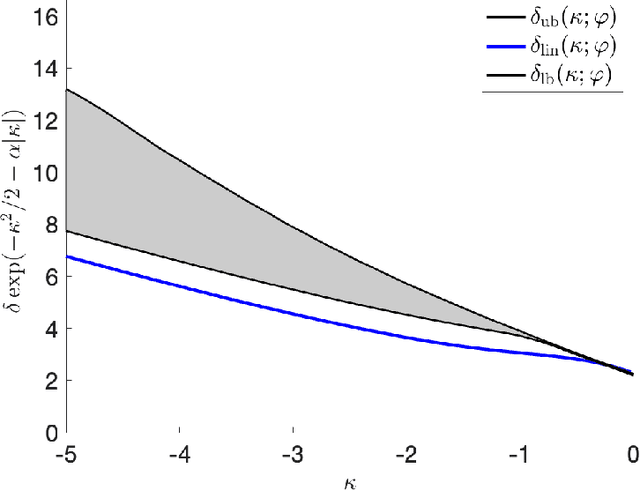
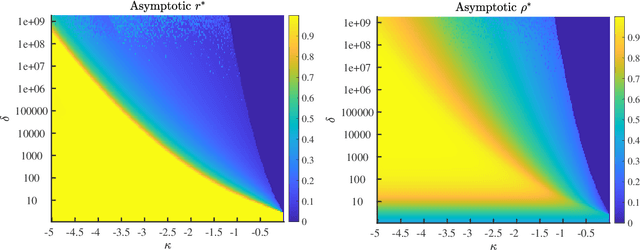
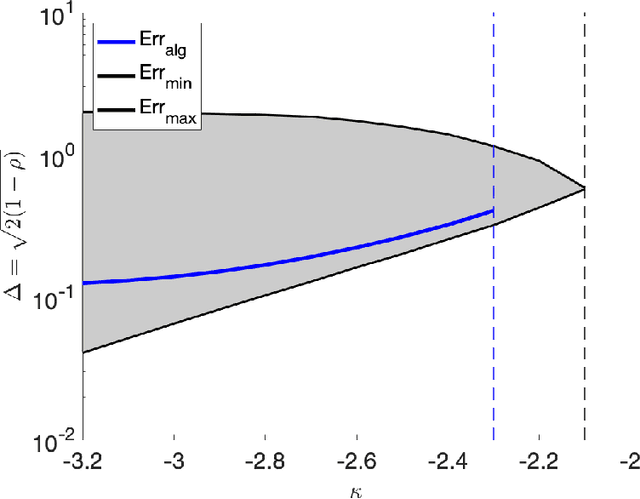
In the negative perceptron problem we are given $n$ data points $({\boldsymbol x}_i,y_i)$, where ${\boldsymbol x}_i$ is a $d$-dimensional vector and $y_i\in\{+1,-1\}$ is a binary label. The data are not linearly separable and hence we content ourselves to find a linear classifier with the largest possible \emph{negative} margin. In other words, we want to find a unit norm vector ${\boldsymbol \theta}$ that maximizes $\min_{i\le n}y_i\langle {\boldsymbol \theta},{\boldsymbol x}_i\rangle$. This is a non-convex optimization problem (it is equivalent to finding a maximum norm vector in a polytope), and we study its typical properties under two random models for the data. We consider the proportional asymptotics in which $n,d\to \infty$ with $n/d\to\delta$, and prove upper and lower bounds on the maximum margin $\kappa_{\text{s}}(\delta)$ or -- equivalently -- on its inverse function $\delta_{\text{s}}(\kappa)$. In other words, $\delta_{\text{s}}(\kappa)$ is the overparametrization threshold: for $n/d\le \delta_{\text{s}}(\kappa)-\varepsilon$ a classifier achieving vanishing training error exists with high probability, while for $n/d\ge \delta_{\text{s}}(\kappa)+\varepsilon$ it does not. Our bounds on $\delta_{\text{s}}(\kappa)$ match to the leading order as $\kappa\to -\infty$. We then analyze a linear programming algorithm to find a solution, and characterize the corresponding threshold $\delta_{\text{lin}}(\kappa)$. We observe a gap between the interpolation threshold $\delta_{\text{s}}(\kappa)$ and the linear programming threshold $\delta_{\text{lin}}(\kappa)$, raising the question of the behavior of other algorithms.