 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating from Discrete Distributions Using Diffusions: Insights from Random Constraint Satisfaction Problems
Mar 21, 2026Generating data from discrete distributions is important for a number of application domains including text, tabular data, and genomic data. Several groups have recently used random $k$-satisfiability ($k$-SAT) as a synthetic benchmark for new generative techniques. In this paper, we show that fundamental insights from the theory of random constraint satisfaction problems have observable implications (sometime contradicting intuition) on the behavior of generative techniques on such benchmarks. More precisely, we study the problem of generating a uniformly random solution of a given (random) $k$-SAT or $k$-XORSAT formula. Among other findings, we observe that: $(i)$~Continuous diffusions outperform masked discrete diffusions; $(ii)$~Learned diffusions can match the theoretical `ideal' accuracy; $(iii)$~Smart ordering of the variables can significantly improve accuracy, although not following popular heuristics.
Phase Transitions for Feature Learning in Neural Networks
Feb 01, 2026According to a popular viewpoint, neural networks learn from data by first identifying low-dimensional representations, and subsequently fitting the best model in this space. Recent works provide a formalization of this phenomenon when learning multi-index models. In this setting, we are given $n$ i.i.d. pairs $({\boldsymbol x}_i,y_i)$, where the covariate vectors ${\boldsymbol x}_i\in\mathbb{R}^d$ are isotropic, and responses $y_i$ only depend on ${\boldsymbol x}_i$ through a $k$-dimensional projection ${\boldsymbol Θ}_*^{\sf T}{\boldsymbol x}_i$. Feature learning amounts to learning the latent space spanned by ${\boldsymbol Θ}_*$. In this context, we study the gradient descent dynamics of two-layer neural networks under the proportional asymptotics $n,d\to\infty$, $n/d\toδ$, while the dimension of the latent space $k$ and the number of hidden neurons $m$ are kept fixed. Earlier work establishes that feature learning via polynomial-time algorithms is possible if $δ> δ_{\text{alg}}$, for $δ_{\text{alg}}$ a threshold depending on the data distribution, and is impossible (within a certain class of algorithms) below $δ_{\text{alg}}$. Here we derive an analogous threshold $δ_{\text{NN}}$ for two-layer networks. Our characterization of $δ_{\text{NN}}$ opens the way to study the dependence of learning dynamics on the network architecture and training algorithm. The threshold $δ_{\text{NN}}$ is determined by the following scenario. Training first visits points for which the gradient of the empirical risk is large and learns the directions spanned by these gradients. Then the gradient becomes smaller and the dynamics becomes dominated by negative directions of the Hessian. The threshold $δ_{\text{NN}}$ corresponds to a phase transition in the spectrum of the Hessian in this second phase.
Computational bottlenecks for denoising diffusions
Mar 11, 2025Denoising diffusions provide a general strategy to sample from a probability distribution $\mu$ in $\mathbb{R}^d$ by constructing a stochastic process $(\hat{\boldsymbol x}_t:t\ge 0)$ in ${\mathbb R}^d$ such that the distribution of $\hat{\boldsymbol x}_T$ at large times $T$ approximates $\mu$. The drift ${\boldsymbol m}:{\mathbb R}^d\times{\mathbb R}\to{\mathbb R}^d$ of this diffusion process is learned from data (samples from $\mu$) by minimizing the so-called score-matching objective. In order for the generating process to be efficient, it must be possible to evaluate (an approximation of) ${\boldsymbol m}({\boldsymbol y},t)$ in polynomial time. Is every probability distribution $\mu$, for which sampling is tractable, also amenable to sampling via diffusions? We provide evidence to the contrary by constructing a probability distribution $\mu$ for which sampling is easy, but the drift of the diffusion process is intractable -- under a popular conjecture on information-computation gaps in statistical estimation. We further show that any polynomial-time computable drift can be modified in a way that changes minimally the score matching objective and yet results in incorrect sampling.
Dynamical Decoupling of Generalization and Overfitting in Large Two-Layer Networks
Feb 28, 2025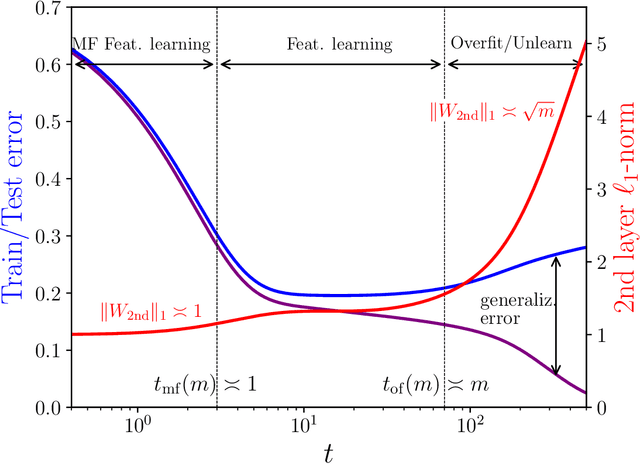
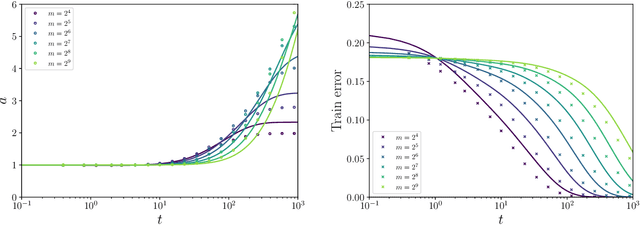
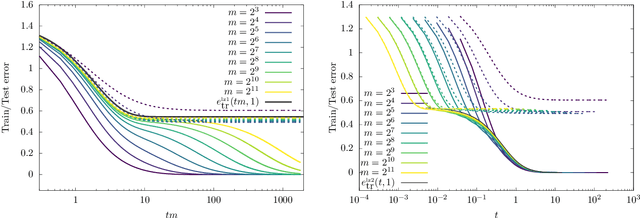
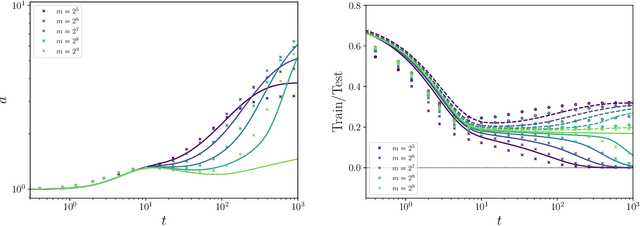
The inductive bias and generalization properties of large machine learning models are -- to a substantial extent -- a byproduct of the optimization algorithm used for training. Among others, the scale of the random initialization, the learning rate, and early stopping all have crucial impact on the quality of the model learnt by stochastic gradient descent or related algorithms. In order to understand these phenomena, we study the training dynamics of large two-layer neural networks. We use a well-established technique from non-equilibrium statistical physics (dynamical mean field theory) to obtain an asymptotic high-dimensional characterization of this dynamics. This characterization applies to a Gaussian approximation of the hidden neurons non-linearity, and empirically captures well the behavior of actual neural network models. Our analysis uncovers several interesting new phenomena in the training dynamics: $(i)$ The emergence of a slow time scale associated with the growth in Gaussian/Rademacher complexity; $(ii)$ As a consequence, algorithmic inductive bias towards small complexity, but only if the initialization has small enough complexity; $(iii)$ A separation of time scales between feature learning and overfitting; $(iv)$ A non-monotone behavior of the test error and, correspondingly, a `feature unlearning' phase at large times.
Local minima of the empirical risk in high dimension: General theorems and convex examples
Feb 04, 2025We consider a general model for high-dimensional empirical risk minimization whereby the data $\mathbf{x}_i$ are $d$-dimensional isotropic Gaussian vectors, the model is parametrized by $\mathbf{\Theta}\in\mathbb{R}^{d\times k}$, and the loss depends on the data via the projection $\mathbf{\Theta}^\mathsf{T}\mathbf{x}_i$. This setting covers as special cases classical statistics methods (e.g. multinomial regression and other generalized linear models), but also two-layer fully connected neural networks with $k$ hidden neurons. We use the Kac-Rice formula from Gaussian process theory to derive a bound on the expected number of local minima of this empirical risk, under the proportional asymptotics in which $n,d\to\infty$, with $n\asymp d$. Via Markov's inequality, this bound allows to determine the positions of these minimizers (with exponential deviation bounds) and hence derive sharp asymptotics on the estimation and prediction error. In this paper, we apply our characterization to convex losses, where high-dimensional asymptotics were not (in general) rigorously established for $k\ge 2$. We show that our approach is tight and allows to prove previously conjectured results. In addition, we characterize the spectrum of the Hessian at the minimizer. A companion paper applies our general result to non-convex examples.
High-dimensional logistic regression with missing data: Imputation, regularization, and universality
Oct 01, 2024We study high-dimensional, ridge-regularized logistic regression in a setting in which the covariates may be missing or corrupted by additive noise. When both the covariates and the additive corruptions are independent and normally distributed, we provide exact characterizations of both the prediction error as well as the estimation error. Moreover, we show that these characterizations are universal: as long as the entries of the data matrix satisfy a set of independence and moment conditions, our guarantees continue to hold. Universality, in turn, enables the detailed study of several imputation-based strategies when the covariates are missing completely at random. We ground our study by comparing the performance of these strategies with the conjectured performance -- stemming from replica theory in statistical physics -- of the Bayes optimal procedure. Our analysis yields several insights including: (i) a distinction between single imputation and a simple variant of multiple imputation and (ii) that adding a simple ridge regularization term to single-imputed logistic regression can yield an estimator whose prediction error is nearly indistinguishable from the Bayes optimal prediction error. We supplement our findings with extensive numerical experiments.
Scaling Training Data with Lossy Image Compression
Jul 25, 2024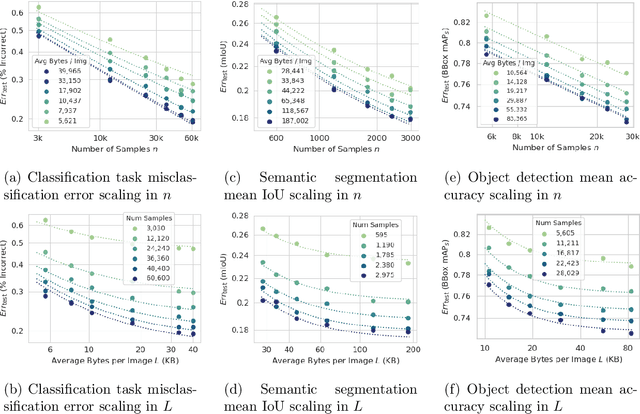



Empirically-determined scaling laws have been broadly successful in predicting the evolution of large machine learning models with training data and number of parameters. As a consequence, they have been useful for optimizing the allocation of limited resources, most notably compute time. In certain applications, storage space is an important constraint, and data format needs to be chosen carefully as a consequence. Computer vision is a prominent example: images are inherently analog, but are always stored in a digital format using a finite number of bits. Given a dataset of digital images, the number of bits $L$ to store each of them can be further reduced using lossy data compression. This, however, can degrade the quality of the model trained on such images, since each example has lower resolution. In order to capture this trade-off and optimize storage of training data, we propose a `storage scaling law' that describes the joint evolution of test error with sample size and number of bits per image. We prove that this law holds within a stylized model for image compression, and verify it empirically on two computer vision tasks, extracting the relevant parameters. We then show that this law can be used to optimize the lossy compression level. At given storage, models trained on optimally compressed images present a significantly smaller test error with respect to models trained on the original data. Finally, we investigate the potential benefits of randomizing the compression level.
Which exceptional low-dimensional projections of a Gaussian point cloud can be found in polynomial time?
Jun 05, 2024Given $d$-dimensional standard Gaussian vectors $\boldsymbol{x}_1,\dots, \boldsymbol{x}_n$, we consider the set of all empirical distributions of its $m$-dimensional projections, for $m$ a fixed constant. Diaconis and Freedman (1984) proved that, if $n/d\to \infty$, all such distributions converge to the standard Gaussian distribution. In contrast, we study the proportional asymptotics, whereby $n,d\to \infty$ with $n/d\to \alpha \in (0, \infty)$. In this case, the projection of the data points along a typical random subspace is again Gaussian, but the set $\mathscr{F}_{m,\alpha}$ of all probability distributions that are asymptotically feasible as $m$-dimensional projections contains non-Gaussian distributions corresponding to exceptional subspaces. Non-rigorous methods from statistical physics yield an indirect characterization of $\mathscr{F}_{m,\alpha}$ in terms of a generalized Parisi formula. Motivated by the goal of putting this formula on a rigorous basis, and to understand whether these projections can be found efficiently, we study the subset $\mathscr{F}^{\rm alg}_{m,\alpha}\subseteq \mathscr{F}_{m,\alpha}$ of distributions that can be realized by a class of iterative algorithms. We prove that this set is characterized by a certain stochastic optimal control problem, and obtain a dual characterization of this problem in terms of a variational principle that extends Parisi's formula. As a byproduct, we obtain computationally achievable values for a class of random optimization problems including `generalized spherical perceptron' models.
Scaling laws for learning with real and surrogate data
Feb 06, 2024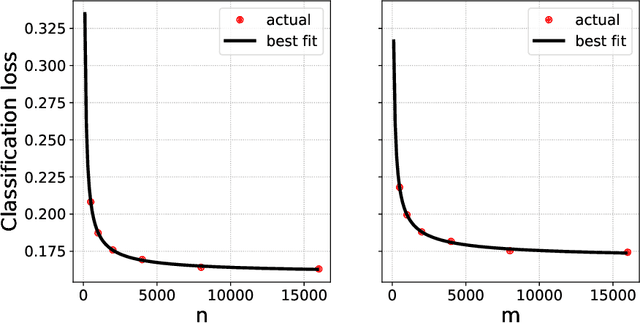
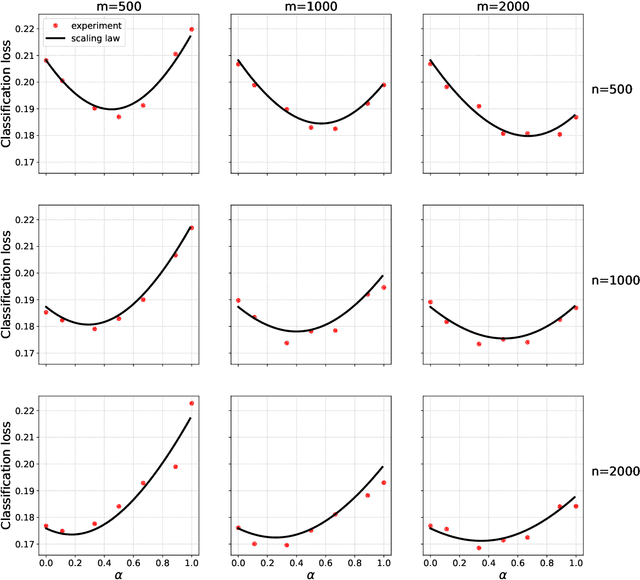
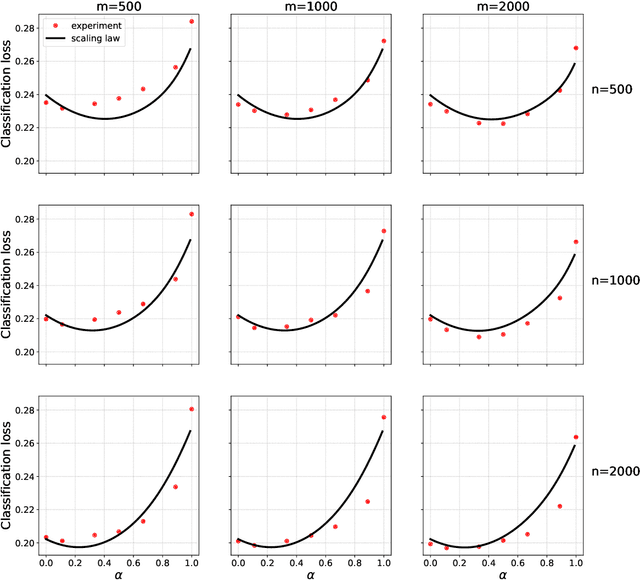
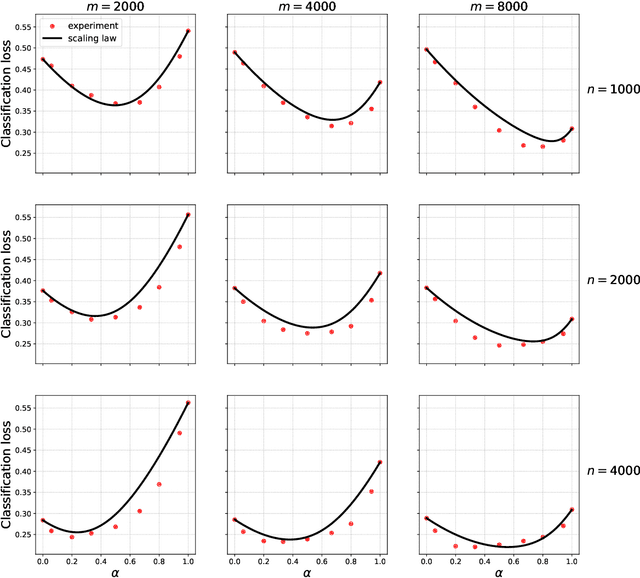
Collecting large quantities of high-quality data is often prohibitively expensive or impractical, and a crucial bottleneck in machine learning. One may instead augment a small set of $n$ data points from the target distribution with data from more accessible sources like public datasets, data collected under different circumstances, or synthesized by generative models. Blurring distinctions, we refer to such data as `surrogate data'. We define a simple scheme for integrating surrogate data into training and use both theoretical models and empirical studies to explore its behavior. Our main findings are: $(i)$ Integrating surrogate data can significantly reduce the test error on the original distribution; $(ii)$ In order to reap this benefit, it is crucial to use optimally weighted empirical risk minimization; $(iii)$ The test error of models trained on mixtures of real and surrogate data is well described by a scaling law. This can be used to predict the optimal weighting and the gain from surrogate data.
Universality of max-margin classifiers
Sep 29, 2023Maximum margin binary classification is one of the most fundamental algorithms in machine learning, yet the role of featurization maps and the high-dimensional asymptotics of the misclassification error for non-Gaussian features are still poorly understood. We consider settings in which we observe binary labels $y_i$ and either $d$-dimensional covariates ${\boldsymbol z}_i$ that are mapped to a $p$-dimension space via a randomized featurization map ${\boldsymbol \phi}:\mathbb{R}^d \to\mathbb{R}^p$, or $p$-dimensional features of non-Gaussian independent entries. In this context, we study two fundamental questions: $(i)$ At what overparametrization ratio $p/n$ do the data become linearly separable? $(ii)$ What is the generalization error of the max-margin classifier? Working in the high-dimensional regime in which the number of features $p$, the number of samples $n$ and the input dimension $d$ (in the nonlinear featurization setting) diverge, with ratios of order one, we prove a universality result establishing that the asymptotic behavior is completely determined by the expected covariance of feature vectors and by the covariance between features and labels. In particular, the overparametrization threshold and generalization error can be computed within a simpler Gaussian model. The main technical challenge lies in the fact that max-margin is not the maximizer (or minimizer) of an empirical average, but the maximizer of a minimum over the samples. We address this by representing the classifier as an average over support vectors. Crucially, we find that in high dimensions, the support vector count is proportional to the number of samples, which ultimately yields universality.