 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamical Decoupling of Generalization and Overfitting in Large Two-Layer Networks
Paper and Code
Feb 28, 2025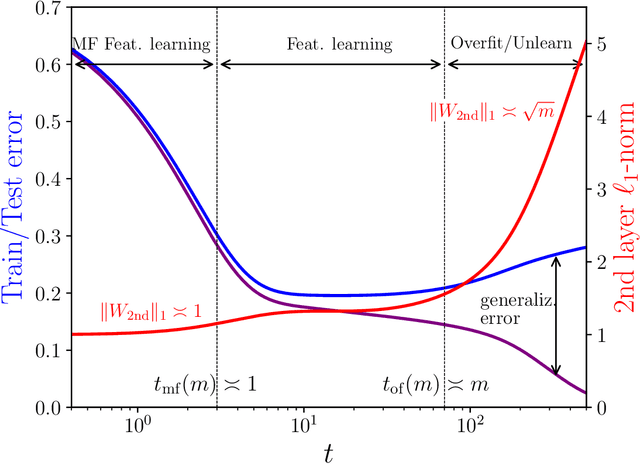
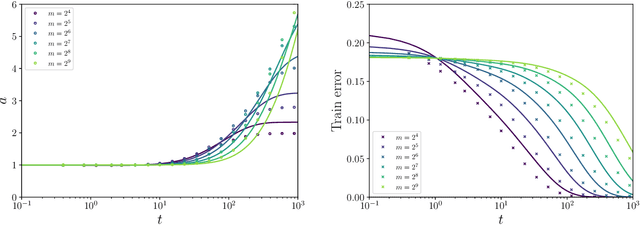
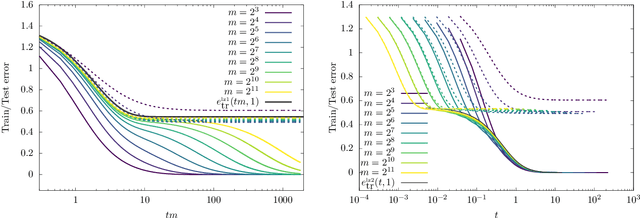
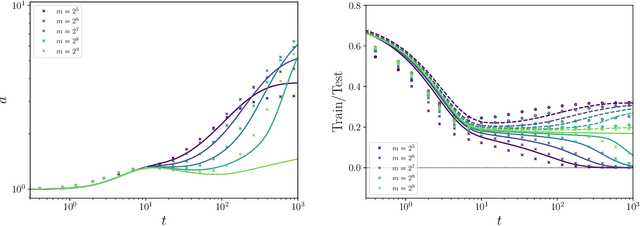
The inductive bias and generalization properties of large machine learning models are -- to a substantial extent -- a byproduct of the optimization algorithm used for training. Among others, the scale of the random initialization, the learning rate, and early stopping all have crucial impact on the quality of the model learnt by stochastic gradient descent or related algorithms. In order to understand these phenomena, we study the training dynamics of large two-layer neural networks. We use a well-established technique from non-equilibrium statistical physics (dynamical mean field theory) to obtain an asymptotic high-dimensional characterization of this dynamics. This characterization applies to a Gaussian approximation of the hidden neurons non-linearity, and empirically captures well the behavior of actual neural network models. Our analysis uncovers several interesting new phenomena in the training dynamics: $(i)$ The emergence of a slow time scale associated with the growth in Gaussian/Rademacher complexity; $(ii)$ As a consequence, algorithmic inductive bias towards small complexity, but only if the initialization has small enough complexity; $(iii)$ A separation of time scales between feature learning and overfitting; $(iv)$ A non-monotone behavior of the test error and, correspondingly, a `feature unlearning' phase at large times.