 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEBind: a practical approach to space binding
Nov 18, 2025We simplify space binding by focusing on two core components, a single encoder per modality and high-quality data; enabling training state-of-the-art models on a single GPU in a few hours as opposed to multiple days. We present EBind, an Easy, data-centric, and parameter-efficient method to Bind the embedding spaces of multiple contrastive models. We demonstrate that a simple 1.8B-parameter image-text-video-audio-3D model can outperform models 4 to 17x the size. The key to achieving this is a carefully curated dataset of three complementary data sources: i) 6.7M fully-automated multimodal quintuples sourced via SOTA retrieval models, ii) 1M diverse, semi-automated triples annotated by humans as negative, partial, or positive matches, and iii) 3.4M pre-existing captioned data items. We use 13 different evaluations to demonstrate the value of each data source. Due to limitations with existing benchmarks, we further introduce the first high-quality, consensus-annotated zero-shot classification benchmark between audio and PCs. In contrast to related work, we will open-source our code, model weights, and datasets.
Scaling laws for learning with real and surrogate data
Feb 06, 2024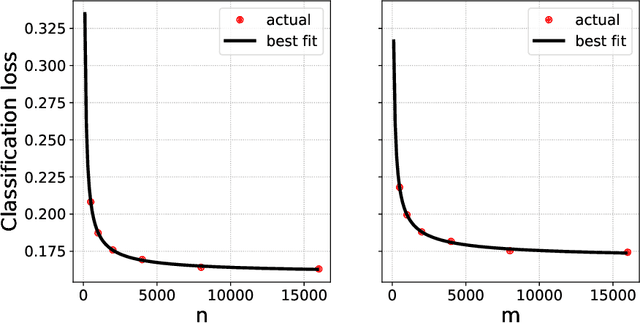
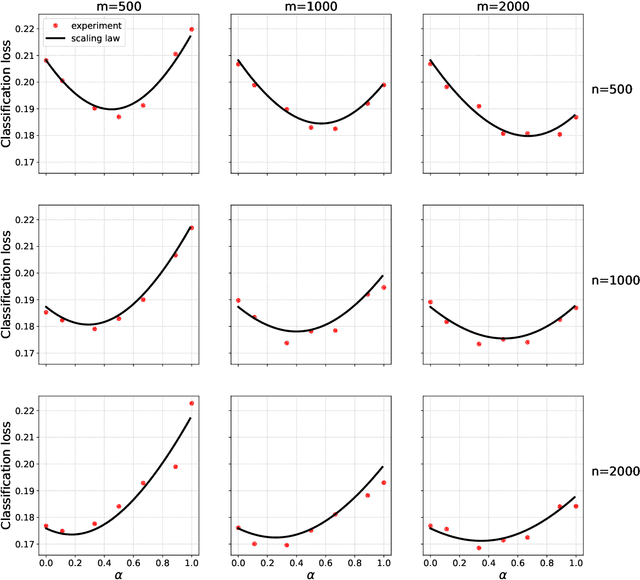
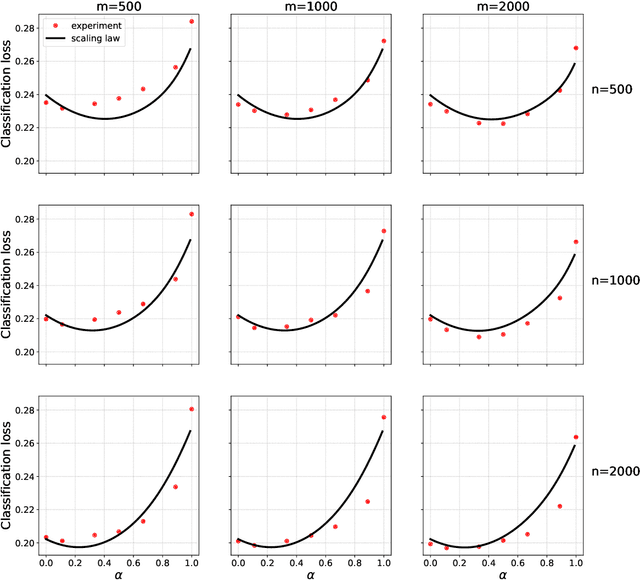
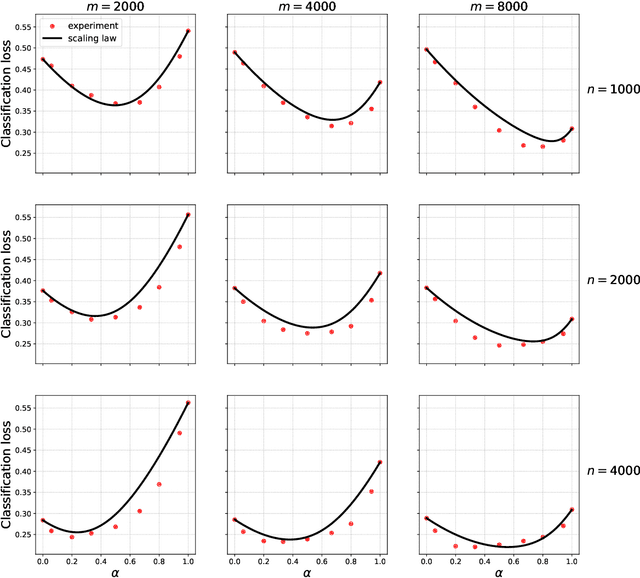
Collecting large quantities of high-quality data is often prohibitively expensive or impractical, and a crucial bottleneck in machine learning. One may instead augment a small set of $n$ data points from the target distribution with data from more accessible sources like public datasets, data collected under different circumstances, or synthesized by generative models. Blurring distinctions, we refer to such data as `surrogate data'. We define a simple scheme for integrating surrogate data into training and use both theoretical models and empirical studies to explore its behavior. Our main findings are: $(i)$ Integrating surrogate data can significantly reduce the test error on the original distribution; $(ii)$ In order to reap this benefit, it is crucial to use optimally weighted empirical risk minimization; $(iii)$ The test error of models trained on mixtures of real and surrogate data is well described by a scaling law. This can be used to predict the optimal weighting and the gain from surrogate data.