 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCredit Assignment with Resets in Language Model Reasoning
May 26, 2026Contemporary reinforcement learning with verifiable reward methods post-train language models on multi-step reasoning by assigning a single outcome reward uniformly across all tokens in a trajectory. Such uniform assignment ignores which steps contributed to success or failure. Improving credit assignment can address this limitation by enabling targeted refinement of faulty reasoning steps, rather than updating entire trajectories uniformly. Resets are one such simple mechanism, enabling more precise credit assignment by returning to an intermediate state and resampling counterfactual continuations, so that outcome differences can be attributed to decisions made at that point. We propose two such methods: Random-Reset Policy Optimization (RRPO), where reset states are drawn randomly from reasoning steps, and Self-Reset Policy Optimization (SRPO), where the model self-localizes the erroneous step in an incorrect trajectory and resets there. We analyze these methods within the Conservative Policy Iteration (CPI) framework. Extending CPI with a credit-assignment oracle that targets improvable states yields provable improvements over random resets. Across models and reasoning benchmarks, SRPO consistently outperforms standard GRPO and RRPO by sampling multiple suffix continuations at a self-localized reset and learning from their rewards, using only the model itself with no external supervision.
Evaluating the Utility of Personal Health Records in Personalized Health AI
May 18, 2026Patient-managed Personal Health Records (PHRs) promises to empower patients to better understand their health; but information in the record is complex, potentially hindering insights. In this study, we assess the potential of large language models (LLMs, Gemini 3.0 Flash) to provide helpful answers to user health queries, when provided clinical data from PHRs as context. A total of 2,257 user queries were drawn from 3 different distributions to represent patient questions: shorter web search queries, longer questions derived from templates of chatbot conversations, and questions patients asked to their healthcare team (patient calls). Queries were matched with de-identified PHRs (from a pool of 1,945). Gemini responses were generated (1) without PHR context; (2) with a basic summary of demographics, conditions, and medications; (3) with full, extensive clinical notes. For evaluation, we leveraged an existing rating framework (SHARP), and developed a new framework for specific error modes when interpreting PHRs. Evaluation was performed using autoraters for the full set, and with clinician ratings for a subset (n=95), with both sets of raters knowing the full PHR context. We see significant improvements in the helpfulness of answers to all question types with PHR data (p < 0.001, paired t-test). We also observe potential gains in safety, accuracy, relevance and personalization of answers. Our PHR evaluation framework further identifies gaps in LLM understanding of particular aspects of complex PHRs, such as temporal disorientation, and rare but meaningful confabulations. These results suggest potential for PHR data to help people with a wide range of user needs; and provide a framework for monitoring for gaps in LLM answers based on PHR context. This study motivates further work to assess and realize potential benefits to users from understanding their health records.
Pi-HOC: Pairwise 3D Human-Object Contact Estimation
Apr 14, 2026Resolving real-world human-object interactions in images is a many-to-many challenge, in which disentangling fine-grained concurrent physical contact is particularly difficult. Existing semantic contact estimation methods are either limited to single-human settings or require object geometries (e.g., meshes) in addition to the input image. Current state-of-the-art leverages powerful VLM for category-level semantics but struggles with multi-human scenarios and scales poorly in inference. We introduce Pi-HOC, a single-pass, instance-aware framework for dense 3D semantic contact prediction of all human-object pairs. Pi-HOC detects instances, creates dedicated human-object (HO) tokens for each pair, and refines them using an InteractionFormer. A SAM-based decoder then predicts dense contact on SMPL human meshes for each human-object pair. On the MMHOI and DAMON datasets, Pi-HOC significantly improves accuracy and localization over state-of-the-art methods while achieving 20x higher throughput. We further demonstrate that predicted contacts improve SAM-3D image-to-mesh reconstruction via a test-time optimization algorithm and enable referential contact prediction from language queries without additional training.
Structure Enables Effective Self-Localization of Errors in LLMs
Feb 02, 2026Self-correction in language models remains elusive. In this work, we explore whether language models can explicitly localize errors in incorrect reasoning, as a path toward building AI systems that can effectively correct themselves. We introduce a prompting method that structures reasoning as discrete, semantically coherent thought steps, and show that models are able to reliably localize errors within this structure, while failing to do so in conventional, unstructured chain-of-thought reasoning. Motivated by how the human brain monitors errors at discrete decision points and resamples alternatives, we introduce Iterative Correction Sampling of Thoughts (Thought-ICS), a self-correction framework. Thought-ICS iteratively prompts the model to generate reasoning one discrete and complete thought at a time--where each thought represents a deliberate decision by the model--creating natural boundaries for precise error localization. Upon verification, the model localizes the first erroneous step, and the system backtracks to generate alternative reasoning from the last correct point. When asked to correct reasoning verified as incorrect by an oracle, Thought-ICS achieves 20-40% self-correction lift. In a completely autonomous setting without external verification, it outperforms contemporary self-correction baselines.
Explainable AI in Big Data Fraud Detection
Dec 17, 2025Big Data has become central to modern applications in finance, insurance, and cybersecurity, enabling machine learning systems to perform large-scale risk assessments and fraud detection. However, the increasing dependence on automated analytics introduces important concerns about transparency, regulatory compliance, and trust. This paper examines how explainable artificial intelligence (XAI) can be integrated into Big Data analytics pipelines for fraud detection and risk management. We review key Big Data characteristics and survey major analytical tools, including distributed storage systems, streaming platforms, and advanced fraud detection models such as anomaly detectors, graph-based approaches, and ensemble classifiers. We also present a structured review of widely used XAI methods, including LIME, SHAP, counterfactual explanations, and attention mechanisms, and analyze their strengths and limitations when deployed at scale. Based on these findings, we identify key research gaps related to scalability, real-time processing, and explainability for graph and temporal models. To address these challenges, we outline a conceptual framework that integrates scalable Big Data infrastructure with context-aware explanation mechanisms and human feedback. The paper concludes with open research directions in scalable XAI, privacy-aware explanations, and standardized evaluation methods for explainable fraud detection systems.
Verification-Guided Context Optimization for Tool Calling via Hierarchical LLMs-as-Editors
Dec 15, 2025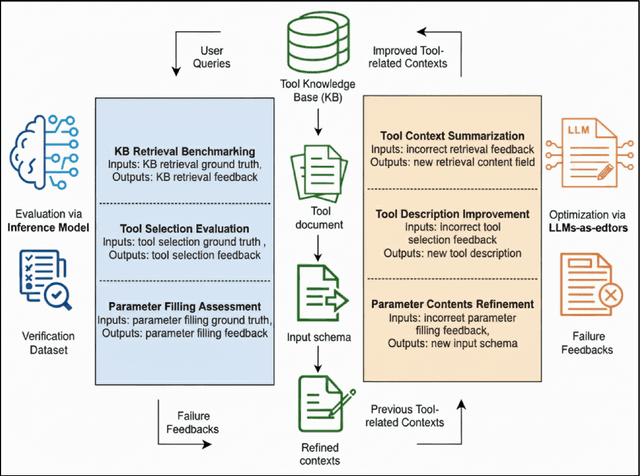
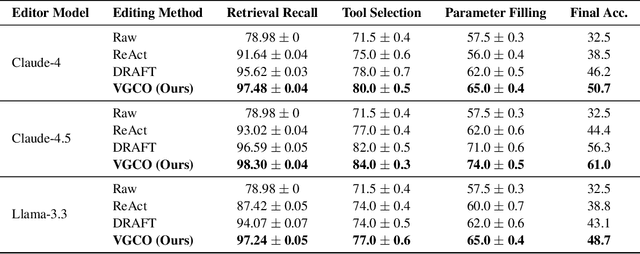
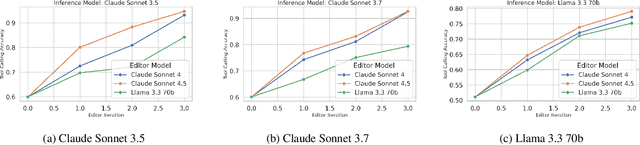
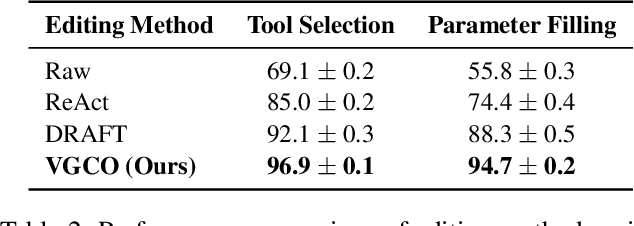
Tool calling enables large language models (LLMs) to interact with external environments through tool invocation, providing a practical way to overcome the limitations of pretraining. However, the effectiveness of tool use depends heavily on the quality of the associated documentation and knowledge base context. These materials are usually written for human users and are often misaligned with how LLMs interpret information. This problem is even more pronounced in industrial settings, where hundreds of tools with overlapping functionality create challenges in scalability, variability, and ambiguity. We propose Verification-Guided Context Optimization (VGCO), a framework that uses LLMs as editors to automatically refine tool-related documentation and knowledge base context. VGCO works in two stages. First, Evaluation collects real-world failure cases and identifies mismatches between tools and their context. Second, Optimization performs hierarchical editing through offline learning with structure-aware, in-context optimization. The novelty of our LLM editors has three main aspects. First, they use a hierarchical structure that naturally integrates into the tool-calling workflow. Second, they are state-aware, action-specific, and verification-guided, which constrains the search space and enables efficient, targeted improvements. Third, they enable cost-efficient sub-task specialization, either by prompt engineering large editor models or by post-training smaller editor models. Unlike prior work that emphasizes multi-turn reasoning, VGCO focuses on the single-turn, large-scale tool-calling problem and achieves significant improvements in accuracy, robustness, and generalization across LLMs.
Imbalanced Gradients in RL Post-Training of Multi-Task LLMs
Oct 22, 2025Multi-task post-training of large language models (LLMs) is typically performed by mixing datasets from different tasks and optimizing them jointly. This approach implicitly assumes that all tasks contribute gradients of similar magnitudes; when this assumption fails, optimization becomes biased toward large-gradient tasks. In this paper, however, we show that this assumption fails in RL post-training: certain tasks produce significantly larger gradients, thus biasing updates toward those tasks. Such gradient imbalance would be justified only if larger gradients implied larger learning gains on the tasks (i.e., larger performance improvements) -- but we find this is not true. Large-gradient tasks can achieve similar or even much lower learning gains than small-gradient ones. Further analyses reveal that these gradient imbalances cannot be explained by typical training statistics such as training rewards or advantages, suggesting that they arise from the inherent differences between tasks. This cautions against naive dataset mixing and calls for future work on principled gradient-level corrections for LLMs.
Actor-Free Continuous Control via Structurally Maximizable Q-Functions
Oct 21, 2025Value-based algorithms are a cornerstone of off-policy reinforcement learning due to their simplicity and training stability. However, their use has traditionally been restricted to discrete action spaces, as they rely on estimating Q-values for individual state-action pairs. In continuous action spaces, evaluating the Q-value over the entire action space becomes computationally infeasible. To address this, actor-critic methods are typically employed, where a critic is trained on off-policy data to estimate Q-values, and an actor is trained to maximize the critic's output. Despite their popularity, these methods often suffer from instability during training. In this work, we propose a purely value-based framework for continuous control that revisits structural maximization of Q-functions, introducing a set of key architectural and algorithmic choices to enable efficient and stable learning. We evaluate the proposed actor-free Q-learning approach on a range of standard simulation tasks, demonstrating performance and sample efficiency on par with state-of-the-art baselines, without the cost of learning a separate actor. Particularly, in environments with constrained action spaces, where the value functions are typically non-smooth, our method with structural maximization outperforms traditional actor-critic methods with gradient-based maximization. We have released our code at https://github.com/USC-Lira/Q3C.
Internalizing Self-Consistency in Language Models: Multi-Agent Consensus Alignment
Sep 18, 2025



Language Models (LMs) are inconsistent reasoners, often generating contradictory responses to identical prompts. While inference-time methods can mitigate these inconsistencies, they fail to address the core problem: LMs struggle to reliably select reasoning pathways leading to consistent outcomes under exploratory sampling. To address this, we formalize self-consistency as an intrinsic property of well-aligned reasoning models and introduce Multi-Agent Consensus Alignment (MACA), a reinforcement learning framework that post-trains models to favor reasoning trajectories aligned with their internal consensus using majority/minority outcomes from multi-agent debate. These trajectories emerge from deliberative exchanges where agents ground reasoning in peer arguments, not just aggregation of independent attempts, creating richer consensus signals than single-round majority voting. MACA enables agents to teach themselves to be more decisive and concise, and better leverage peer insights in multi-agent settings without external supervision, driving substantial improvements across self-consistency (+27.6% on GSM8K), single-agent reasoning (+23.7% on MATH), sampling-based inference (+22.4% Pass@20 on MATH), and multi-agent ensemble decision-making (+42.7% on MathQA). These findings, coupled with strong generalization to unseen benchmarks (+16.3% on GPQA, +11.6% on CommonsenseQA), demonstrate robust self-alignment that more reliably unlocks latent reasoning potential of language models.
Grounded Reinforcement Learning for Visual Reasoning
May 29, 2025
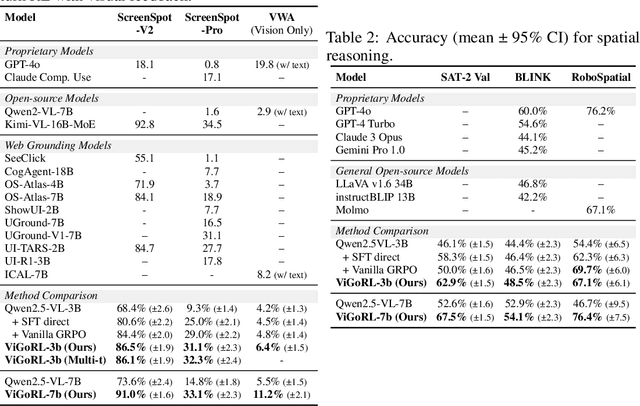
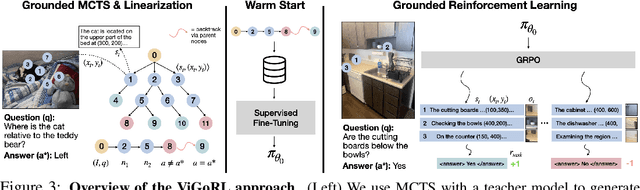

While reinforcement learning (RL) over chains of thought has significantly advanced language models in tasks such as mathematics and coding, visual reasoning introduces added complexity by requiring models to direct visual attention, interpret perceptual inputs, and ground abstract reasoning in spatial evidence. We introduce ViGoRL (Visually Grounded Reinforcement Learning), a vision-language model trained with RL to explicitly anchor each reasoning step to specific visual coordinates. Inspired by human visual decision-making, ViGoRL learns to produce spatially grounded reasoning traces, guiding visual attention to task-relevant regions at each step. When fine-grained exploration is required, our novel multi-turn RL framework enables the model to dynamically zoom into predicted coordinates as reasoning unfolds. Across a diverse set of visual reasoning benchmarks--including SAT-2 and BLINK for spatial reasoning, V*bench for visual search, and ScreenSpot and VisualWebArena for web-based grounding--ViGoRL consistently outperforms both supervised fine-tuning and conventional RL baselines that lack explicit grounding mechanisms. Incorporating multi-turn RL with zoomed-in visual feedback significantly improves ViGoRL's performance on localizing small GUI elements and visual search, achieving 86.4% on V*Bench. Additionally, we find that grounding amplifies other visual behaviors such as region exploration, grounded subgoal setting, and visual verification. Finally, human evaluations show that the model's visual references are not only spatially accurate but also helpful for understanding model reasoning steps. Our results show that visually grounded RL is a strong paradigm for imbuing models with general-purpose visual reasoning.