 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval Augmented Generation of Literature-derived Polymer Knowledge: The Example of a Biodegradable Polymer Expert System
Feb 18, 2026Polymer literature contains a large and growing body of experimental knowledge, yet much of it is buried in unstructured text and inconsistent terminology, making systematic retrieval and reasoning difficult. Existing tools typically extract narrow, study-specific facts in isolation, failing to preserve the cross-study context required to answer broader scientific questions. Retrieval-augmented generation (RAG) offers a promising way to overcome this limitation by combining large language models (LLMs) with external retrieval, but its effectiveness depends strongly on how domain knowledge is represented. In this work, we develop two retrieval pipelines: a dense semantic vector-based approach (VectorRAG) and a graph-based approach (GraphRAG). Using over 1,000 polyhydroxyalkanoate (PHA) papers, we construct context-preserving paragraph embeddings and a canonicalized structured knowledge graph supporting entity disambiguation and multi-hop reasoning. We evaluate these pipelines through standard retrieval metrics, comparisons with general state-of-the-art systems such as GPT and Gemini, and qualitative validation by a domain chemist. The results show that GraphRAG achieves higher precision and interpretability, while VectorRAG provides broader recall, highlighting complementary trade-offs. Expert validation further confirms that the tailored pipelines, particularly GraphRAG, produce well-grounded, citation-reliable responses with strong domain relevance. By grounding every statement in evidence, these systems enable researchers to navigate the literature, compare findings across studies, and uncover patterns that are difficult to extract manually. More broadly, this work establishes a practical framework for building materials science assistants using curated corpora and retrieval design, reducing reliance on proprietary models while enabling trustworthy literature analysis at scale.
MSQA: Benchmarking LLMs on Graduate-Level Materials Science Reasoning and Knowledge
May 29, 2025



Despite recent advances in large language models (LLMs) for materials science, there is a lack of benchmarks for evaluating their domain-specific knowledge and complex reasoning abilities. To bridge this gap, we introduce MSQA, a comprehensive evaluation benchmark of 1,757 graduate-level materials science questions in two formats: detailed explanatory responses and binary True/False assessments. MSQA distinctively challenges LLMs by requiring both precise factual knowledge and multi-step reasoning across seven materials science sub-fields, such as structure-property relationships, synthesis processes, and computational modeling. Through experiments with 10 state-of-the-art LLMs, we identify significant gaps in current LLM performance. While API-based proprietary LLMs achieve up to 84.5% accuracy, open-source (OSS) LLMs peak around 60.5%, and domain-specific LLMs often underperform significantly due to overfitting and distributional shifts. MSQA represents the first benchmark to jointly evaluate the factual and reasoning capabilities of LLMs crucial for LLMs in advanced materials science.
LLM-Augmented Chemical Synthesis and Design Decision Programs
May 11, 2025Retrosynthesis, the process of breaking down a target molecule into simpler precursors through a series of valid reactions, stands at the core of organic chemistry and drug development. Although recent machine learning (ML) research has advanced single-step retrosynthetic modeling and subsequent route searches, these solutions remain restricted by the extensive combinatorial space of possible pathways. Concurrently, large language models (LLMs) have exhibited remarkable chemical knowledge, hinting at their potential to tackle complex decision-making tasks in chemistry. In this work, we explore whether LLMs can successfully navigate the highly constrained, multi-step retrosynthesis planning problem. We introduce an efficient scheme for encoding reaction pathways and present a new route-level search strategy, moving beyond the conventional step-by-step reactant prediction. Through comprehensive evaluations, we show that our LLM-augmented approach excels at retrosynthesis planning and extends naturally to the broader challenge of synthesizable molecular design.
polyGen: A Learning Framework for Atomic-level Polymer Structure Generation
Apr 24, 2025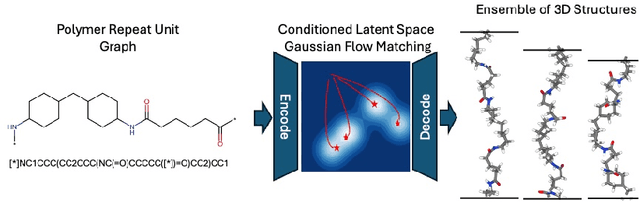
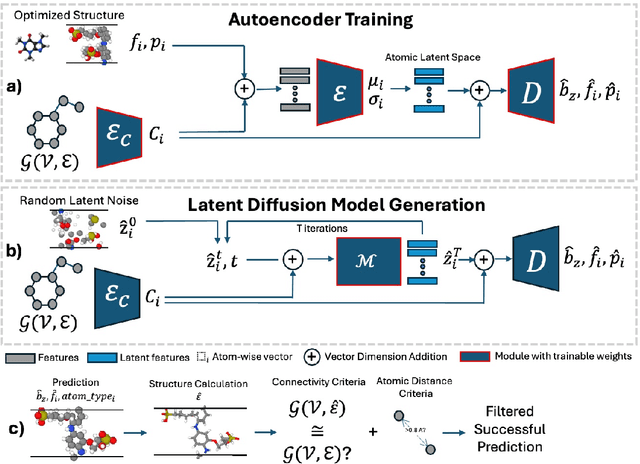
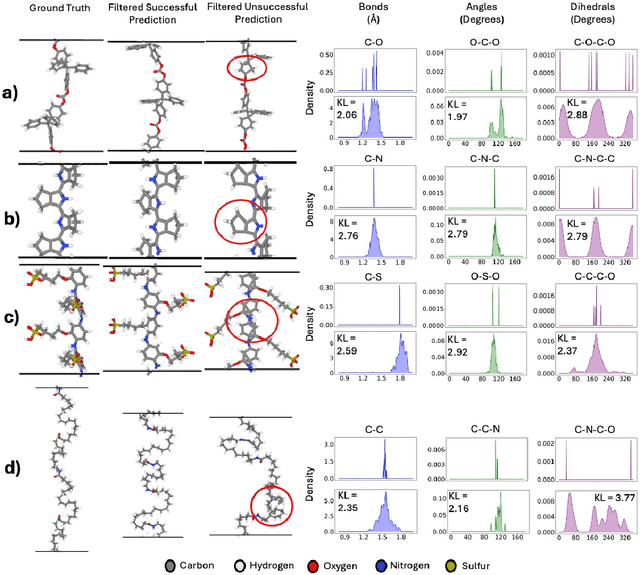

Synthetic polymeric materials underpin fundamental technologies in the energy, electronics, consumer goods, and medical sectors, yet their development still suffers from prolonged design timelines. Although polymer informatics tools have supported speedup, polymer simulation protocols continue to face significant challenges: on-demand generation of realistic 3D atomic structures that respect the conformational diversity of polymer structures. Generative algorithms for 3D structures of inorganic crystals, bio-polymers, and small molecules exist, but have not addressed synthetic polymers. In this work, we introduce polyGen, the first latent diffusion model designed specifically to generate realistic polymer structures from minimal inputs such as the repeat unit chemistry alone, leveraging a molecular encoding that captures polymer connectivity throughout the architecture. Due to a scarce dataset of only 3855 DFT-optimized polymer structures, we augment our training with DFT-optimized molecular structures, showing improvement in joint learning between similar chemical structures. We also establish structure matching criteria to benchmark our approach on this novel problem. polyGen effectively generates diverse conformations of both linear chains and complex branched structures, though its performance decreases when handling repeat units with a high atom count. Given these initial results, polyGen represents a paradigm shift in atomic-level structure generation for polymer science-the first proof-of-concept for predicting realistic atomic-level polymer conformations while accounting for their intrinsic structural flexibility.
Accelerating materials discovery for polymer solar cells: Data-driven insights enabled by natural language processing
Feb 29, 2024



We present a natural language processing pipeline that was used to extract polymer solar cell property data from the literature and simulate various active learning strategies. While data-driven methods have been well established to discover novel materials faster than Edisonian trial-and-error approaches, their benefits have not been quantified. Our approach demonstrates a potential reduction in discovery time by approximately 75 %, equivalent to a 15 year acceleration in material innovation. Our pipeline enables us to extract data from more than 3300 papers which is ~5 times larger than similar data sets reported by others. We also trained machine learning models to predict the power conversion efficiency and used our model to identify promising donor-acceptor combinations that are as yet unreported. We thus demonstrate a workflow that goes from published literature to extracted material property data which in turn is used to obtain data-driven insights. Our insights include active learning strategies that can simultaneously optimize the material system and train strong predictive models of material properties. This work provides a valuable framework for research in material science.
A Simple but Effective Approach to Improve Structured Language Model Output for Information Extraction
Feb 20, 2024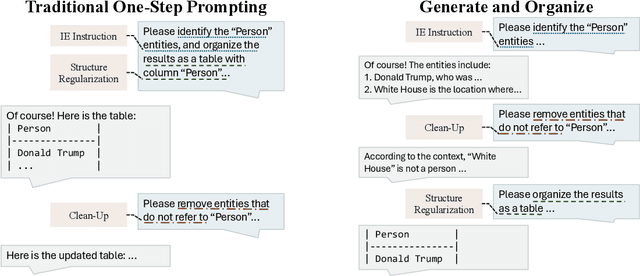
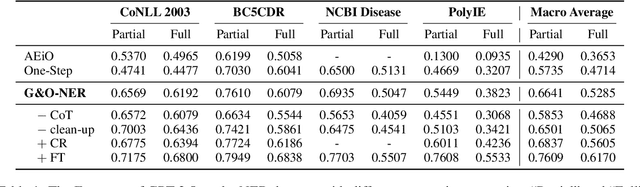


Large language models (LLMs) have demonstrated impressive abilities in generating unstructured natural language according to instructions. However, their performance can be inconsistent when tasked with producing text that adheres to specific structured formats, which is crucial in applications like named entity recognition (NER) or relation extraction (RE). To address this issue, this paper introduces an efficient method, G&O, to enhance their structured text generation capabilities. It breaks the generation into a two-step pipeline: initially, LLMs generate answers in natural language as intermediate responses. Subsequently, LLMs are asked to organize the output into the desired structure, using the intermediate responses as context. G&O effectively separates the generation of content from the structuring process, reducing the pressure of completing two orthogonal tasks simultaneously. Tested on zero-shot NER and RE, the results indicate a significant improvement in LLM performance with minimal additional efforts. This straightforward and adaptable prompting technique can also be combined with other strategies, like self-consistency, to further elevate LLM capabilities in various structured text generation tasks.
PolyIE: A Dataset of Information Extraction from Polymer Material Scientific Literature
Nov 13, 2023



Scientific information extraction (SciIE), which aims to automatically extract information from scientific literature, is becoming more important than ever. However, there are no existing SciIE datasets for polymer materials, which is an important class of materials used ubiquitously in our daily lives. To bridge this gap, we introduce POLYIE, a new SciIE dataset for polymer materials. POLYIE is curated from 146 full-length polymer scholarly articles, which are annotated with different named entities (i.e., materials, properties, values, conditions) as well as their N-ary relations by domain experts. POLYIE presents several unique challenges due to diverse lexical formats of entities, ambiguity between entities, and variable-length relations. We evaluate state-of-the-art named entity extraction and relation extraction models on POLYIE, analyze their strengths and weaknesses, and highlight some difficult cases for these models. To the best of our knowledge, POLYIE is the first SciIE benchmark for polymer materials, and we hope it will lead to more research efforts from the community on this challenging task. Our code and data are available on: https://github.com/jerry3027/PolyIE.
PolyGET: Accelerating Polymer Simulations by Accurate and Generalizable Forcefield with Equivariant Transformer
Sep 01, 2023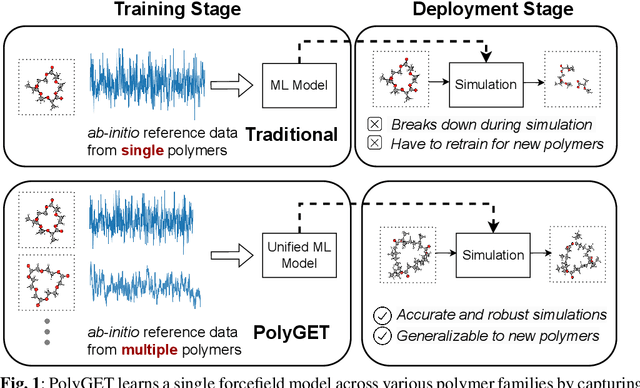
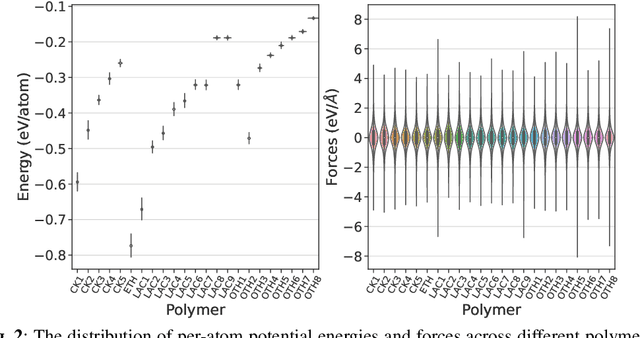
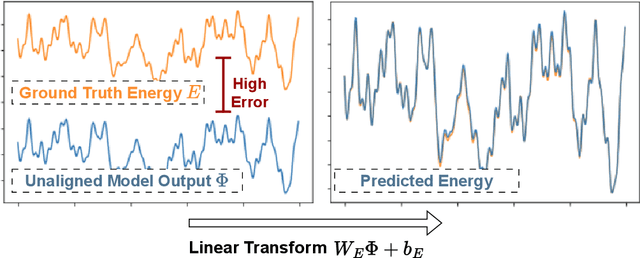
Polymer simulation with both accuracy and efficiency is a challenging task. Machine learning (ML) forcefields have been developed to achieve both the accuracy of ab initio methods and the efficiency of empirical force fields. However, existing ML force fields are usually limited to single-molecule settings, and their simulations are not robust enough. In this paper, we present PolyGET, a new framework for Polymer Forcefields with Generalizable Equivariant Transformers. PolyGET is designed to capture complex quantum interactions between atoms and generalize across various polymer families, using a deep learning model called Equivariant Transformers. We propose a new training paradigm that focuses exclusively on optimizing forces, which is different from existing methods that jointly optimize forces and energy. This simple force-centric objective function avoids competing objectives between energy and forces, thereby allowing for learning a unified forcefield ML model over different polymer families. We evaluated PolyGET on a large-scale dataset of 24 distinct polymer types and demonstrated state-of-the-art performance in force accuracy and robust MD simulations. Furthermore, PolyGET can simulate large polymers with high fidelity to the reference ab initio DFT method while being able to generalize to unseen polymers.
May the Force be with You: Unified Force-Centric Pre-Training for 3D Molecular Conformations
Aug 24, 2023Recent works have shown the promise of learning pre-trained models for 3D molecular representation. However, existing pre-training models focus predominantly on equilibrium data and largely overlook off-equilibrium conformations. It is challenging to extend these methods to off-equilibrium data because their training objective relies on assumptions of conformations being the local energy minima. We address this gap by proposing a force-centric pretraining model for 3D molecular conformations covering both equilibrium and off-equilibrium data. For off-equilibrium data, our model learns directly from their atomic forces. For equilibrium data, we introduce zero-force regularization and forced-based denoising techniques to approximate near-equilibrium forces. We obtain a unified pre-trained model for 3D molecular representation with over 15 million diverse conformations. Experiments show that, with our pre-training objective, we increase forces accuracy by around 3 times compared to the un-pre-trained Equivariant Transformer model. By incorporating regularizations on equilibrium data, we solved the problem of unstable MD simulations in vanilla Equivariant Transformers, achieving state-of-the-art simulation performance with 2.45 times faster inference time than NequIP. As a powerful molecular encoder, our pre-trained model achieves on-par performance with state-of-the-art property prediction tasks.
polyBERT: A chemical language model to enable fully machine-driven ultrafast polymer informatics
Sep 29, 2022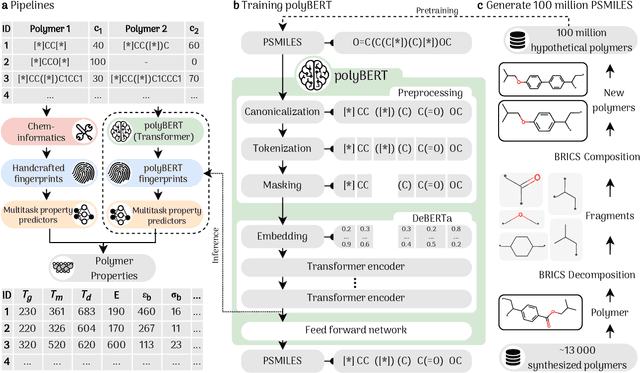
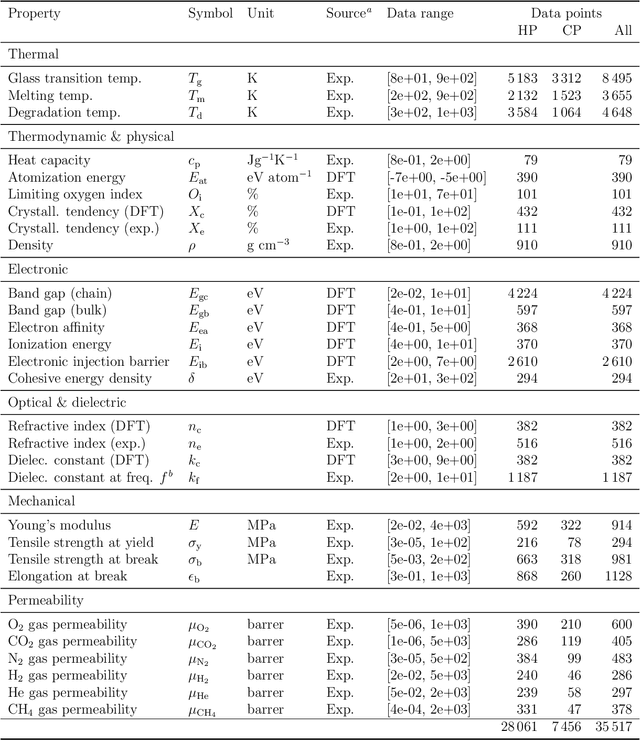
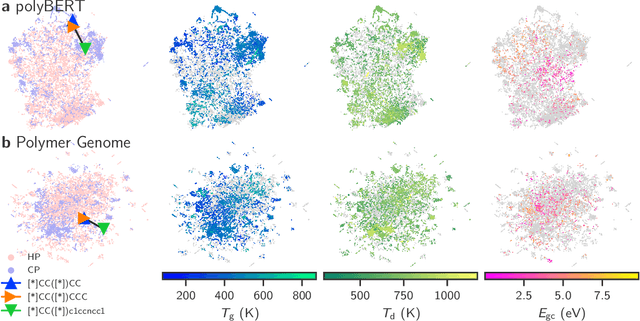
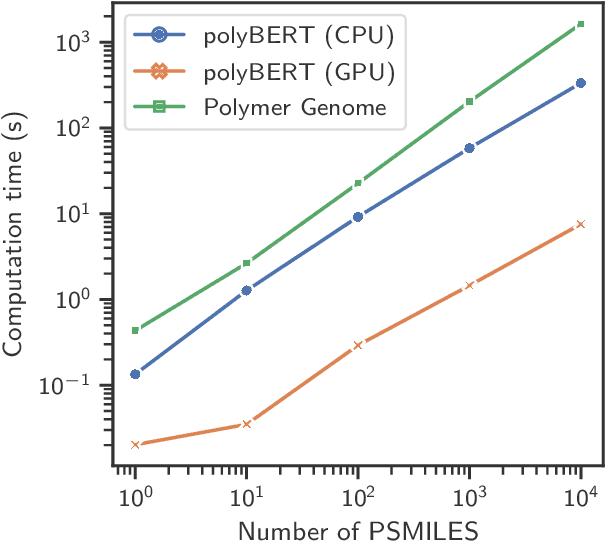
Polymers are a vital part of everyday life. Their chemical universe is so large that it presents unprecedented opportunities as well as significant challenges to identify suitable application-specific candidates. We present a complete end-to-end machine-driven polymer informatics pipeline that can search this space for suitable candidates at unprecedented speed and accuracy. This pipeline includes a polymer chemical fingerprinting capability called polyBERT (inspired by Natural Language Processing concepts), and a multitask learning approach that maps the polyBERT fingerprints to a host of properties. polyBERT is a chemical linguist that treats the chemical structure of polymers as a chemical language. The present approach outstrips the best presently available concepts for polymer property prediction based on handcrafted fingerprint schemes in speed by two orders of magnitude while preserving accuracy, thus making it a strong candidate for deployment in scalable architectures including cloud infrastructures.