 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLMR: Reinforcement Learning with Mixed Rewards for Creative Writing
Aug 28, 2025
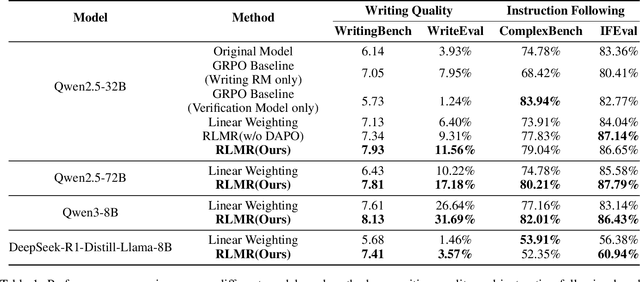
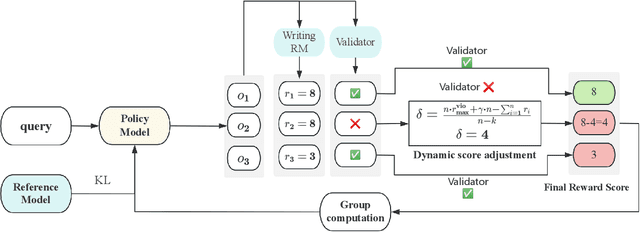
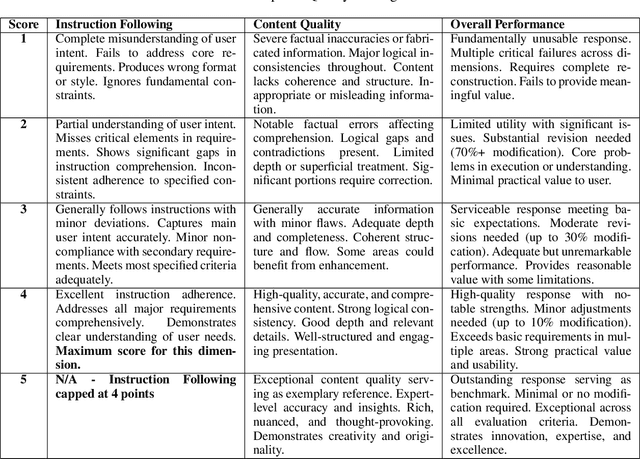
Large language models are extensively utilized in creative writing applications. Creative writing requires a balance between subjective writing quality (e.g., literariness and emotional expression) and objective constraint following (e.g., format requirements and word limits). Existing methods find it difficult to balance these two aspects: single reward strategies fail to improve both abilities simultaneously, while fixed-weight mixed-reward methods lack the ability to adapt to different writing scenarios. To address this problem, we propose Reinforcement Learning with Mixed Rewards (RLMR), utilizing a dynamically mixed reward system from a writing reward model evaluating subjective writing quality and a constraint verification model assessing objective constraint following. The constraint following reward weight is adjusted dynamically according to the writing quality within sampled groups, ensuring that samples violating constraints get negative advantage in GRPO and thus penalized during training, which is the key innovation of this proposed method. We conduct automated and manual evaluations across diverse model families from 8B to 72B parameters. Additionally, we construct a real-world writing benchmark named WriteEval for comprehensive evaluation. Results illustrate that our method achieves consistent improvements in both instruction following (IFEval from 83.36% to 86.65%) and writing quality (72.75% win rate in manual expert pairwise evaluations on WriteEval). To the best of our knowledge, RLMR is the first work to combine subjective preferences with objective verification in online RL training, providing an effective solution for multi-dimensional creative writing optimization.
$C^3$-Bench: The Things Real Disturbing LLM based Agent in Multi-Tasking
May 24, 2025Agents based on large language models leverage tools to modify environments, revolutionizing how AI interacts with the physical world. Unlike traditional NLP tasks that rely solely on historical dialogue for responses, these agents must consider more complex factors, such as inter-tool relationships, environmental feedback and previous decisions, when making choices. Current research typically evaluates agents via multi-turn dialogues. However, it overlooks the influence of these critical factors on agent behavior. To bridge this gap, we present an open-source and high-quality benchmark $C^3$-Bench. This benchmark integrates attack concepts and applies univariate analysis to pinpoint key elements affecting agent robustness. In concrete, we design three challenges: navigate complex tool relationships, handle critical hidden information and manage dynamic decision paths. Complementing these challenges, we introduce fine-grained metrics, innovative data collection algorithms and reproducible evaluation methods. Extensive experiments are conducted on 49 mainstream agents, encompassing general fast-thinking, slow-thinking and domain-specific models. We observe that agents have significant shortcomings in handling tool dependencies, long context information dependencies and frequent policy-type switching. In essence, $C^3$-Bench aims to expose model vulnerabilities through these challenges and drive research into the interpretability of agent performance. The benchmark is publicly available at https://github.com/yupeijei1997/C3-Bench.
LLM-Augmented Chemical Synthesis and Design Decision Programs
May 11, 2025Retrosynthesis, the process of breaking down a target molecule into simpler precursors through a series of valid reactions, stands at the core of organic chemistry and drug development. Although recent machine learning (ML) research has advanced single-step retrosynthetic modeling and subsequent route searches, these solutions remain restricted by the extensive combinatorial space of possible pathways. Concurrently, large language models (LLMs) have exhibited remarkable chemical knowledge, hinting at their potential to tackle complex decision-making tasks in chemistry. In this work, we explore whether LLMs can successfully navigate the highly constrained, multi-step retrosynthesis planning problem. We introduce an efficient scheme for encoding reaction pathways and present a new route-level search strategy, moving beyond the conventional step-by-step reactant prediction. Through comprehensive evaluations, we show that our LLM-augmented approach excels at retrosynthesis planning and extends naturally to the broader challenge of synthesizable molecular design.
Multi-Mission Tool Bench: Assessing the Robustness of LLM based Agents through Related and Dynamic Missions
Apr 03, 2025Large language models (LLMs) demonstrate strong potential as agents for tool invocation due to their advanced comprehension and planning capabilities. Users increasingly rely on LLM-based agents to solve complex missions through iterative interactions. However, existing benchmarks predominantly access agents in single-mission scenarios, failing to capture real-world complexity. To bridge this gap, we propose the Multi-Mission Tool Bench. In the benchmark, each test case comprises multiple interrelated missions. This design requires agents to dynamically adapt to evolving demands. Moreover, the proposed benchmark explores all possible mission-switching patterns within a fixed mission number. Specifically, we propose a multi-agent data generation framework to construct the benchmark. We also propose a novel method to evaluate the accuracy and efficiency of agent decisions with dynamic decision trees. Experiments on diverse open-source and closed-source LLMs reveal critical factors influencing agent robustness and provide actionable insights to the tool invocation society.
Large Language Models Are Innate Crystal Structure Generators
Feb 28, 2025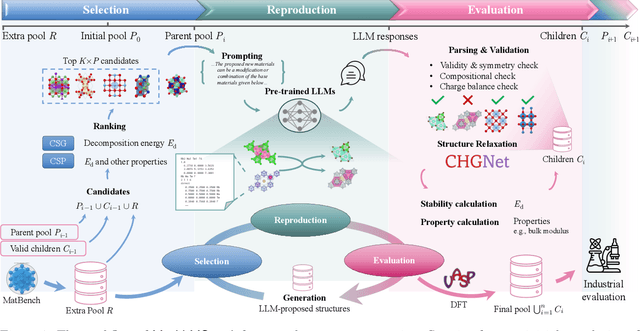
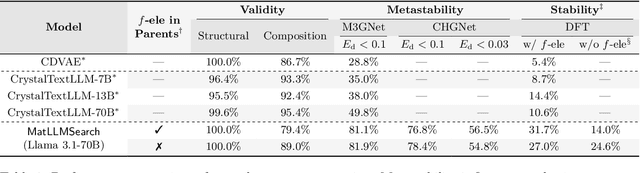
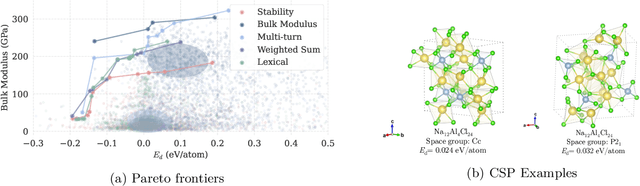
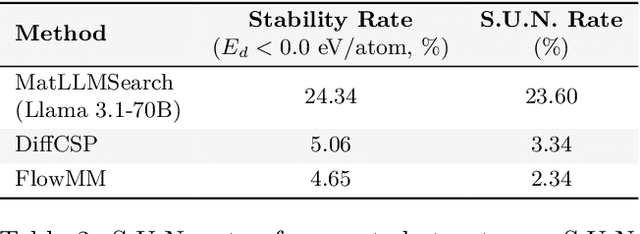
Crystal structure generation is fundamental to materials discovery, enabling the prediction of novel materials with desired properties. While existing approaches leverage Large Language Models (LLMs) through extensive fine-tuning on materials databases, we show that pre-trained LLMs can inherently generate stable crystal structures without additional training. Our novel framework MatLLMSearch integrates pre-trained LLMs with evolutionary search algorithms, achieving a 78.38% metastable rate validated by machine learning interatomic potentials and 31.7% DFT-verified stability via quantum mechanical calculations, outperforming specialized models such as CrystalTextLLM. Beyond crystal structure generation, we further demonstrate that our framework can be readily adapted to diverse materials design tasks, including crystal structure prediction and multi-objective optimization of properties such as deformation energy and bulk modulus, all without fine-tuning. These results establish pre-trained LLMs as versatile and effective tools for materials discovery, opening up new venues for crystal structure generation with reduced computational overhead and broader accessibility.
Efficient Evolutionary Search Over Chemical Space with Large Language Models
Jun 23, 2024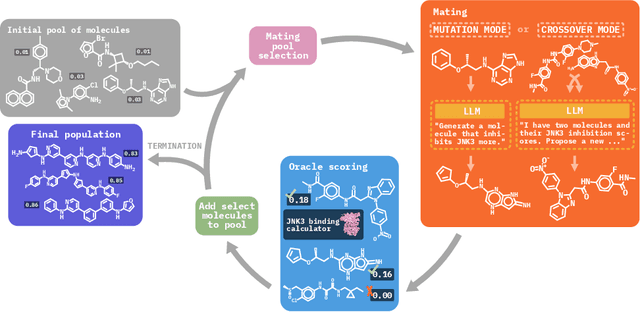
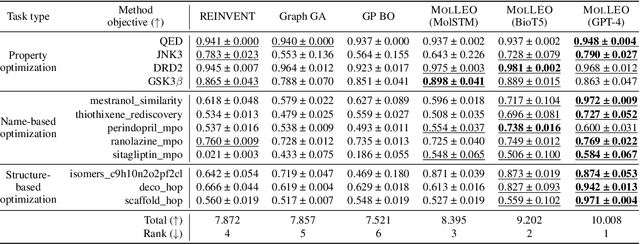
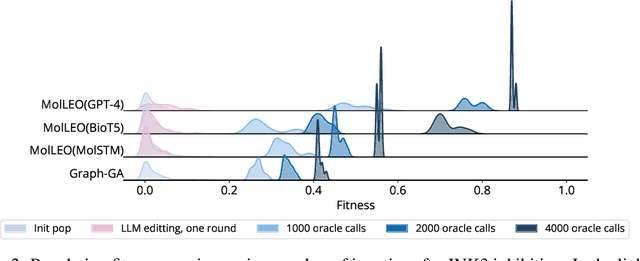
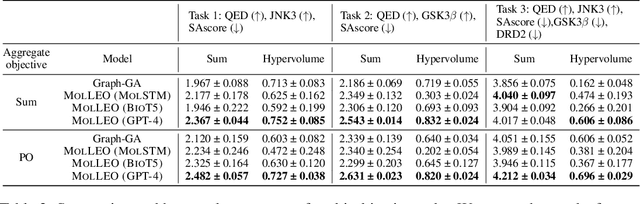
Molecular discovery, when formulated as an optimization problem, presents significant computational challenges because optimization objectives can be non-differentiable. Evolutionary Algorithms (EAs), often used to optimize black-box objectives in molecular discovery, traverse chemical space by performing random mutations and crossovers, leading to a large number of expensive objective evaluations. In this work, we ameliorate this shortcoming by incorporating chemistry-aware Large Language Models (LLMs) into EAs. Namely, we redesign crossover and mutation operations in EAs using LLMs trained on large corpora of chemical information. We perform extensive empirical studies on both commercial and open-source models on multiple tasks involving property optimization, molecular rediscovery, and structure-based drug design, demonstrating that the joint usage of LLMs with EAs yields superior performance over all baseline models across single- and multi-objective settings. We demonstrate that our algorithm improves both the quality of the final solution and convergence speed, thereby reducing the number of required objective evaluations. Our code is available at http://github.com/zoom-wang112358/MOLLEO
PLaD: Preference-based Large Language Model Distillation with Pseudo-Preference Pairs
Jun 06, 2024



Large Language Models (LLMs) have exhibited impressive capabilities in various tasks, yet their vast parameter sizes restrict their applicability in resource-constrained settings. Knowledge distillation (KD) offers a viable solution by transferring expertise from large teacher models to compact student models. However, traditional KD techniques face specific challenges when applied to LLMs, including restricted access to LLM outputs, significant teacher-student capacity gaps, and the inherited mis-calibration issue. In this work, we present PLaD, a novel preference-based LLM distillation framework. PLaD exploits the teacher-student capacity discrepancy to generate pseudo-preference pairs where teacher outputs are preferred over student outputs. Then, PLaD leverages a ranking loss to re-calibrate student's estimation of sequence likelihood, which steers the student's focus towards understanding the relative quality of outputs instead of simply imitating the teacher. PLaD bypasses the need for access to teacher LLM's internal states, tackles the student's expressivity limitations, and mitigates the student mis-calibration issue. Through extensive experiments on two sequence generation tasks and with various LLMs, we demonstrate the effectiveness of our proposed PLaD framework.
Diffusion Models as Constrained Samplers for Optimization with Unknown Constraints
Feb 28, 2024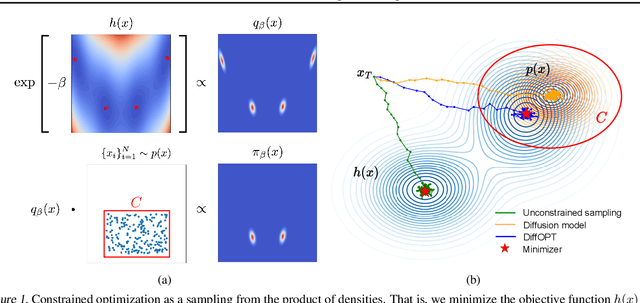
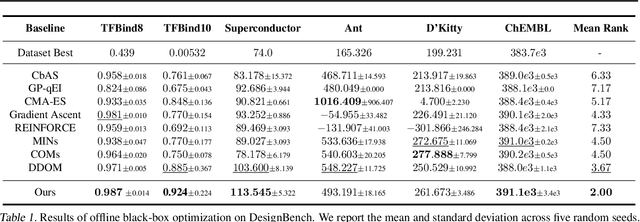
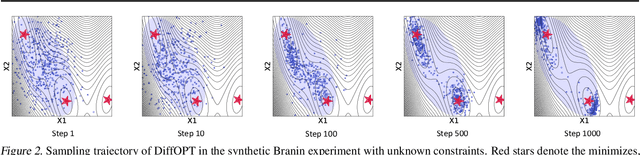
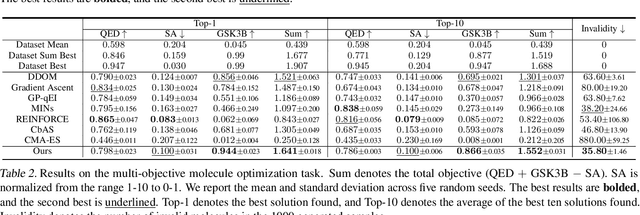
Addressing real-world optimization problems becomes particularly challenging when analytic objective functions or constraints are unavailable. While numerous studies have addressed the issue of unknown objectives, limited research has focused on scenarios where feasibility constraints are not given explicitly. Overlooking these constraints can lead to spurious solutions that are unrealistic in practice. To deal with such unknown constraints, we propose to perform optimization within the data manifold using diffusion models. To constrain the optimization process to the data manifold, we reformulate the original optimization problem as a sampling problem from the product of the Boltzmann distribution defined by the objective function and the data distribution learned by the diffusion model. To enhance sampling efficiency, we propose a two-stage framework that begins with a guided diffusion process for warm-up, followed by a Langevin dynamics stage for further correction. Theoretical analysis shows that the initial stage results in a distribution focused on feasible solutions, thereby providing a better initialization for the later stage. Comprehensive experiments on a synthetic dataset, six real-world black-box optimization datasets, and a multi-objective optimization dataset show that our method achieves better or comparable performance with previous state-of-the-art baselines.
TPD: Enhancing Student Language Model Reasoning via Principle Discovery and Guidance
Jan 24, 2024



Large Language Models (LLMs) have recently showcased remarkable reasoning abilities. However, larger models often surpass their smaller counterparts in reasoning tasks, posing the challenge of effectively transferring these capabilities from larger models. Existing approaches heavily rely on extensive fine-tuning data or continuous interactions with a superior teacher LLM during inference. We introduce a principle-based teacher-student framework called ``Teaching via Principle Discovery'' (TPD) to address these limitations. Inspired by human learning mechanisms, TPD mimics the interaction between a teacher and a student using a principle-based approach. The teacher LLM generates problem-solving instructions and corrective principles based on the student LLM's errors. These principles guide the refinement of instructions and the selection of instructive examples from a validation set. This enables the student model to learn from both the teacher's guidance and its own mistakes. Once the student model begins making inferences, TPD requires no further intervention from the teacher LLM or humans. Through extensive experiments across eight reasoning tasks, we demonstrate the effectiveness of TPD. Compared to standard chain-of-thought prompting, TPD significantly improves the student model's performance, achieving $6.2\%$ improvement on average.
Assessing Logical Puzzle Solving in Large Language Models: Insights from a Minesweeper Case Study
Nov 13, 2023
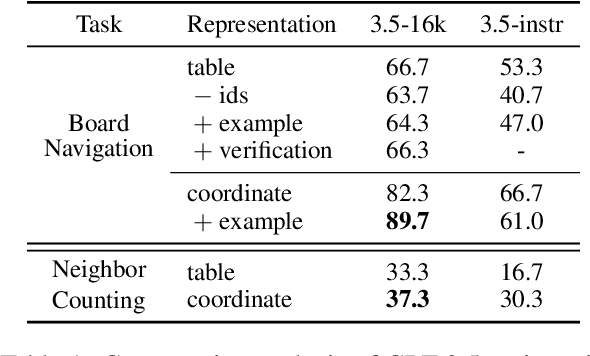
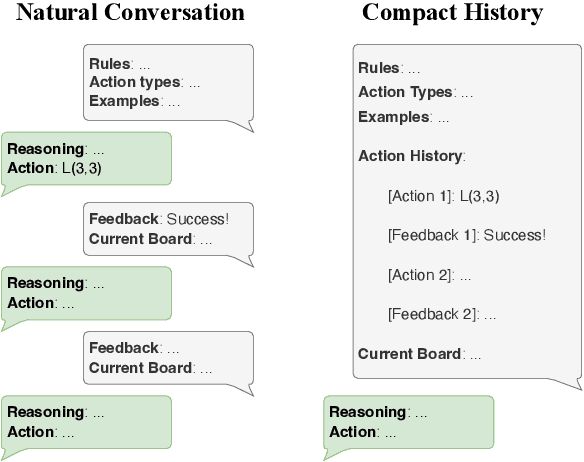
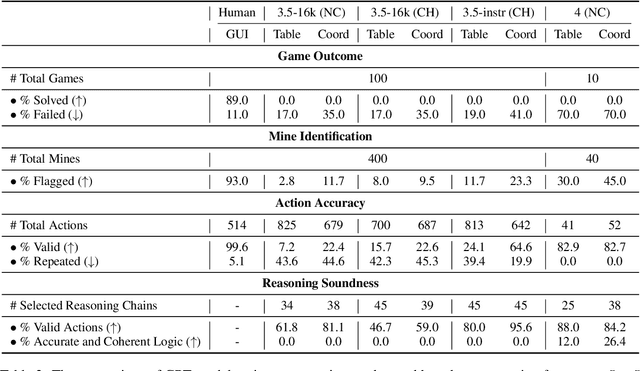
Large Language Models (LLMs) have shown remarkable proficiency in language understanding and have been successfully applied to a variety of real-world tasks through task-specific fine-tuning or prompt engineering. Despite these advancements, it remains an open question whether LLMs are fundamentally capable of reasoning and planning, or if they primarily rely on recalling and synthesizing information from their training data. In our research, we introduce a novel task -- Minesweeper -- specifically designed in a format unfamiliar to LLMs and absent from their training datasets. This task challenges LLMs to identify the locations of mines based on numerical clues provided by adjacent opened cells. Successfully completing this task requires an understanding of each cell's state, discerning spatial relationships between the clues and mines, and strategizing actions based on logical deductions drawn from the arrangement of the cells. Our experiments, including trials with the advanced GPT-4 model, indicate that while LLMs possess the foundational abilities required for this task, they struggle to integrate these into a coherent, multi-step logical reasoning process needed to solve Minesweeper. These findings highlight the need for further research to understand and nature of reasoning capabilities in LLMs under similar circumstances, and to explore pathways towards more sophisticated AI reasoning and planning models.