 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Fine-Grained News Headline Hallucination Detection
Jul 22, 2024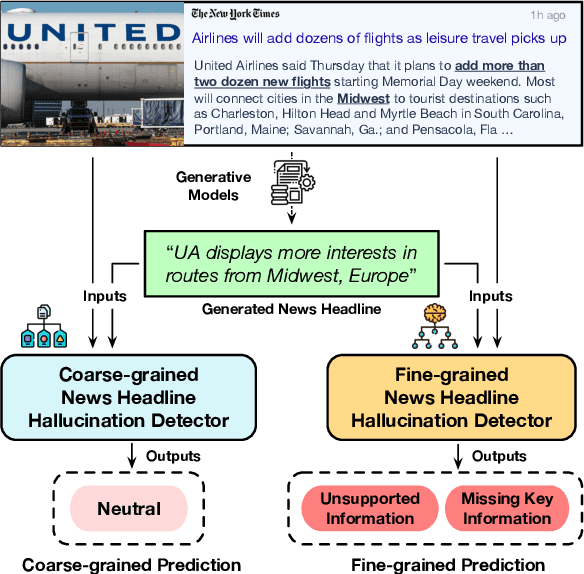
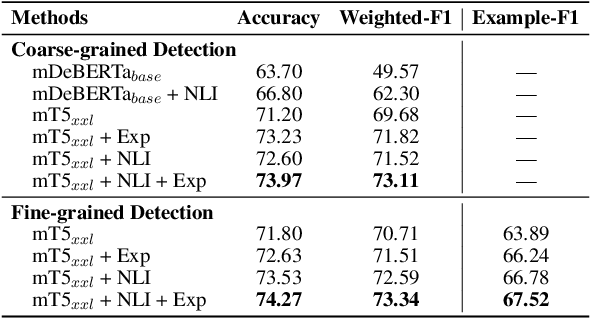
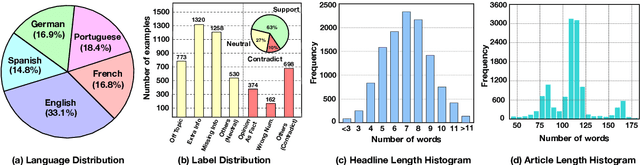
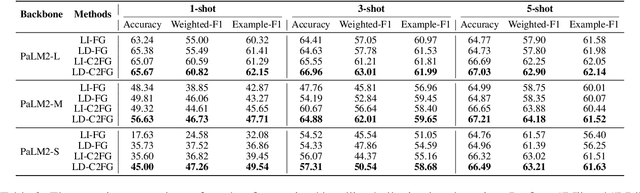
The popularity of automated news headline generation has surged with advancements in pre-trained language models. However, these models often suffer from the ``hallucination'' problem, where the generated headline is not fully supported by its source article. Efforts to address this issue have predominantly focused on English, using over-simplistic classification schemes that overlook nuanced hallucination types. In this study, we introduce the first multilingual, fine-grained news headline hallucination detection dataset that contains over 11 thousand pairs in 5 languages, each annotated with detailed hallucination types by experts. We conduct extensive experiments on this dataset under two settings. First, we implement several supervised fine-tuning approaches as preparatory solutions and demonstrate this dataset's challenges and utilities. Second, we test various large language models' in-context learning abilities and propose two novel techniques, language-dependent demonstration selection and coarse-to-fine prompting, to boost the few-shot hallucination detection performance in terms of the example-F1 metric. We release this dataset to foster further research in multilingual, fine-grained headline hallucination detection.
PLaD: Preference-based Large Language Model Distillation with Pseudo-Preference Pairs
Jun 06, 2024



Large Language Models (LLMs) have exhibited impressive capabilities in various tasks, yet their vast parameter sizes restrict their applicability in resource-constrained settings. Knowledge distillation (KD) offers a viable solution by transferring expertise from large teacher models to compact student models. However, traditional KD techniques face specific challenges when applied to LLMs, including restricted access to LLM outputs, significant teacher-student capacity gaps, and the inherited mis-calibration issue. In this work, we present PLaD, a novel preference-based LLM distillation framework. PLaD exploits the teacher-student capacity discrepancy to generate pseudo-preference pairs where teacher outputs are preferred over student outputs. Then, PLaD leverages a ranking loss to re-calibrate student's estimation of sequence likelihood, which steers the student's focus towards understanding the relative quality of outputs instead of simply imitating the teacher. PLaD bypasses the need for access to teacher LLM's internal states, tackles the student's expressivity limitations, and mitigates the student mis-calibration issue. Through extensive experiments on two sequence generation tasks and with various LLMs, we demonstrate the effectiveness of our proposed PLaD framework.
LiPO: Listwise Preference Optimization through Learning-to-Rank
Feb 02, 2024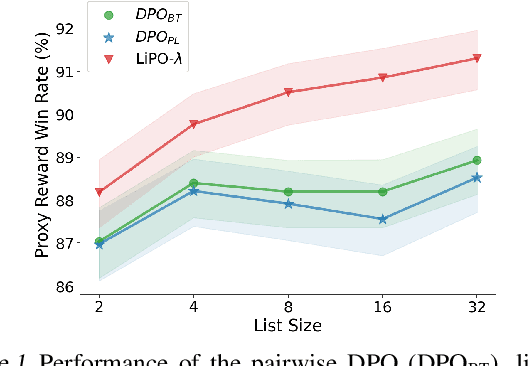



Aligning language models (LMs) with curated human feedback is critical to control their behaviors in real-world applications. Several recent policy optimization methods, such as DPO and SLiC, serve as promising alternatives to the traditional Reinforcement Learning from Human Feedback (RLHF) approach. In practice, human feedback often comes in a format of a ranked list over multiple responses to amortize the cost of reading prompt. Multiple responses can also be ranked by reward models or AI feedback. There lacks such a study on directly fitting upon a list of responses. In this work, we formulate the LM alignment as a listwise ranking problem and describe the Listwise Preference Optimization (LiPO) framework, where the policy can potentially learn more effectively from a ranked list of plausible responses given the prompt. This view draws an explicit connection to Learning-to-Rank (LTR), where most existing preference optimization work can be mapped to existing ranking objectives, especially pairwise ones. Following this connection, we provide an examination of ranking objectives that are not well studied for LM alignment withDPO and SLiC as special cases when list size is two. In particular, we highlight a specific method, LiPO-{\lambda}, which leverages a state-of-the-art listwise ranking objective and weights each preference pair in a more advanced manner. We show that LiPO-{\lambda} can outperform DPO and SLiC by a clear margin on two preference alignment tasks.
Benchmarking the CoW with the TopCoW Challenge: Topology-Aware Anatomical Segmentation of the Circle of Willis for CTA and MRA
Dec 29, 2023



The Circle of Willis (CoW) is an important network of arteries connecting major circulations of the brain. Its vascular architecture is believed to affect the risk, severity, and clinical outcome of serious neuro-vascular diseases. However, characterizing the highly variable CoW anatomy is still a manual and time-consuming expert task. The CoW is usually imaged by two angiographic imaging modalities, magnetic resonance angiography (MRA) and computed tomography angiography (CTA), but there exist limited public datasets with annotations on CoW anatomy, especially for CTA. Therefore we organized the TopCoW Challenge in 2023 with the release of an annotated CoW dataset and invited submissions worldwide for the CoW segmentation task, which attracted over 140 registered participants from four continents. TopCoW dataset was the first public dataset with voxel-level annotations for CoW's 13 vessel components, made possible by virtual-reality (VR) technology. It was also the first dataset with paired MRA and CTA from the same patients. TopCoW challenge aimed to tackle the CoW characterization problem as a multiclass anatomical segmentation task with an emphasis on topological metrics. The top performing teams managed to segment many CoW components to Dice scores around 90%, but with lower scores for communicating arteries and rare variants. There were also topological mistakes for predictions with high Dice scores. Additional topological analysis revealed further areas for improvement in detecting certain CoW components and matching CoW variant's topology accurately. TopCoW represented a first attempt at benchmarking the CoW anatomical segmentation task for MRA and CTA, both morphologically and topologically.
Video Summarization: Towards Entity-Aware Captions
Dec 01, 2023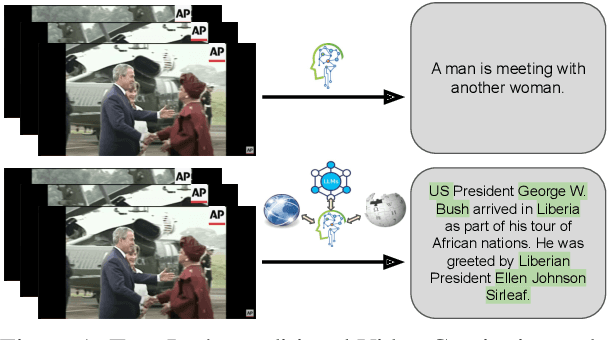
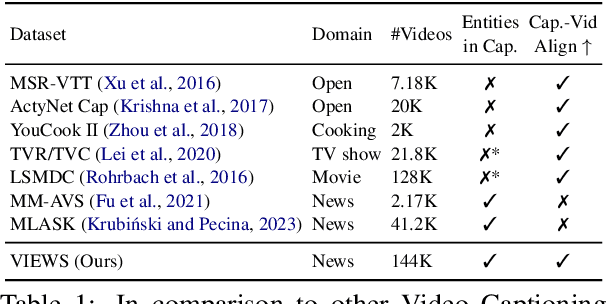
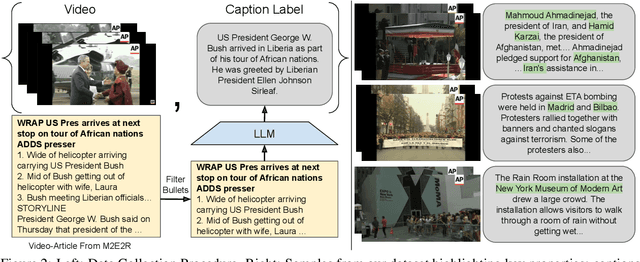
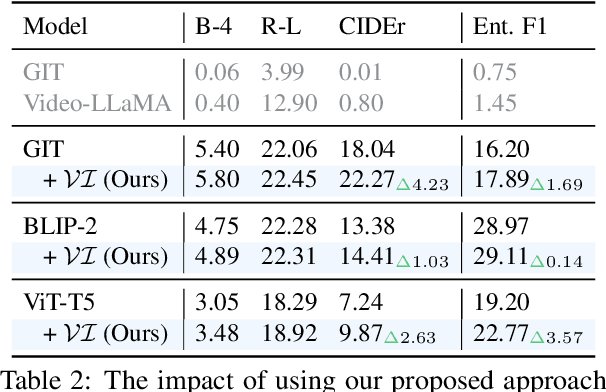
Existing popular video captioning benchmarks and models deal with generic captions devoid of specific person, place or organization named entities. In contrast, news videos present a challenging setting where the caption requires such named entities for meaningful summarization. As such, we propose the task of summarizing news video directly to entity-aware captions. We also release a large-scale dataset, VIEWS (VIdeo NEWS), to support research on this task. Further, we propose a method that augments visual information from videos with context retrieved from external world knowledge to generate entity-aware captions. We demonstrate the effectiveness of our approach on three video captioning models. We also show that our approach generalizes to existing news image captions dataset. With all the extensive experiments and insights, we believe we establish a solid basis for future research on this challenging task.
On What Basis? Predicting Text Preference Via Structured Comparative Reasoning
Nov 14, 2023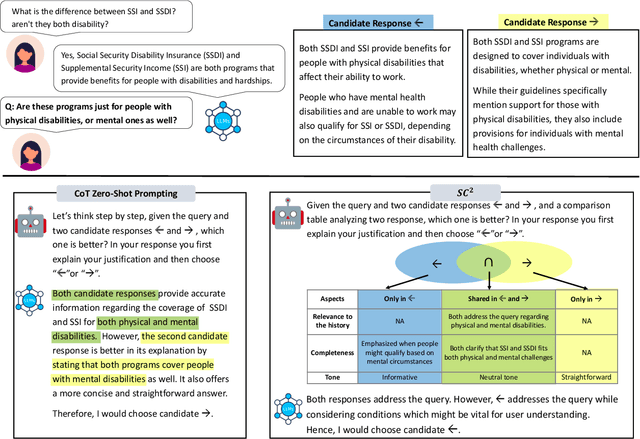

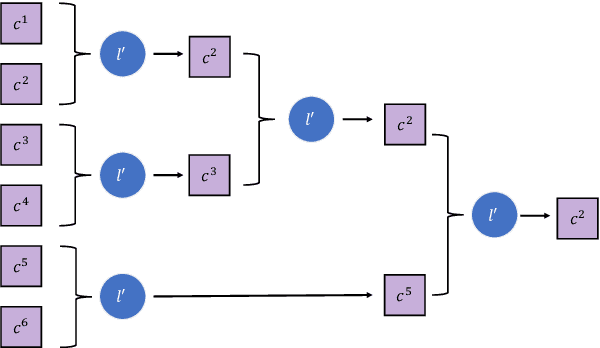
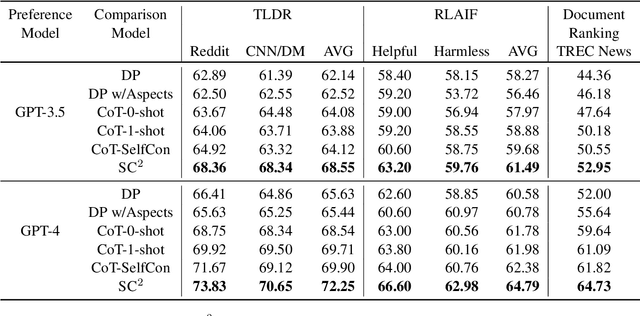
Comparative reasoning plays a crucial role in text preference prediction; however, large language models (LLMs) often demonstrate inconsistencies in their reasoning. While approaches like Chain-of-Thought improve accuracy in many other settings, they struggle to consistently distinguish the similarities and differences of complex texts. We introduce SC, a prompting approach that predicts text preferences by generating structured intermediate comparisons. SC begins by proposing aspects of comparison, followed by generating textual comparisons under each aspect. We select consistent comparisons with a pairwise consistency comparator that ensures each aspect's comparisons clearly distinguish differences between texts, significantly reducing hallucination and improving consistency. Our comprehensive evaluations across various NLP tasks, including summarization, retrieval, and automatic rating, demonstrate that SC equips LLMs to achieve state-of-the-art performance in text preference prediction.
Explanation-aware Soft Ensemble Empowers Large Language Model In-context Learning
Nov 13, 2023Large language models (LLMs) have shown remarkable capabilities in various natural language understanding tasks. With only a few demonstration examples, these LLMs can quickly adapt to target tasks without expensive gradient updates. Common strategies to boost such 'in-context' learning ability are to ensemble multiple model decoded results and require the model to generate an explanation along with the prediction. However, these models often treat different class predictions equally and neglect the potential discrepancy between the explanations and predictions. To fully unleash the power of explanations, we propose EASE, an Explanation-Aware Soft Ensemble framework to empower in-context learning with LLMs. We design two techniques, explanation-guided ensemble, and soft probability aggregation, to mitigate the effect of unreliable explanations and improve the consistency between explanations and final predictions. Experiments on seven natural language understanding tasks and four varying-size LLMs demonstrate the effectiveness of our proposed framework.
Video Timeline Modeling For News Story Understanding
Sep 23, 2023



In this paper, we present a novel problem, namely video timeline modeling. Our objective is to create a video-associated timeline from a set of videos related to a specific topic, thereby facilitating the content and structure understanding of the story being told. This problem has significant potential in various real-world applications, such as news story summarization. To bootstrap research in this area, we curate a realistic benchmark dataset, YouTube-News-Timeline, consisting of over $12$k timelines and $300$k YouTube news videos. Additionally, we propose a set of quantitative metrics as the protocol to comprehensively evaluate and compare methodologies. With such a testbed, we further develop and benchmark exploratory deep learning approaches to tackle this problem. We anticipate that this exploratory work will pave the way for further research in video timeline modeling. The assets are available via https://github.com/google-research/google-research/tree/master/video_timeline_modeling.
Statistical Rejection Sampling Improves Preference Optimization
Sep 13, 2023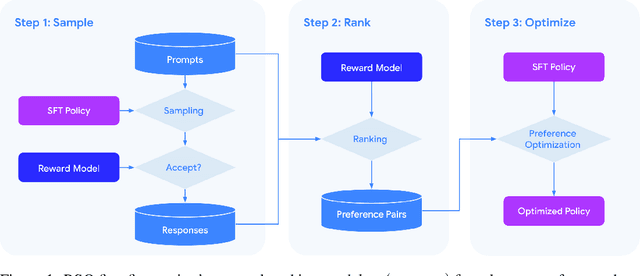
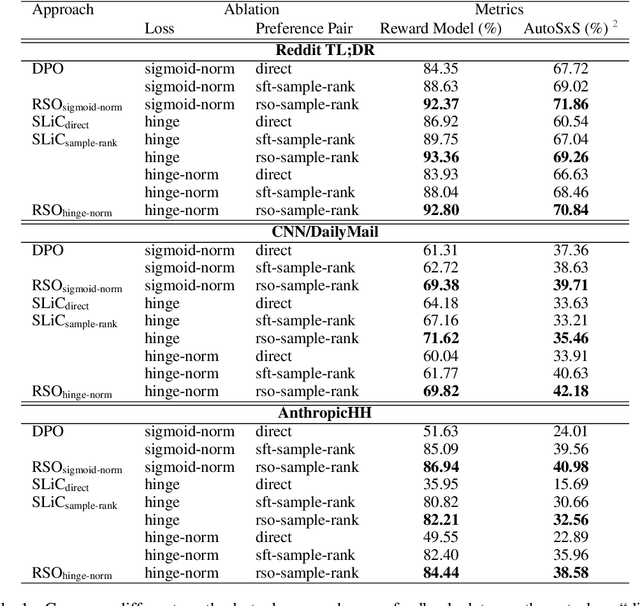

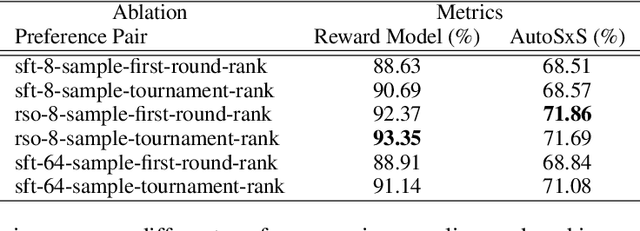
Improving the alignment of language models with human preferences remains an active research challenge. Previous approaches have primarily utilized Reinforcement Learning from Human Feedback (RLHF) via online RL methods such as Proximal Policy Optimization (PPO). Recently, offline methods such as Sequence Likelihood Calibration (SLiC) and Direct Preference Optimization (DPO) have emerged as attractive alternatives, offering improvements in stability and scalability while maintaining competitive performance. SLiC refines its loss function using sequence pairs sampled from a supervised fine-tuned (SFT) policy, while DPO directly optimizes language models based on preference data, foregoing the need for a separate reward model. However, the maximum likelihood estimator (MLE) of the target optimal policy requires labeled preference pairs sampled from that policy. DPO's lack of a reward model constrains its ability to sample preference pairs from the optimal policy, and SLiC is restricted to sampling preference pairs only from the SFT policy. To address these limitations, we introduce a novel approach called Statistical Rejection Sampling Optimization (RSO) that aims to source preference data from the target optimal policy using rejection sampling, enabling a more accurate estimation of the optimal policy. We also propose a unified framework that enhances the loss functions used in both SLiC and DPO from a preference modeling standpoint. Through extensive experiments across three diverse tasks, we demonstrate that RSO consistently outperforms both SLiC and DPO on evaluations from both Large Language Model (LLM) and human raters.
Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting
Jun 30, 2023



Ranking documents using Large Language Models (LLMs) by directly feeding the query and candidate documents into the prompt is an interesting and practical problem. However, there has been limited success so far, as researchers have found it difficult to outperform fine-tuned baseline rankers on benchmark datasets. We analyze pointwise and listwise ranking prompts used by existing methods and argue that off-the-shelf LLMs do not fully understand these ranking formulations, possibly due to the nature of how LLMs are trained. In this paper, we propose to significantly reduce the burden on LLMs by using a new technique called Pairwise Ranking Prompting (PRP). Our results are the first in the literature to achieve state-of-the-art ranking performance on standard benchmarks using moderate-sized open-sourced LLMs. On TREC-DL2020, PRP based on the Flan-UL2 model with 20B parameters outperforms the previous best approach in the literature, which is based on the blackbox commercial GPT-4 that has 50x (estimated) model size, by over 5% at NDCG@1. On TREC-DL2019, PRP is only inferior to the GPT-4 solution on the NDCG@5 and NDCG@10 metrics, while outperforming other existing solutions, such as InstructGPT which has 175B parameters, by over 10% for nearly all ranking metrics. Furthermore, we propose several variants of PRP to improve efficiency and show that it is possible to achieve competitive results even with linear complexity. We also discuss other benefits of PRP, such as supporting both generation and scoring LLM APIs, as well as being insensitive to input ordering.