 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Summarization: Towards Entity-Aware Captions
Paper and Code
Dec 01, 2023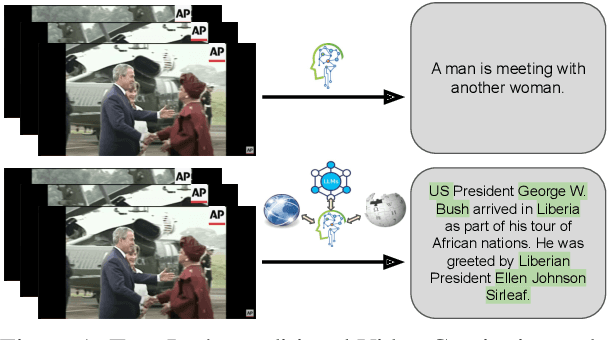
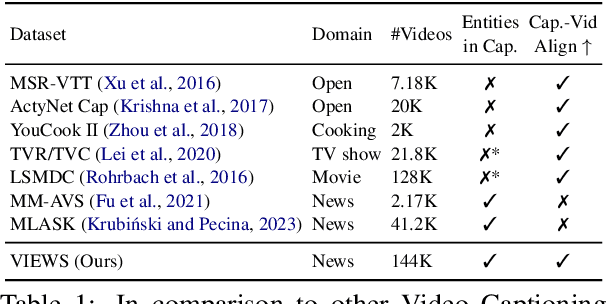
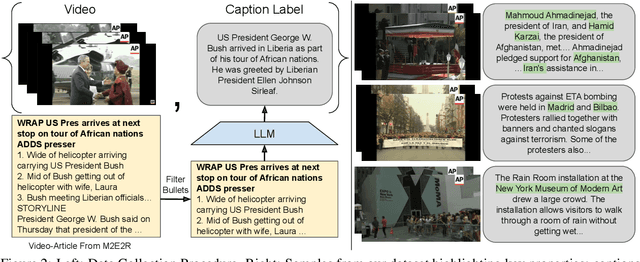
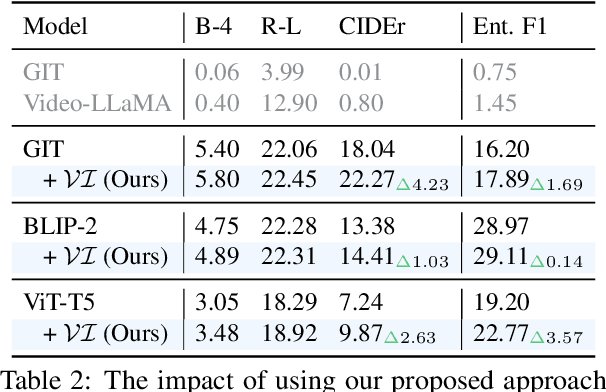
Existing popular video captioning benchmarks and models deal with generic captions devoid of specific person, place or organization named entities. In contrast, news videos present a challenging setting where the caption requires such named entities for meaningful summarization. As such, we propose the task of summarizing news video directly to entity-aware captions. We also release a large-scale dataset, VIEWS (VIdeo NEWS), to support research on this task. Further, we propose a method that augments visual information from videos with context retrieved from external world knowledge to generate entity-aware captions. We demonstrate the effectiveness of our approach on three video captioning models. We also show that our approach generalizes to existing news image captions dataset. With all the extensive experiments and insights, we believe we establish a solid basis for future research on this challenging task.