 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStandardized Evaluation of Automatic Methods for Perivascular Spaces Segmentation in MRI -- MICCAI 2024 Challenge Results
Dec 20, 2025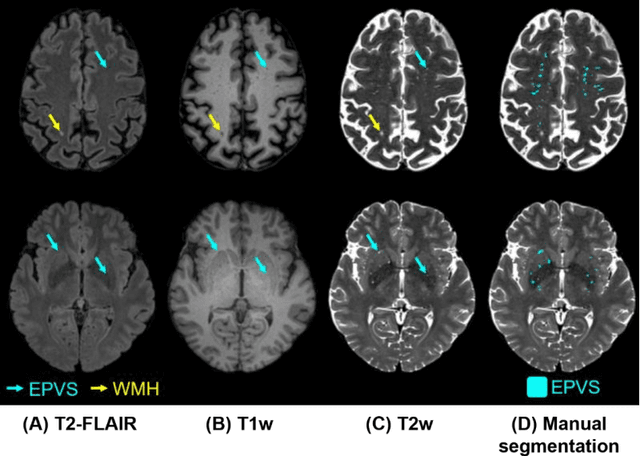
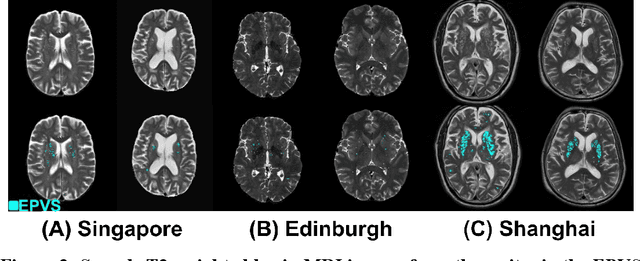
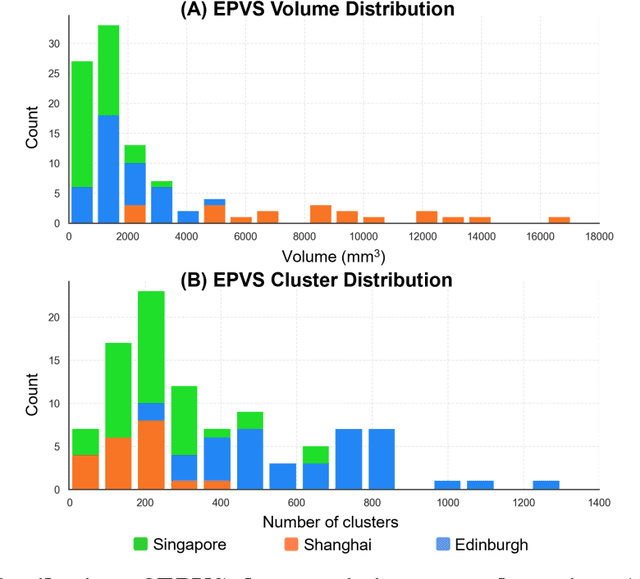
Perivascular spaces (PVS), when abnormally enlarged and visible in magnetic resonance imaging (MRI) structural sequences, are important imaging markers of cerebral small vessel disease and potential indicators of neurodegenerative conditions. Despite their clinical significance, automatic enlarged PVS (EPVS) segmentation remains challenging due to their small size, variable morphology, similarity with other pathological features, and limited annotated datasets. This paper presents the EPVS Challenge organized at MICCAI 2024, which aims to advance the development of automated algorithms for EPVS segmentation across multi-site data. We provided a diverse dataset comprising 100 training, 50 validation, and 50 testing scans collected from multiple international sites (UK, Singapore, and China) with varying MRI protocols and demographics. All annotations followed the STRIVE protocol to ensure standardized ground truth and covered the full brain parenchyma. Seven teams completed the full challenge, implementing various deep learning approaches primarily based on U-Net architectures with innovations in multi-modal processing, ensemble strategies, and transformer-based components. Performance was evaluated using dice similarity coefficient, absolute volume difference, recall, and precision metrics. The winning method employed MedNeXt architecture with a dual 2D/3D strategy for handling varying slice thicknesses. The top solutions showed relatively good performance on test data from seen datasets, but significant degradation of performance was observed on the previously unseen Shanghai cohort, highlighting cross-site generalization challenges due to domain shift. This challenge establishes an important benchmark for EPVS segmentation methods and underscores the need for the continued development of robust algorithms that can generalize in diverse clinical settings.
Template-Guided Reconstruction of Pulmonary Segments with Neural Implicit Functions
May 13, 2025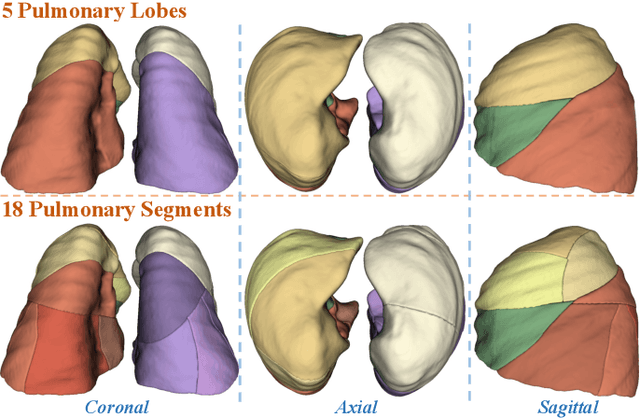
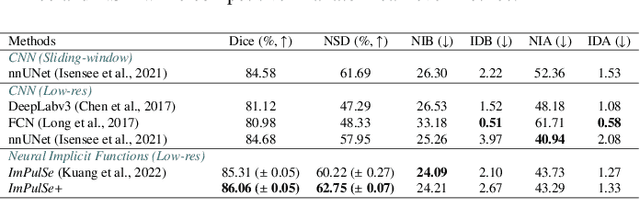
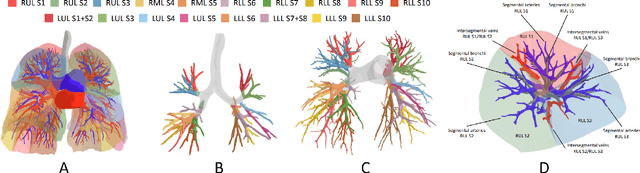
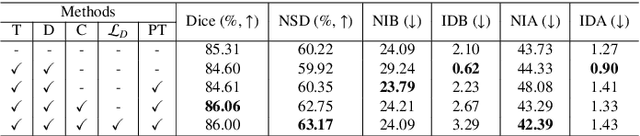
High-quality 3D reconstruction of pulmonary segments plays a crucial role in segmentectomy and surgical treatment planning for lung cancer. Due to the resolution requirement of the target reconstruction, conventional deep learning-based methods often suffer from computational resource constraints or limited granularity. Conversely, implicit modeling is favored due to its computational efficiency and continuous representation at any resolution. We propose a neural implicit function-based method to learn a 3D surface to achieve anatomy-aware, precise pulmonary segment reconstruction, represented as a shape by deforming a learnable template. Additionally, we introduce two clinically relevant evaluation metrics to assess the reconstruction comprehensively. Further, due to the absence of publicly available shape datasets to benchmark reconstruction algorithms, we developed a shape dataset named Lung3D, including the 3D models of 800 labeled pulmonary segments and the corresponding airways, arteries, veins, and intersegmental veins. We demonstrate that the proposed approach outperforms existing methods, providing a new perspective for pulmonary segment reconstruction. Code and data will be available at https://github.com/M3DV/ImPulSe.
Advances in Automated Fetal Brain MRI Segmentation and Biometry: Insights from the FeTA 2024 Challenge
May 05, 2025



Accurate fetal brain tissue segmentation and biometric analysis are essential for studying brain development in utero. The FeTA Challenge 2024 advanced automated fetal brain MRI analysis by introducing biometry prediction as a new task alongside tissue segmentation. For the first time, our diverse multi-centric test set included data from a new low-field (0.55T) MRI dataset. Evaluation metrics were also expanded to include the topology-specific Euler characteristic difference (ED). Sixteen teams submitted segmentation methods, most of which performed consistently across both high- and low-field scans. However, longitudinal trends indicate that segmentation accuracy may be reaching a plateau, with results now approaching inter-rater variability. The ED metric uncovered topological differences that were missed by conventional metrics, while the low-field dataset achieved the highest segmentation scores, highlighting the potential of affordable imaging systems when paired with high-quality reconstruction. Seven teams participated in the biometry task, but most methods failed to outperform a simple baseline that predicted measurements based solely on gestational age, underscoring the challenge of extracting reliable biometric estimates from image data alone. Domain shift analysis identified image quality as the most significant factor affecting model generalization, with super-resolution pipelines also playing a substantial role. Other factors, such as gestational age, pathology, and acquisition site, had smaller, though still measurable, effects. Overall, FeTA 2024 offers a comprehensive benchmark for multi-class segmentation and biometry estimation in fetal brain MRI, underscoring the need for data-centric approaches, improved topological evaluation, and greater dataset diversity to enable clinically robust and generalizable AI tools.
Analysis of the MICCAI Brain Tumor Segmentation -- Metastases (BraTS-METS) 2025 Lighthouse Challenge: Brain Metastasis Segmentation on Pre- and Post-treatment MRI
Apr 16, 2025Despite continuous advancements in cancer treatment, brain metastatic disease remains a significant complication of primary cancer and is associated with an unfavorable prognosis. One approach for improving diagnosis, management, and outcomes is to implement algorithms based on artificial intelligence for the automated segmentation of both pre- and post-treatment MRI brain images. Such algorithms rely on volumetric criteria for lesion identification and treatment response assessment, which are still not available in clinical practice. Therefore, it is critical to establish tools for rapid volumetric segmentations methods that can be translated to clinical practice and that are trained on high quality annotated data. The BraTS-METS 2025 Lighthouse Challenge aims to address this critical need by establishing inter-rater and intra-rater variability in dataset annotation by generating high quality annotated datasets from four individual instances of segmentation by neuroradiologists while being recorded on video (two instances doing "from scratch" and two instances after AI pre-segmentation). This high-quality annotated dataset will be used for testing phase in 2025 Lighthouse challenge and will be publicly released at the completion of the challenge. The 2025 Lighthouse challenge will also release the 2023 and 2024 segmented datasets that were annotated using an established pipeline of pre-segmentation, student annotation, two neuroradiologists checking, and one neuroradiologist finalizing the process. It builds upon its previous edition by including post-treatment cases in the dataset. Using these high-quality annotated datasets, the 2025 Lighthouse challenge plans to test benchmark algorithms for automated segmentation of pre-and post-treatment brain metastases (BM), trained on diverse and multi-institutional datasets of MRI images obtained from patients with brain metastases.
MedVLM-R1: Incentivizing Medical Reasoning Capability of Vision-Language Models (VLMs) via Reinforcement Learning
Feb 26, 2025
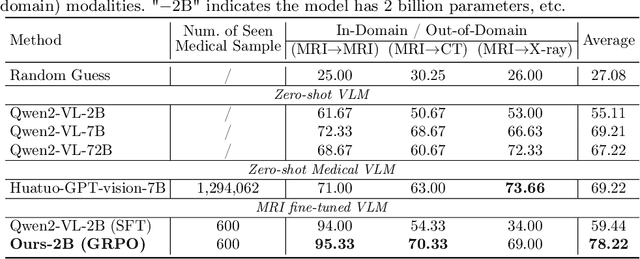
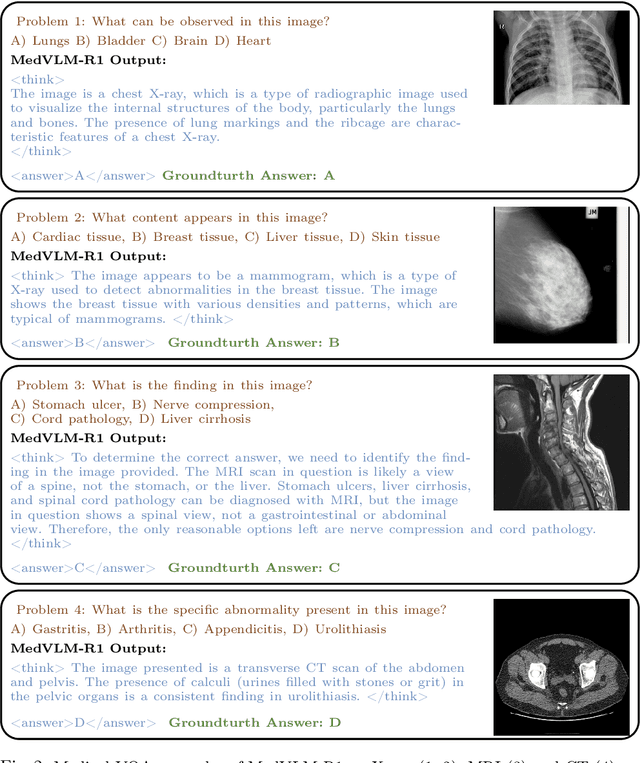
Reasoning is a critical frontier for advancing medical image analysis, where transparency and trustworthiness play a central role in both clinician trust and regulatory approval. Although Medical Visual Language Models (VLMs) show promise for radiological tasks, most existing VLMs merely produce final answers without revealing the underlying reasoning. To address this gap, we introduce MedVLM-R1, a medical VLM that explicitly generates natural language reasoning to enhance transparency and trustworthiness. Instead of relying on supervised fine-tuning (SFT), which often suffers from overfitting to training distributions and fails to foster genuine reasoning, MedVLM-R1 employs a reinforcement learning framework that incentivizes the model to discover human-interpretable reasoning paths without using any reasoning references. Despite limited training data (600 visual question answering samples) and model parameters (2B), MedVLM-R1 boosts accuracy from 55.11% to 78.22% across MRI, CT, and X-ray benchmarks, outperforming larger models trained on over a million samples. It also demonstrates robust domain generalization under out-of-distribution tasks. By unifying medical image analysis with explicit reasoning, MedVLM-R1 marks a pivotal step toward trustworthy and interpretable AI in clinical practice.
TV-based Deep 3D Self Super-Resolution for fMRI
Oct 05, 2024



While functional Magnetic Resonance Imaging (fMRI) offers valuable insights into cognitive processes, its inherent spatial limitations pose challenges for detailed analysis of the fine-grained functional architecture of the brain. More specifically, MRI scanner and sequence specifications impose a trade-off between temporal resolution, spatial resolution, signal-to-noise ratio, and scan time. Deep Learning (DL) Super-Resolution (SR) methods have emerged as a promising solution to enhance fMRI resolution, generating high-resolution (HR) images from low-resolution (LR) images typically acquired with lower scanning times. However, most existing SR approaches depend on supervised DL techniques, which require training ground truth (GT) HR data, which is often difficult to acquire and simultaneously sets a bound for how far SR can go. In this paper, we introduce a novel self-supervised DL SR model that combines a DL network with an analytical approach and Total Variation (TV) regularization. Our method eliminates the need for external GT images, achieving competitive performance compared to supervised DL techniques and preserving the functional maps.
Learning Brain Tumor Representation in 3D High-Resolution MR Images via Interpretable State Space Models
Sep 12, 2024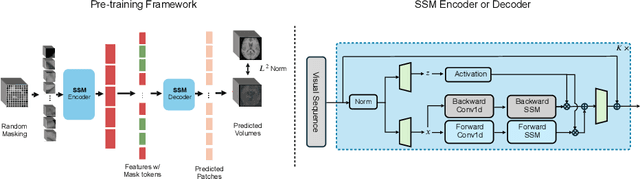


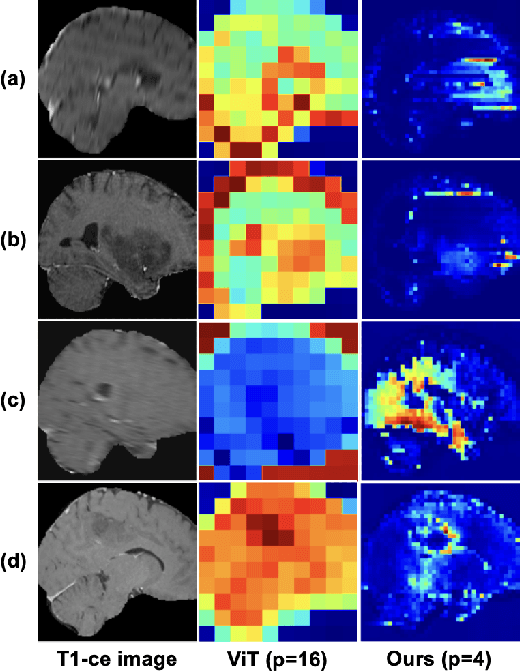
Learning meaningful and interpretable representations from high-dimensional volumetric magnetic resonance (MR) images is essential for advancing personalized medicine. While Vision Transformers (ViTs) have shown promise in handling image data, their application to 3D multi-contrast MR images faces challenges due to computational complexity and interpretability. To address this, we propose a novel state-space-model (SSM)-based masked autoencoder which scales ViT-like models to handle high-resolution data effectively while also enhancing the interpretability of learned representations. We propose a latent-to-spatial mapping technique that enables direct visualization of how latent features correspond to specific regions in the input volumes in the context of SSM. We validate our method on two key neuro-oncology tasks: identification of isocitrate dehydrogenase mutation status and 1p/19q co-deletion classification, achieving state-of-the-art accuracy. Our results highlight the potential of SSM-based self-supervised learning to transform radiomics analysis by combining efficiency and interpretability.
3D Vessel Graph Generation Using Denoising Diffusion
Jul 08, 2024



Blood vessel networks, represented as 3D graphs, help predict disease biomarkers, simulate blood flow, and aid in synthetic image generation, relevant in both clinical and pre-clinical settings. However, generating realistic vessel graphs that correspond to an anatomy of interest is challenging. Previous methods aimed at generating vessel trees mostly in an autoregressive style and could not be applied to vessel graphs with cycles such as capillaries or specific anatomical structures such as the Circle of Willis. Addressing this gap, we introduce the first application of \textit{denoising diffusion models} in 3D vessel graph generation. Our contributions include a novel, two-stage generation method that sequentially denoises node coordinates and edges. We experiment with two real-world vessel datasets, consisting of microscopic capillaries and major cerebral vessels, and demonstrate the generalizability of our method for producing diverse, novel, and anatomically plausible vessel graphs.
Brain Tumor Segmentation (BraTS) Challenge 2024: Meningioma Radiotherapy Planning Automated Segmentation
May 28, 2024The 2024 Brain Tumor Segmentation Meningioma Radiotherapy (BraTS-MEN-RT) challenge aims to advance automated segmentation algorithms using the largest known multi-institutional dataset of radiotherapy planning brain MRIs with expert-annotated target labels for patients with intact or post-operative meningioma that underwent either conventional external beam radiotherapy or stereotactic radiosurgery. Each case includes a defaced 3D post-contrast T1-weighted radiotherapy planning MRI in its native acquisition space, accompanied by a single-label "target volume" representing the gross tumor volume (GTV) and any at-risk post-operative site. Target volume annotations adhere to established radiotherapy planning protocols, ensuring consistency across cases and institutions. For pre-operative meningiomas, the target volume encompasses the entire GTV and associated nodular dural tail, while for post-operative cases, it includes at-risk resection cavity margins as determined by the treating institution. Case annotations were reviewed and approved by expert neuroradiologists and radiation oncologists. Participating teams will develop, containerize, and evaluate automated segmentation models using this comprehensive dataset. Model performance will be assessed using the lesion-wise Dice Similarity Coefficient and the 95% Hausdorff distance. The top-performing teams will be recognized at the Medical Image Computing and Computer Assisted Intervention Conference in October 2024. BraTS-MEN-RT is expected to significantly advance automated radiotherapy planning by enabling precise tumor segmentation and facilitating tailored treatment, ultimately improving patient outcomes.
Probabilistic Contrastive Learning with Explicit Concentration on the Hypersphere
May 26, 2024Self-supervised contrastive learning has predominantly adopted deterministic methods, which are not suited for environments characterized by uncertainty and noise. This paper introduces a new perspective on incorporating uncertainty into contrastive learning by embedding representations within a spherical space, inspired by the von Mises-Fisher distribution (vMF). We introduce an unnormalized form of vMF and leverage the concentration parameter, kappa, as a direct, interpretable measure to quantify uncertainty explicitly. This approach not only provides a probabilistic interpretation of the embedding space but also offers a method to calibrate model confidence against varying levels of data corruption and characteristics. Our empirical results demonstrate that the estimated concentration parameter correlates strongly with the degree of unforeseen data corruption encountered at test time, enables failure analysis, and enhances existing out-of-distribution detection methods.